机器学习模型中误差控制的非加性交互发现
IF 23.9
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
机器学习(ML)模型是检测复杂模式的强大工具,但它们的“黑箱”性质限制了它们的可解释性,阻碍了它们在医疗保健和金融等关键领域的应用。可解释的机器学习方法旨在解释特征如何影响模型预测,但往往侧重于单变量特征的重要性,忽略了复杂的特征相互作用。虽然最近的努力将可解释性扩展到特征交互,但现有的方法在鲁棒性和误差控制方面存在困难,特别是在数据扰动下。在本研究中,我们引入了一种可信特征交互发现方法Diamond。Diamond独特地集成了model-X仿冒框架,以控制错误发现率,确保低比例的错误检测交互。Diamond包括一个非加性蒸馏程序,该程序改进了现有的相互作用重要性度量,以隔离非加性相互作用效应并保持错误发现率控制。这种方法解决了现成的交互度量的局限性,如果使用不当,可能会导致不准确的发现。Diamond的适用性涵盖了广泛的机器学习模型,包括深度神经网络、变压器、基于树的模型和基于分解的模型。对各种生物医学研究的模拟和真实数据集的经验评估表明,它在实现可靠的数据驱动的科学发现方面具有实用价值。戴蒙德代表了利用机器学习进行科学创新和假设生成的重要一步。Diamond是一种统计严谨的方法,能够在机器学习模型中找到有意义的特征交互,使黑盒模型更易于科学和医学解释。本文章由计算机程序翻译,如有差异,请以英文原文为准。
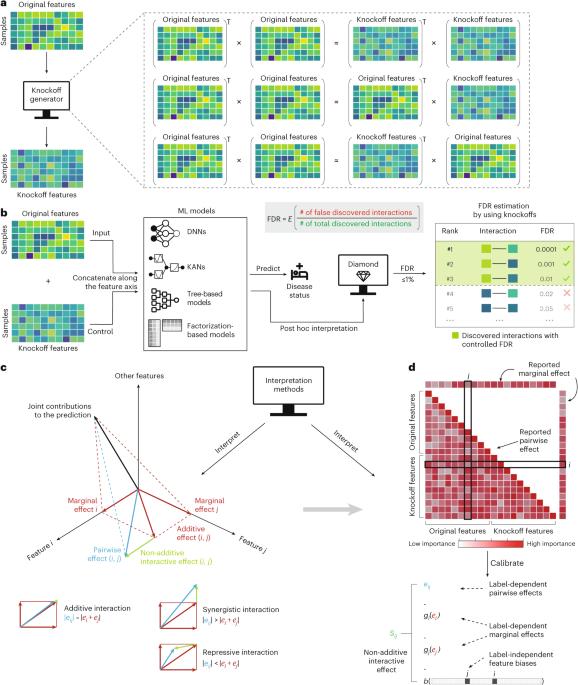
Error-controlled non-additive interaction discovery in machine learning models
Machine learning (ML) models are powerful tools for detecting complex patterns, yet their ‘black-box’ nature limits their interpretability, hindering their use in critical domains like healthcare and finance. Interpretable ML methods aim to explain how features influence model predictions but often focus on univariate feature importance, overlooking complex feature interactions. Although recent efforts extend interpretability to feature interactions, existing approaches struggle with robustness and error control, especially under data perturbations. In this study, we introduce Diamond, a method for trustworthy feature interaction discovery. Diamond uniquely integrates the model-X knockoffs framework to control the false discovery rate, ensuring a low proportion of falsely detected interactions. Diamond includes a non-additivity distillation procedure that refines existing interaction importance measures to isolate non-additive interaction effects and preserve false discovery rate control. This approach addresses the limitations of off-the-shelf interaction measures, which, when used naively, can lead to inaccurate discoveries. Diamond’s applicability spans a broad class of ML models, including deep neural networks, transformers, tree-based models and factorization-based models. Empirical evaluations on both simulated and real datasets across various biomedical studies demonstrate its utility in enabling reliable data-driven scientific discoveries. Diamond represents a significant step forward in leveraging ML for scientific innovation and hypothesis generation. Diamond, a statistically rigorous method, is capable of finding meaningful feature interactions within machine learning models, making black-box models more interpretable for science and medicine.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Nature Machine Intelligence
Multiple-
CiteScore
36.90
自引率
2.10%
发文量
127
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


