{"title":"MRdb:包含大规模GWAS汇总数据的单变量和多变量孟德尔随机化的综合数据库。","authors":"Qian Liu, Yujie Zhang, Houxing Li, Jiatong Li, Mengyu Xin, Rui Sun, Yifan Dai, Xinxin Shan, Yuting He, Borui Xu, Shangwei Ning, Peng Wang, Qiuyan Guo","doi":"10.1093/database/baaf054","DOIUrl":null,"url":null,"abstract":"<p><p>Recent advancements highlight the importance of large-scale causal inference in elucidating disease mechanisms and guiding public health strategies. Mendelian randomization (MR) has become a cornerstone method for identifying causal relationships by leveraging genetic variants as instrumental variables. However, existing tools lack flexibility for multivariable analyses and fail to integrate diverse datasets effectively. To address these challenges, we introduce MRdb, a comprehensive database designed for conducting both univariable and multivariable MR analyses. MRdb encompasses 12 distinct categories of exposure data, including but not limited to 19 126 expression quantitative trait loci genes, 4907 plasma proteins, and 1400 plasma metabolites. Additionally, it integrates 48 507 disease outcomes sourced from FinnGen R10 and the IEU Open GWAS Project. MRdb offers robust data preprocessing features, including handling missing statistics, harmonizing datasets, and selecting instrumental variables to ensure high-quality analyses. Collectively, MRdb bridges the gaps in existing tools by integrating diverse datasets with user-friendly functionalities, empowering researchers to explore complex causal mechanisms.</p>","PeriodicalId":10923,"journal":{"name":"Database: The Journal of Biological Databases and Curation","volume":"2025 ","pages":""},"PeriodicalIF":3.6000,"publicationDate":"2025-01-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12462376/pdf/","citationCount":"0","resultStr":"{\"title\":\"MRdb: a comprehensive database of univariate and multivariate Mendelian randomization with large-scale GWAS summary data.\",\"authors\":\"Qian Liu, Yujie Zhang, Houxing Li, Jiatong Li, Mengyu Xin, Rui Sun, Yifan Dai, Xinxin Shan, Yuting He, Borui Xu, Shangwei Ning, Peng Wang, Qiuyan Guo\",\"doi\":\"10.1093/database/baaf054\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Recent advancements highlight the importance of large-scale causal inference in elucidating disease mechanisms and guiding public health strategies. Mendelian randomization (MR) has become a cornerstone method for identifying causal relationships by leveraging genetic variants as instrumental variables. However, existing tools lack flexibility for multivariable analyses and fail to integrate diverse datasets effectively. To address these challenges, we introduce MRdb, a comprehensive database designed for conducting both univariable and multivariable MR analyses. MRdb encompasses 12 distinct categories of exposure data, including but not limited to 19 126 expression quantitative trait loci genes, 4907 plasma proteins, and 1400 plasma metabolites. Additionally, it integrates 48 507 disease outcomes sourced from FinnGen R10 and the IEU Open GWAS Project. MRdb offers robust data preprocessing features, including handling missing statistics, harmonizing datasets, and selecting instrumental variables to ensure high-quality analyses. Collectively, MRdb bridges the gaps in existing tools by integrating diverse datasets with user-friendly functionalities, empowering researchers to explore complex causal mechanisms.</p>\",\"PeriodicalId\":10923,\"journal\":{\"name\":\"Database: The Journal of Biological Databases and Curation\",\"volume\":\"2025 \",\"pages\":\"\"},\"PeriodicalIF\":3.6000,\"publicationDate\":\"2025-01-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12462376/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Database: The Journal of Biological Databases and Curation\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1093/database/baaf054\",\"RegionNum\":4,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Database: The Journal of Biological Databases and Curation","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/database/baaf054","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
MRdb: a comprehensive database of univariate and multivariate Mendelian randomization with large-scale GWAS summary data.
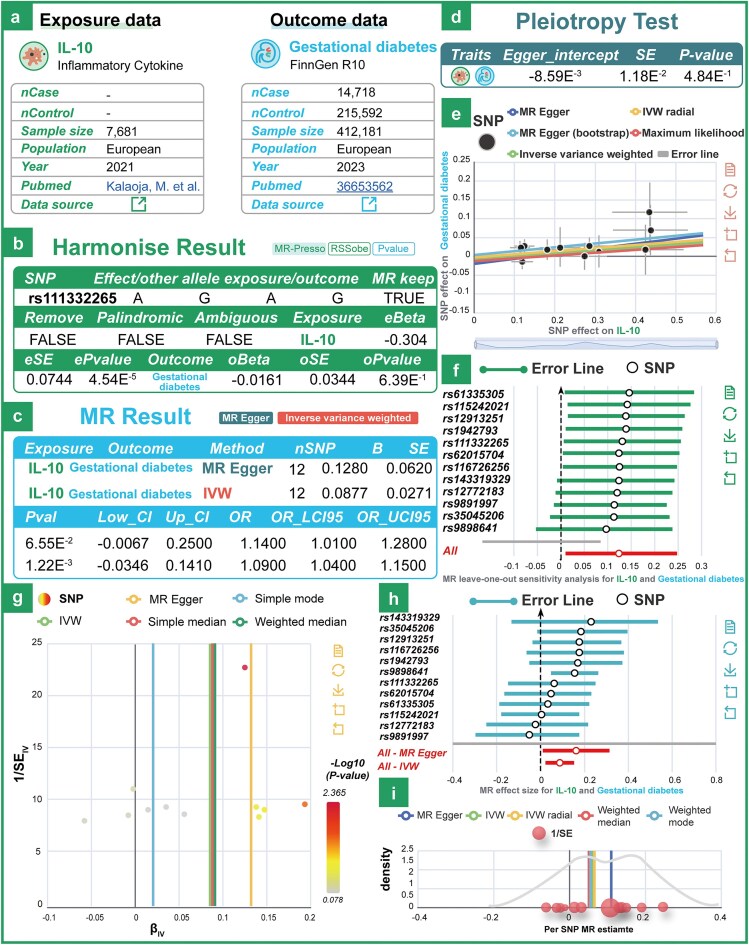
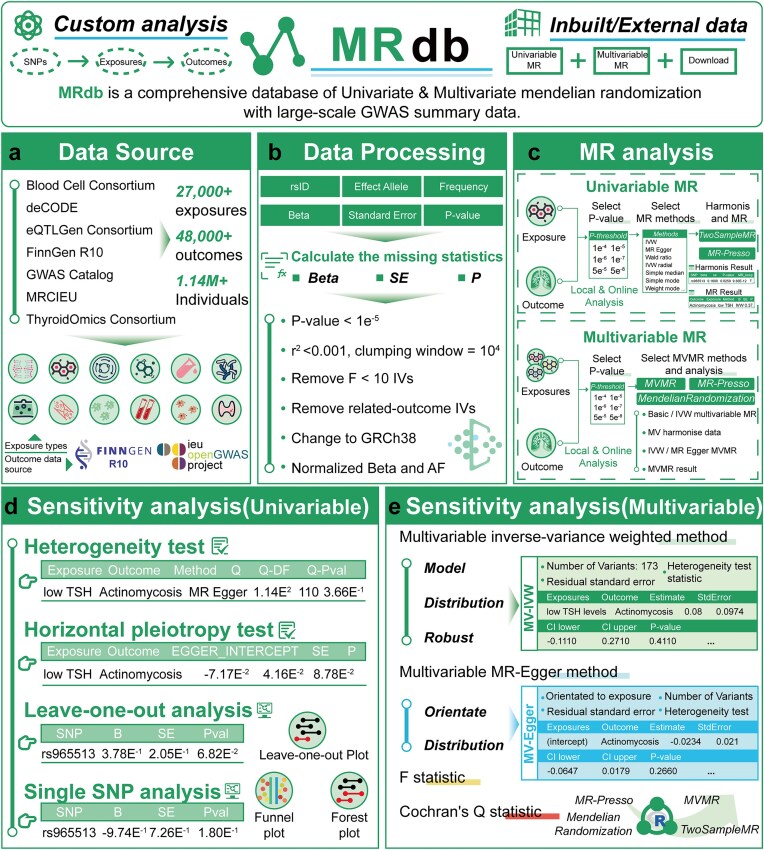
Recent advancements highlight the importance of large-scale causal inference in elucidating disease mechanisms and guiding public health strategies. Mendelian randomization (MR) has become a cornerstone method for identifying causal relationships by leveraging genetic variants as instrumental variables. However, existing tools lack flexibility for multivariable analyses and fail to integrate diverse datasets effectively. To address these challenges, we introduce MRdb, a comprehensive database designed for conducting both univariable and multivariable MR analyses. MRdb encompasses 12 distinct categories of exposure data, including but not limited to 19 126 expression quantitative trait loci genes, 4907 plasma proteins, and 1400 plasma metabolites. Additionally, it integrates 48 507 disease outcomes sourced from FinnGen R10 and the IEU Open GWAS Project. MRdb offers robust data preprocessing features, including handling missing statistics, harmonizing datasets, and selecting instrumental variables to ensure high-quality analyses. Collectively, MRdb bridges the gaps in existing tools by integrating diverse datasets with user-friendly functionalities, empowering researchers to explore complex causal mechanisms.
期刊介绍:
Huge volumes of primary data are archived in numerous open-access databases, and with new generation technologies becoming more common in laboratories, large datasets will become even more prevalent. The archiving, curation, analysis and interpretation of all of these data are a challenge. Database development and biocuration are at the forefront of the endeavor to make sense of this mounting deluge of data.
Database: The Journal of Biological Databases and Curation provides an open access platform for the presentation of novel ideas in database research and biocuration, and aims to help strengthen the bridge between database developers, curators, and users.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


