{"title":"IGD:一种简单、高效的基因型数据格式。","authors":"Drew DeHaas, Xinzhu Wei","doi":"10.1093/bioadv/vbaf205","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>While there are a variety of file formats for storing reference-sequence-aligned genotype data, many are complex or inefficient. Programming language support for such formats is often limited. A file format that is simple to understand and implement-yet fast and small-is helpful for research on highly scalable statistical and population genetics methods.</p><p><strong>Results: </strong>We present the Indexable Genotype Data (IGD) file format, a simple uncompressed binary format that can be more than 100× faster and 3.5× smaller than <i>vcf.gz</i> on biobank-scale whole-genome sequence data. The implementation for reading and writing IGD in Python is under 350 lines of code, which reflects the simplicity of the format.</p><p><strong>Availability and implementation: </strong>A C++ library for reading and writing IGD, and tooling to convert .vcf.gz files, can be found at https://github.com/aprilweilab/picovcf. A Python library is at https://github.com/aprilweilab/pyigd.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"5 1","pages":"vbaf205"},"PeriodicalIF":2.8000,"publicationDate":"2025-08-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12448908/pdf/","citationCount":"0","resultStr":"{\"title\":\"IGD: a simple, efficient genotype data format.\",\"authors\":\"Drew DeHaas, Xinzhu Wei\",\"doi\":\"10.1093/bioadv/vbaf205\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Motivation: </strong>While there are a variety of file formats for storing reference-sequence-aligned genotype data, many are complex or inefficient. Programming language support for such formats is often limited. A file format that is simple to understand and implement-yet fast and small-is helpful for research on highly scalable statistical and population genetics methods.</p><p><strong>Results: </strong>We present the Indexable Genotype Data (IGD) file format, a simple uncompressed binary format that can be more than 100× faster and 3.5× smaller than <i>vcf.gz</i> on biobank-scale whole-genome sequence data. The implementation for reading and writing IGD in Python is under 350 lines of code, which reflects the simplicity of the format.</p><p><strong>Availability and implementation: </strong>A C++ library for reading and writing IGD, and tooling to convert .vcf.gz files, can be found at https://github.com/aprilweilab/picovcf. A Python library is at https://github.com/aprilweilab/pyigd.</p>\",\"PeriodicalId\":72368,\"journal\":{\"name\":\"Bioinformatics advances\",\"volume\":\"5 1\",\"pages\":\"vbaf205\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2025-08-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12448908/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics advances\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/bioadv/vbaf205\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbaf205","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Motivation: While there are a variety of file formats for storing reference-sequence-aligned genotype data, many are complex or inefficient. Programming language support for such formats is often limited. A file format that is simple to understand and implement-yet fast and small-is helpful for research on highly scalable statistical and population genetics methods.
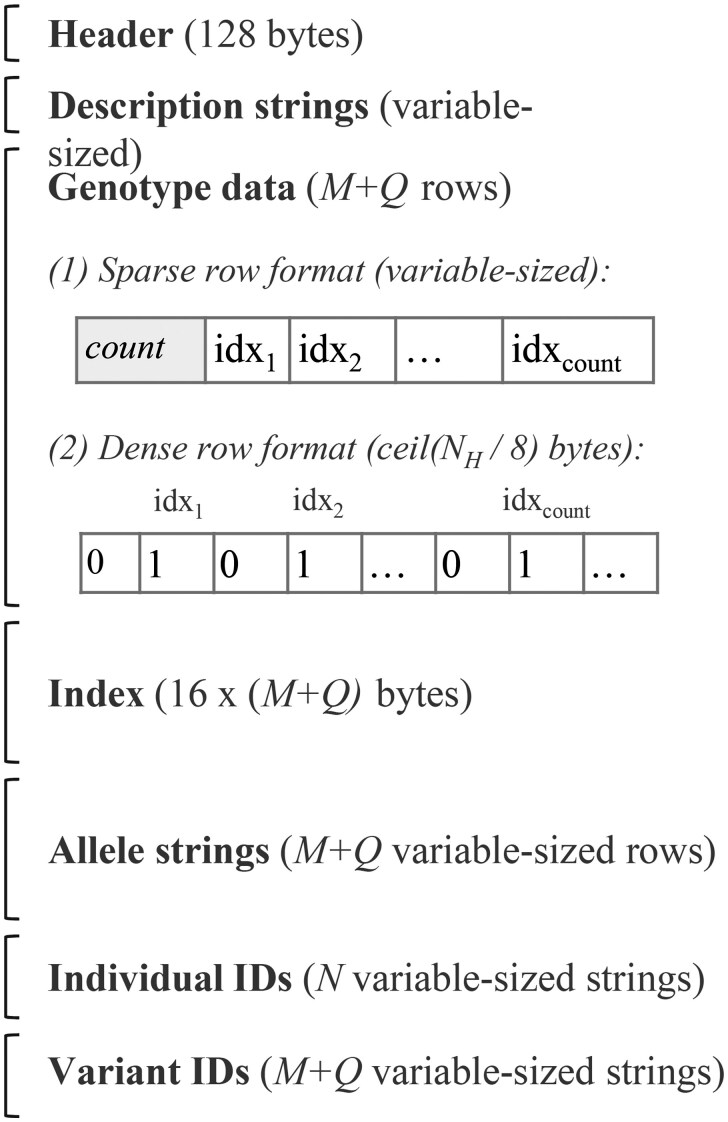
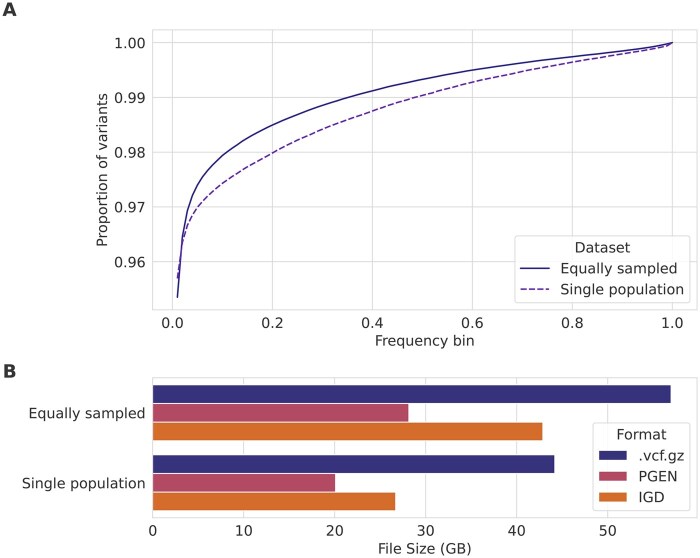
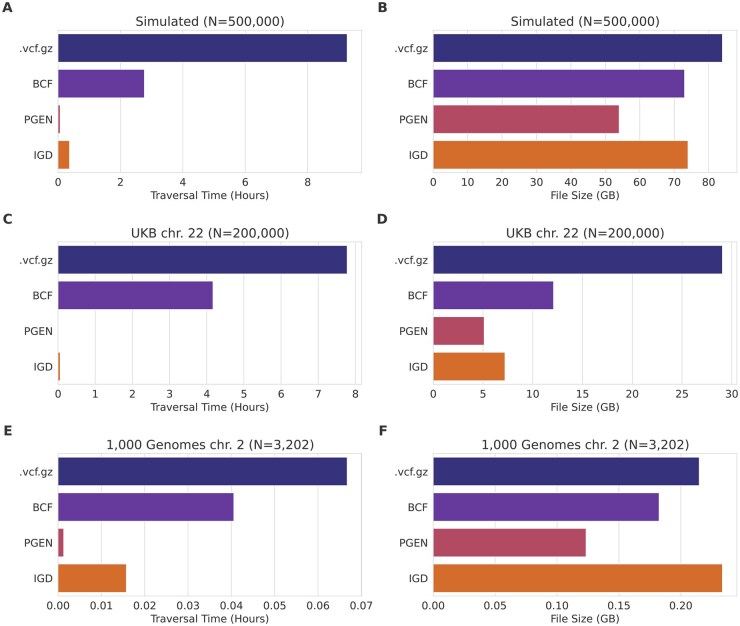
Results: We present the Indexable Genotype Data (IGD) file format, a simple uncompressed binary format that can be more than 100× faster and 3.5× smaller than vcf.gz on biobank-scale whole-genome sequence data. The implementation for reading and writing IGD in Python is under 350 lines of code, which reflects the simplicity of the format.
Availability and implementation: A C++ library for reading and writing IGD, and tooling to convert .vcf.gz files, can be found at https://github.com/aprilweilab/picovcf. A Python library is at https://github.com/aprilweilab/pyigd.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


