{"title":"自适应采样方法有助于确定可靠的数据集大小,用于循证建模。","authors":"Tim Breitenbach, Thomas Dandekar","doi":"10.3389/fbinf.2025.1528515","DOIUrl":null,"url":null,"abstract":"<p><p>How can we be sure that there is sufficient data for our model, such that the predictions remain reliable on unseen data and the conclusions drawn from the fitted model would not vary significantly when using a different sample of the same size? We answer these and related questions through a systematic approach that examines the data size and the corresponding gains in accuracy. Assuming the sample data are drawn from a data pool with no data drift, the law of large numbers ensures that a model converges to its ground truth accuracy. Our approach provides a heuristic method for investigating the speed of convergence with respect to the size of the data sample. This relationship is estimated using sampling methods, which introduces a variation in the convergence speed results across different runs. To stabilize results-so that conclusions do not depend on the run-and extract the most reliable information encoded in the available data regarding convergence speed, the presented method automatically determines a sufficient number of repetitions to reduce sampling deviations below a predefined threshold, thereby ensuring the reliability of conclusions about the required amount of data.</p>","PeriodicalId":73066,"journal":{"name":"Frontiers in bioinformatics","volume":"5 ","pages":"1528515"},"PeriodicalIF":3.9000,"publicationDate":"2025-09-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12444090/pdf/","citationCount":"0","resultStr":"{\"title\":\"Adaptive sampling methods facilitate the determination of reliable dataset sizes for evidence-based modeling.\",\"authors\":\"Tim Breitenbach, Thomas Dandekar\",\"doi\":\"10.3389/fbinf.2025.1528515\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>How can we be sure that there is sufficient data for our model, such that the predictions remain reliable on unseen data and the conclusions drawn from the fitted model would not vary significantly when using a different sample of the same size? We answer these and related questions through a systematic approach that examines the data size and the corresponding gains in accuracy. Assuming the sample data are drawn from a data pool with no data drift, the law of large numbers ensures that a model converges to its ground truth accuracy. Our approach provides a heuristic method for investigating the speed of convergence with respect to the size of the data sample. This relationship is estimated using sampling methods, which introduces a variation in the convergence speed results across different runs. To stabilize results-so that conclusions do not depend on the run-and extract the most reliable information encoded in the available data regarding convergence speed, the presented method automatically determines a sufficient number of repetitions to reduce sampling deviations below a predefined threshold, thereby ensuring the reliability of conclusions about the required amount of data.</p>\",\"PeriodicalId\":73066,\"journal\":{\"name\":\"Frontiers in bioinformatics\",\"volume\":\"5 \",\"pages\":\"1528515\"},\"PeriodicalIF\":3.9000,\"publicationDate\":\"2025-09-04\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12444090/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in bioinformatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3389/fbinf.2025.1528515\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fbinf.2025.1528515","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Adaptive sampling methods facilitate the determination of reliable dataset sizes for evidence-based modeling.
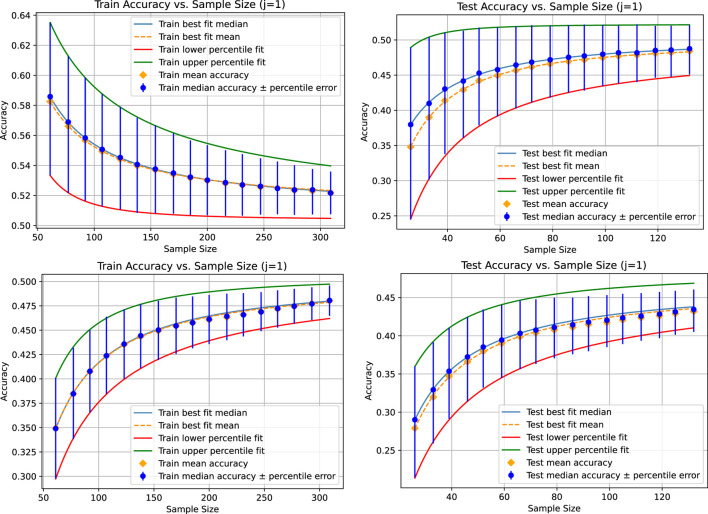
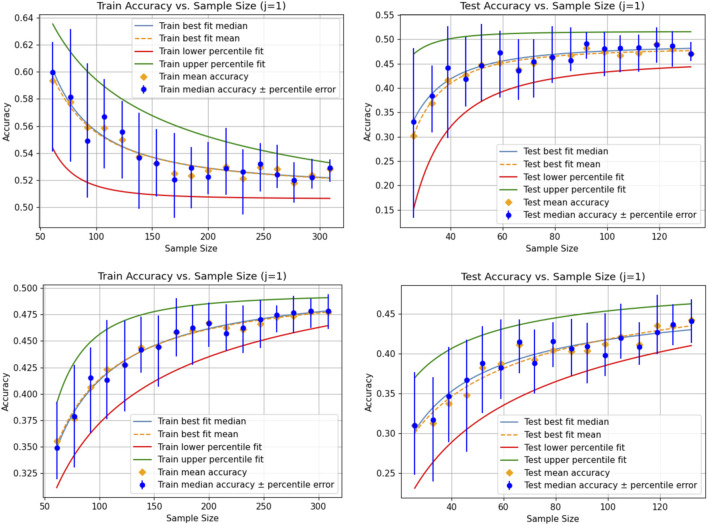
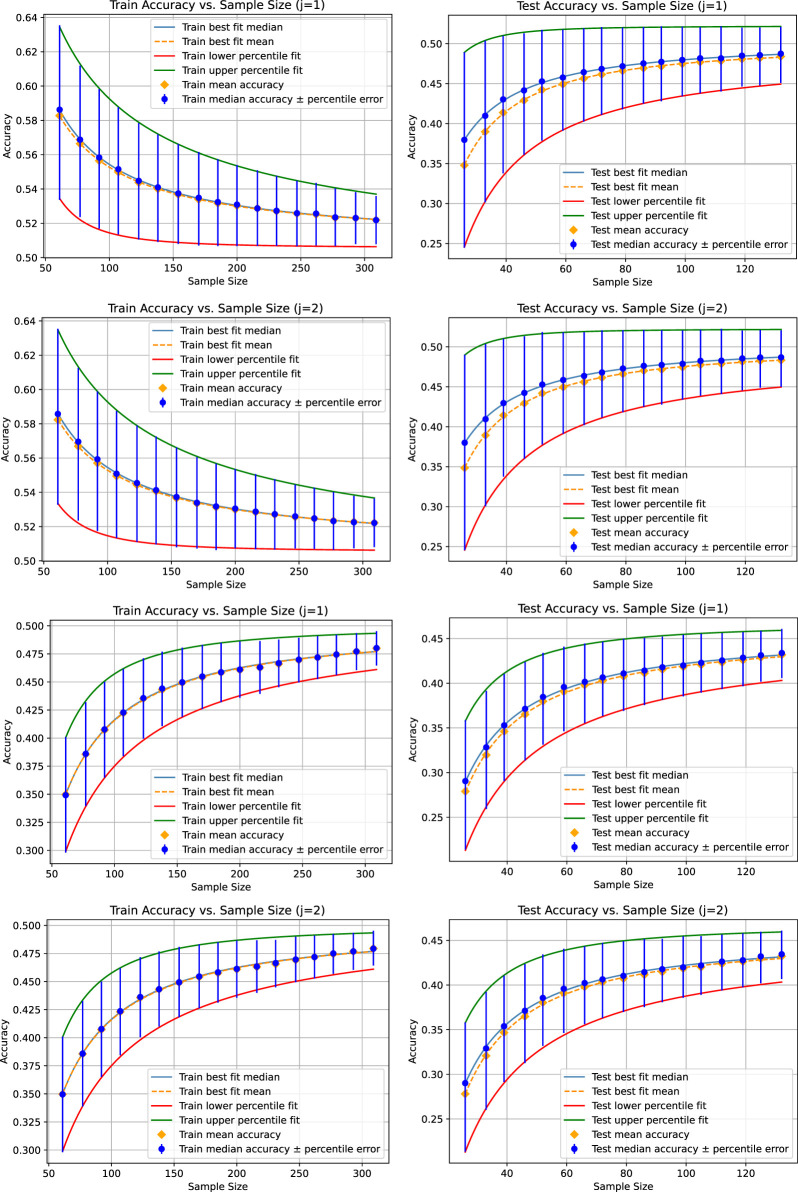
How can we be sure that there is sufficient data for our model, such that the predictions remain reliable on unseen data and the conclusions drawn from the fitted model would not vary significantly when using a different sample of the same size? We answer these and related questions through a systematic approach that examines the data size and the corresponding gains in accuracy. Assuming the sample data are drawn from a data pool with no data drift, the law of large numbers ensures that a model converges to its ground truth accuracy. Our approach provides a heuristic method for investigating the speed of convergence with respect to the size of the data sample. This relationship is estimated using sampling methods, which introduces a variation in the convergence speed results across different runs. To stabilize results-so that conclusions do not depend on the run-and extract the most reliable information encoded in the available data regarding convergence speed, the presented method automatically determines a sufficient number of repetitions to reduce sampling deviations below a predefined threshold, thereby ensuring the reliability of conclusions about the required amount of data.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


