弱监督语义分割的图像间Token关系学习
IF 3.1
4区 计算机科学
Q2 COMPUTER SCIENCE, INFORMATION SYSTEMS
Journal of Visual Communication and Image Representation
Pub Date : 2025-09-22
DOI:10.1016/j.jvcir.2025.104576
引用次数: 0
摘要
近年来,基于视觉变换的方法已成为弱监督语义分割任务中定位语义对象的一种很有前途的方法。然而,现有的方法主要依靠注意力机制来建立类与图像patch之间的关系,往往忽略了数据集中token之间的内在相互关系。为了解决这一差距,我们提出了图像间令牌关系学习(ITRL)框架,该框架通过图像间一致性推进弱监督语义分割。具体而言,引入了图像间类令牌对比方法,通过在内存库中对比类令牌来生成全面的类表示。此外,提出了图像间补丁令牌对齐方法,增强了补丁令牌之间的规范化互信息,从而增强了它们之间的相互依赖性。大量的实验验证了所提出的框架,展示了PASCAL VOC 2012和MS COCO 2014数据集上Union分数的竞争平均交叉点。本文章由计算机程序翻译,如有差异,请以英文原文为准。
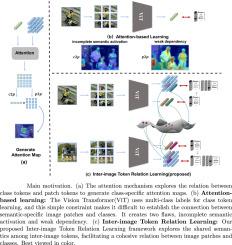
Inter-image Token Relation Learning for weakly supervised semantic segmentation
In recent years, Vision Transformer-based methods have emerged as promising approaches for localizing semantic objects in weakly supervised semantic segmentation tasks. However, existing methods primarily rely on the attention mechanism to establish relations between classes and image patches, often neglecting the intrinsic interrelations among tokens within datasets. To address this gap, we propose the Inter-image Token Relation Learning (ITRL) framework, which advances weakly supervised semantic segmentation by inter-image consistency. Specifically, the Inter-image Class Token Contrast method is introduced to generate comprehensive class representations by contrasting class tokens in a memory bank manner. Additionally, the Inter-image Patch Token Align approach is presented, which enhances the normalized mutual information among patch tokens, thereby strengthening their interdependencies. Extensive experiments validated the proposed framework, showcasing competitive mean Intersection over Union scores on the PASCAL VOC 2012 and MS COCO 2014 datasets.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Journal of Visual Communication and Image Representation
工程技术-计算机:软件工程
CiteScore
5.40
自引率
11.50%
发文量
188
审稿时长
9.9 months
期刊介绍:
The Journal of Visual Communication and Image Representation publishes papers on state-of-the-art visual communication and image representation, with emphasis on novel technologies and theoretical work in this multidisciplinary area of pure and applied research. The field of visual communication and image representation is considered in its broadest sense and covers both digital and analog aspects as well as processing and communication in biological visual systems.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


