Paula Iglesias-Rivas, Roberto Del Amparo, Javier A Cabaleiro, Miguel Arenas
{"title":"蛋白质进化的经验替代模型:数据库、关系和建模考虑。","authors":"Paula Iglesias-Rivas, Roberto Del Amparo, Javier A Cabaleiro, Miguel Arenas","doi":"10.1093/database/baaf052","DOIUrl":null,"url":null,"abstract":"<p><p>Substitution models of protein evolution describe the patterns of amino acid substitutions over evolutionary time and are fundamental for probabilistic methods of phylogenetic inference. At the protein level, a variety of substitution models are available, but only empirical substitution models are well established in phylogenetics due to their mathematical simplicity. Despite their importance, a database compiling the large number of currently available empirical substitution models of protein evolution is lacking, although such a resource could facilitate access, assessment, and subsequent implementation of these models into phylogenetic frameworks. Besides, little is known about formal comparisons between the current set of empirical substitution models. We present EModelDB, a database of empirical substitution models of protein evolution required for probabilistic protein phylogenetics that includes the corresponding exchangeability matrices, model classification, and model-specific biological information. The database is integrated into a graphical user interface, written in Python and SQL, that facilitates its usability. We also compared common empirical substitution models in terms of the distance between their relative rates of amino acid substitution and amino frequencies at equilibrium. We found that substitution models derived from proteins related in nature tend to cluster together, reflecting similar evolutionary patterns. Indeed, we evaluated the empirical substitution models in terms of the folding stability of the derived modeled proteins and found that they generally produce less stable proteins compared to real proteins, suggesting that substitution models with additional evolutionary constraints can be preferred for studying protein evolution accounting for folding stability. Database URL: https://github.com/Paula-Iglesias-Rivas/EModelDB.</p>","PeriodicalId":10923,"journal":{"name":"Database: The Journal of Biological Databases and Curation","volume":"2025 ","pages":""},"PeriodicalIF":3.6000,"publicationDate":"2025-01-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12462380/pdf/","citationCount":"0","resultStr":"{\"title\":\"Empirical substitution models of protein evolution: database, relationships, and modeling considerations.\",\"authors\":\"Paula Iglesias-Rivas, Roberto Del Amparo, Javier A Cabaleiro, Miguel Arenas\",\"doi\":\"10.1093/database/baaf052\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Substitution models of protein evolution describe the patterns of amino acid substitutions over evolutionary time and are fundamental for probabilistic methods of phylogenetic inference. At the protein level, a variety of substitution models are available, but only empirical substitution models are well established in phylogenetics due to their mathematical simplicity. Despite their importance, a database compiling the large number of currently available empirical substitution models of protein evolution is lacking, although such a resource could facilitate access, assessment, and subsequent implementation of these models into phylogenetic frameworks. Besides, little is known about formal comparisons between the current set of empirical substitution models. We present EModelDB, a database of empirical substitution models of protein evolution required for probabilistic protein phylogenetics that includes the corresponding exchangeability matrices, model classification, and model-specific biological information. The database is integrated into a graphical user interface, written in Python and SQL, that facilitates its usability. We also compared common empirical substitution models in terms of the distance between their relative rates of amino acid substitution and amino frequencies at equilibrium. We found that substitution models derived from proteins related in nature tend to cluster together, reflecting similar evolutionary patterns. Indeed, we evaluated the empirical substitution models in terms of the folding stability of the derived modeled proteins and found that they generally produce less stable proteins compared to real proteins, suggesting that substitution models with additional evolutionary constraints can be preferred for studying protein evolution accounting for folding stability. Database URL: https://github.com/Paula-Iglesias-Rivas/EModelDB.</p>\",\"PeriodicalId\":10923,\"journal\":{\"name\":\"Database: The Journal of Biological Databases and Curation\",\"volume\":\"2025 \",\"pages\":\"\"},\"PeriodicalIF\":3.6000,\"publicationDate\":\"2025-01-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12462380/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Database: The Journal of Biological Databases and Curation\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1093/database/baaf052\",\"RegionNum\":4,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Database: The Journal of Biological Databases and Curation","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/database/baaf052","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Empirical substitution models of protein evolution: database, relationships, and modeling considerations.
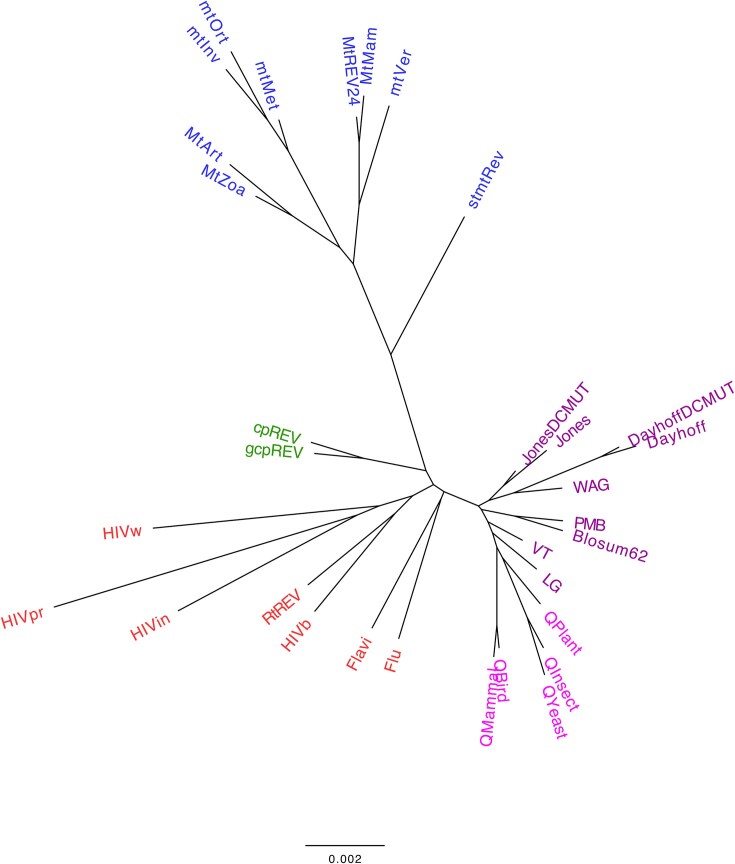
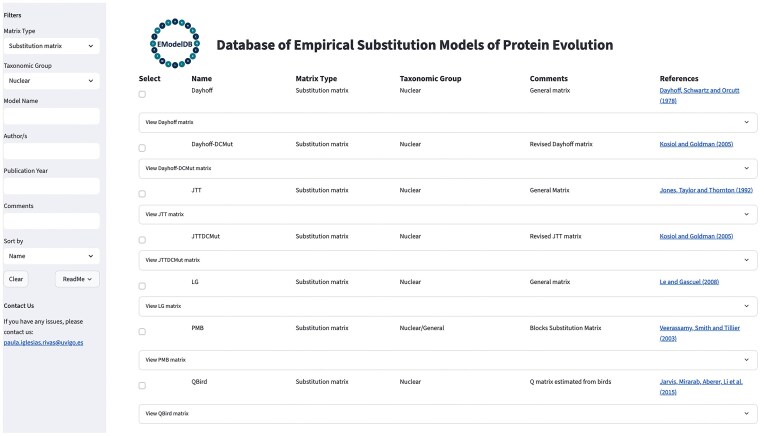
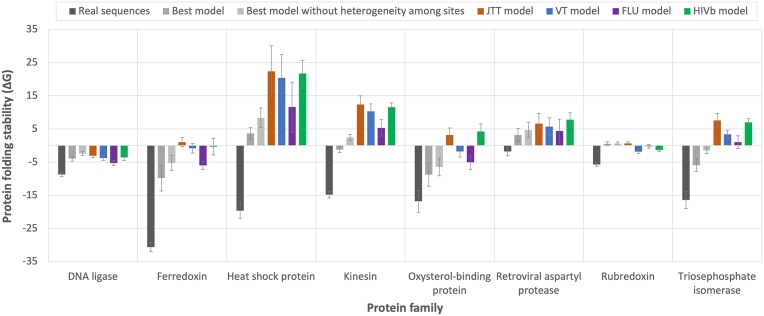
Substitution models of protein evolution describe the patterns of amino acid substitutions over evolutionary time and are fundamental for probabilistic methods of phylogenetic inference. At the protein level, a variety of substitution models are available, but only empirical substitution models are well established in phylogenetics due to their mathematical simplicity. Despite their importance, a database compiling the large number of currently available empirical substitution models of protein evolution is lacking, although such a resource could facilitate access, assessment, and subsequent implementation of these models into phylogenetic frameworks. Besides, little is known about formal comparisons between the current set of empirical substitution models. We present EModelDB, a database of empirical substitution models of protein evolution required for probabilistic protein phylogenetics that includes the corresponding exchangeability matrices, model classification, and model-specific biological information. The database is integrated into a graphical user interface, written in Python and SQL, that facilitates its usability. We also compared common empirical substitution models in terms of the distance between their relative rates of amino acid substitution and amino frequencies at equilibrium. We found that substitution models derived from proteins related in nature tend to cluster together, reflecting similar evolutionary patterns. Indeed, we evaluated the empirical substitution models in terms of the folding stability of the derived modeled proteins and found that they generally produce less stable proteins compared to real proteins, suggesting that substitution models with additional evolutionary constraints can be preferred for studying protein evolution accounting for folding stability. Database URL: https://github.com/Paula-Iglesias-Rivas/EModelDB.
期刊介绍:
Huge volumes of primary data are archived in numerous open-access databases, and with new generation technologies becoming more common in laboratories, large datasets will become even more prevalent. The archiving, curation, analysis and interpretation of all of these data are a challenge. Database development and biocuration are at the forefront of the endeavor to make sense of this mounting deluge of data.
Database: The Journal of Biological Databases and Curation provides an open access platform for the presentation of novel ideas in database research and biocuration, and aims to help strengthen the bridge between database developers, curators, and users.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


