使用增强双采样器的连续端到端语音到文本翻译
IF 3.4
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
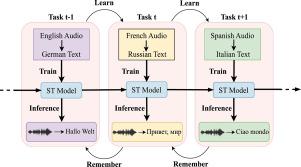
语音到文本(ST)是将一种语言的语音翻译成另一种语言的文本。早期的ST模型使用了结合自动语音识别(ASR)和机器翻译(MT)的管道方法。这种模型受到级联错误传播、高延迟和内存消耗的影响。因此,提出了端到端(E2E) ST模型。将E2E - ST模型应用于新的语言对,会导致在先前训练过的语言对上的性能下降。这种现象被称为灾难性遗忘(CF)。因此,我们需要能够持续学习的ST模型。本工作提出了一个新的持续学习(CL)框架的E2E ST任务。我们的方法背后的核心思想结合了比例语言抽样(PLS)、随机抽样(RS)和增强。RS通过积极地从当前任务中抽样来帮助更好地完成当前任务。PLS从过去的任务数据中取等比例的样本,但可能导致过拟合。为了减轻这种情况,使用了PLS+RS的组合方法,称为连续双采样器(CBS)。然而,由于来自过去任务的重复样本,CBS仍然存在过拟合的问题。因此,我们将各种增强策略与CBS相结合,我们称之为连续增强双采样器(CABS)。我们在4个语言对的MuST-C (One to Many)和mTEDx (Many to Many)数据集上进行了实验,BLEU平均分比基线分别提高了68.38%和41%。与梯度情景记忆(GEM)基线相比,CABS还减轻了MuST-C数据集中82.2%的平均遗忘。结果表明,本文提出的基于CL的E2E - ST确保了之前训练过的语言之间的知识保留。据我们所知,之前还没有在CL设置中研究过E2E ST模型。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Continual End-to-End Speech-to-Text translation using augmented bi-sampler
Speech-to-Text (ST) is the translation of speech in one language to text in another language. Earlier models for ST used a pipeline approach combining automatic speech recognition (ASR) and machine translation (MT). Such models suffer from cascade error propagation, high latency and memory consumption. Therefore, End-to-End (E2E) ST models were proposed. Adapting E2E ST models to new language pairs results in deterioration of performance on the previously trained language pairs. This phenomenon is called Catastrophic Forgetting (CF). Therefore, we need ST models that can learn continually. The present work proposes a novel continual learning (CL) framework for E2E ST tasks. The core idea behind our approach combines proportional-language sampling (PLS), random sampling (RS), and augmentation. RS helps in performing well on the current task by sampling aggressively from it. PLS is used to sample equal proportion from past task data but it may cause over-fitting. To mitigate that, a combined approach of PLS+RS is used, dubbed as continual bi-sampler (CBS). However, CBS still suffers from over-fitting due to repeated samples from the past tasks. Therefore, we apply various augmentation strategies combined with CBS which we call continual augmented bi-sampler (CABS). We perform experiments on 4 language pairs of MuST-C (One to Many) and mTEDx (Many to Many) datasets and achieve a gain of 68.38% and 41% respectively in the average BLEU score compared to baselines. CABS also mitigates the average forgetting by 82.2% in MuST-C dataset compared to the Gradient Episodic Memory (GEM) baseline. The results show that the proposed CL based E2E ST ensures knowledge retention across previously trained languages. To the best of our knowledge, E2E ST model has not been studied before in a CL setup.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Computer Speech and Language
工程技术-计算机:人工智能
CiteScore
11.30
自引率
4.70%
发文量
80
审稿时长
22.9 weeks
期刊介绍:
Computer Speech & Language publishes reports of original research related to the recognition, understanding, production, coding and mining of speech and language.
The speech and language sciences have a long history, but it is only relatively recently that large-scale implementation of and experimentation with complex models of speech and language processing has become feasible. Such research is often carried out somewhat separately by practitioners of artificial intelligence, computer science, electronic engineering, information retrieval, linguistics, phonetics, or psychology.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


