Alex Nguyen, David J Schwab, Vudtiwat Ngampruetikorn
{"title":"数据粗粒度化可以提高模型性能。","authors":"Alex Nguyen, David J Schwab, Vudtiwat Ngampruetikorn","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>Lossy data transformations by definition lose information. Yet, in modern machine learning, methods like data pruning and lossy data augmentation can help improve generalization performance. We study this paradox using a solvable model of high-dimensional, ridge-regularized linear regression under <i>data coarse graining</i>. Inspired by the renormalization group in statistical physics, we analyze coarse-graining schemes that systematically discard features based on their relevance to the learning task. Our results reveal a nonmonotonic dependence of the prediction risk on the degree of coarse graining. A <i>high-pass</i> scheme-which filters out less relevant, lower-signal features-can help models generalize better. By contrast, a <i>low-pass</i> scheme that integrates out more relevant, higher-signal features is purely detrimental. Crucially, using optimal regularization, we demonstrate that this nonmonotonicity is a distinct effect of data coarse graining and not an artifact of double descent. Our framework offers a clear, analytical explanation for why careful data augmentation works: it strips away less relevant degrees of freedom and isolates more predictive signals. Our results highlight a complex, nonmonotonic risk landscape shaped by the structure of the data, and illustrate how ideas from statistical physics provide a principled lens for understanding modern machine learning phenomena.</p>","PeriodicalId":93888,"journal":{"name":"ArXiv","volume":" ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2025-09-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12458590/pdf/","citationCount":"0","resultStr":"{\"title\":\"Data coarse graining can improve model performance.\",\"authors\":\"Alex Nguyen, David J Schwab, Vudtiwat Ngampruetikorn\",\"doi\":\"\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Lossy data transformations by definition lose information. Yet, in modern machine learning, methods like data pruning and lossy data augmentation can help improve generalization performance. We study this paradox using a solvable model of high-dimensional, ridge-regularized linear regression under <i>data coarse graining</i>. Inspired by the renormalization group in statistical physics, we analyze coarse-graining schemes that systematically discard features based on their relevance to the learning task. Our results reveal a nonmonotonic dependence of the prediction risk on the degree of coarse graining. A <i>high-pass</i> scheme-which filters out less relevant, lower-signal features-can help models generalize better. By contrast, a <i>low-pass</i> scheme that integrates out more relevant, higher-signal features is purely detrimental. Crucially, using optimal regularization, we demonstrate that this nonmonotonicity is a distinct effect of data coarse graining and not an artifact of double descent. Our framework offers a clear, analytical explanation for why careful data augmentation works: it strips away less relevant degrees of freedom and isolates more predictive signals. Our results highlight a complex, nonmonotonic risk landscape shaped by the structure of the data, and illustrate how ideas from statistical physics provide a principled lens for understanding modern machine learning phenomena.</p>\",\"PeriodicalId\":93888,\"journal\":{\"name\":\"ArXiv\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-09-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12458590/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"ArXiv\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"ArXiv","FirstCategoryId":"1085","ListUrlMain":"","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Data coarse graining can improve model performance.
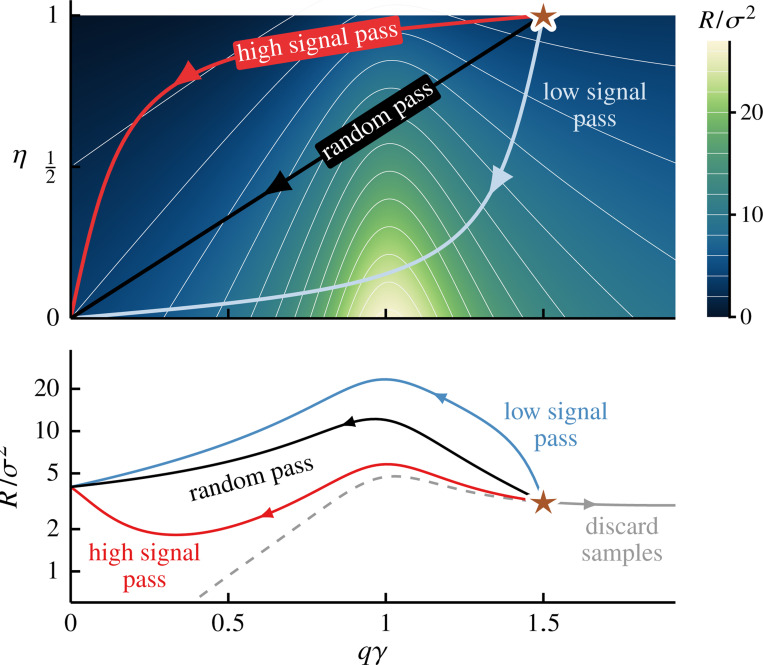
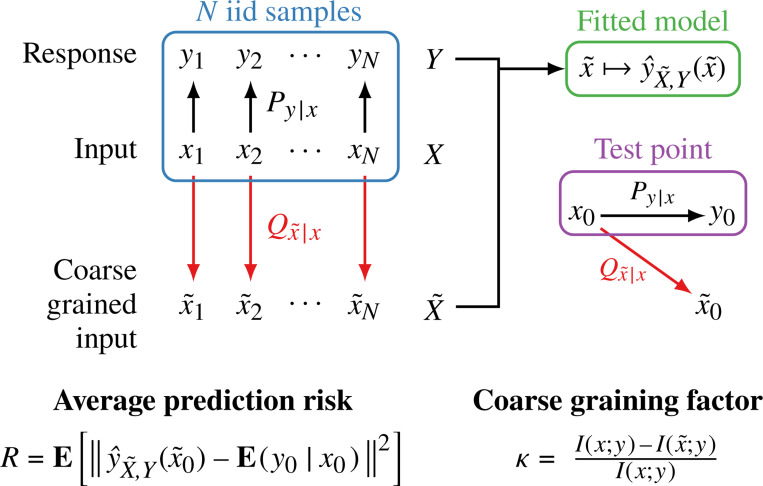
Lossy data transformations by definition lose information. Yet, in modern machine learning, methods like data pruning and lossy data augmentation can help improve generalization performance. We study this paradox using a solvable model of high-dimensional, ridge-regularized linear regression under data coarse graining. Inspired by the renormalization group in statistical physics, we analyze coarse-graining schemes that systematically discard features based on their relevance to the learning task. Our results reveal a nonmonotonic dependence of the prediction risk on the degree of coarse graining. A high-pass scheme-which filters out less relevant, lower-signal features-can help models generalize better. By contrast, a low-pass scheme that integrates out more relevant, higher-signal features is purely detrimental. Crucially, using optimal regularization, we demonstrate that this nonmonotonicity is a distinct effect of data coarse graining and not an artifact of double descent. Our framework offers a clear, analytical explanation for why careful data augmentation works: it strips away less relevant degrees of freedom and isolates more predictive signals. Our results highlight a complex, nonmonotonic risk landscape shaped by the structure of the data, and illustrate how ideas from statistical physics provide a principled lens for understanding modern machine learning phenomena.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


