Susan Ellul, Stijn Vansteelandt, John B Carlin, Margarita Moreno-Betancur
{"title":"因果机器学习方法及交叉拟合在高维混杂环境中的应用。","authors":"Susan Ellul, Stijn Vansteelandt, John B Carlin, Margarita Moreno-Betancur","doi":"10.1002/sim.70272","DOIUrl":null,"url":null,"abstract":"<p><p>Observational epidemiological studies commonly seek to estimate the causal effect of an exposure on an outcome. Adjustment for potential confounding bias in modern studies is challenging due to the presence of high-dimensional confounding, which occurs when there are many confounders relative to sample size or complex relationships between continuous confounders and exposure and outcome. Doubly robust methods such as Augmented Inverse Probability Weighting (AIPW) and Targeted Maximum Likelihood Estimation (TMLE) have the potential to address these challenges, using data-adaptive approaches and cross-fitting, but despite recent advances, limited evaluation and guidance are available on their implementation in realistic settings where high-dimensional confounding is present. Motivated by an early-life cohort study, we conducted an extensive simulation study to compare the relative performance of AIPW and TMLE using data-adaptive approaches for estimating the average causal effect (ACE). We evaluated the benefits of using cross-fitting with a varying number of folds, as well as the impact of using a reduced versus full (larger, more diverse) library in the Super Learner ensemble learning approach used for implementation. We found that AIPW and TMLE performed similarly in most cases for estimating the ACE, but TMLE was more stable. Cross-fitting improved the performance of both methods, but was more important for variance estimation and coverage than for point estimates, with the number of folds a less important consideration. Using a full Super Learner library was important to reduce bias and variance in complex scenarios typical of modern health research studies.</p>","PeriodicalId":21879,"journal":{"name":"Statistics in Medicine","volume":"44 20-22","pages":"e70272"},"PeriodicalIF":1.8000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12457817/pdf/","citationCount":"0","resultStr":"{\"title\":\"Causal Machine Learning Methods and Use of Cross-Fitting in Settings With High-Dimensional Confounding.\",\"authors\":\"Susan Ellul, Stijn Vansteelandt, John B Carlin, Margarita Moreno-Betancur\",\"doi\":\"10.1002/sim.70272\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Observational epidemiological studies commonly seek to estimate the causal effect of an exposure on an outcome. Adjustment for potential confounding bias in modern studies is challenging due to the presence of high-dimensional confounding, which occurs when there are many confounders relative to sample size or complex relationships between continuous confounders and exposure and outcome. Doubly robust methods such as Augmented Inverse Probability Weighting (AIPW) and Targeted Maximum Likelihood Estimation (TMLE) have the potential to address these challenges, using data-adaptive approaches and cross-fitting, but despite recent advances, limited evaluation and guidance are available on their implementation in realistic settings where high-dimensional confounding is present. Motivated by an early-life cohort study, we conducted an extensive simulation study to compare the relative performance of AIPW and TMLE using data-adaptive approaches for estimating the average causal effect (ACE). We evaluated the benefits of using cross-fitting with a varying number of folds, as well as the impact of using a reduced versus full (larger, more diverse) library in the Super Learner ensemble learning approach used for implementation. We found that AIPW and TMLE performed similarly in most cases for estimating the ACE, but TMLE was more stable. Cross-fitting improved the performance of both methods, but was more important for variance estimation and coverage than for point estimates, with the number of folds a less important consideration. Using a full Super Learner library was important to reduce bias and variance in complex scenarios typical of modern health research studies.</p>\",\"PeriodicalId\":21879,\"journal\":{\"name\":\"Statistics in Medicine\",\"volume\":\"44 20-22\",\"pages\":\"e70272\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2025-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12457817/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Statistics in Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1002/sim.70272\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Statistics in Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1002/sim.70272","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Causal Machine Learning Methods and Use of Cross-Fitting in Settings With High-Dimensional Confounding.
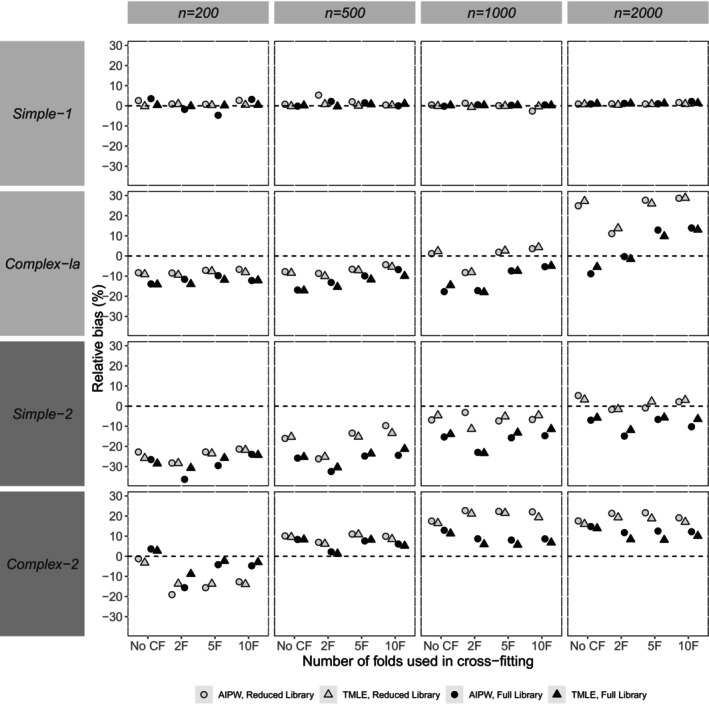
Observational epidemiological studies commonly seek to estimate the causal effect of an exposure on an outcome. Adjustment for potential confounding bias in modern studies is challenging due to the presence of high-dimensional confounding, which occurs when there are many confounders relative to sample size or complex relationships between continuous confounders and exposure and outcome. Doubly robust methods such as Augmented Inverse Probability Weighting (AIPW) and Targeted Maximum Likelihood Estimation (TMLE) have the potential to address these challenges, using data-adaptive approaches and cross-fitting, but despite recent advances, limited evaluation and guidance are available on their implementation in realistic settings where high-dimensional confounding is present. Motivated by an early-life cohort study, we conducted an extensive simulation study to compare the relative performance of AIPW and TMLE using data-adaptive approaches for estimating the average causal effect (ACE). We evaluated the benefits of using cross-fitting with a varying number of folds, as well as the impact of using a reduced versus full (larger, more diverse) library in the Super Learner ensemble learning approach used for implementation. We found that AIPW and TMLE performed similarly in most cases for estimating the ACE, but TMLE was more stable. Cross-fitting improved the performance of both methods, but was more important for variance estimation and coverage than for point estimates, with the number of folds a less important consideration. Using a full Super Learner library was important to reduce bias and variance in complex scenarios typical of modern health research studies.
期刊介绍:
The journal aims to influence practice in medicine and its associated sciences through the publication of papers on statistical and other quantitative methods. Papers will explain new methods and demonstrate their application, preferably through a substantive, real, motivating example or a comprehensive evaluation based on an illustrative example. Alternatively, papers will report on case-studies where creative use or technical generalizations of established methodology is directed towards a substantive application. Reviews of, and tutorials on, general topics relevant to the application of statistics to medicine will also be published. The main criteria for publication are appropriateness of the statistical methods to a particular medical problem and clarity of exposition. Papers with primarily mathematical content will be excluded. The journal aims to enhance communication between statisticians, clinicians and medical researchers.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


