Elizabeth Ford, Simon Pillinger, Robert Stewart, Kerina Jones, Angus Roberts, Arlene Casey, Katie Goddard, Goran Nenadic
{"title":"使用去识别的临床免费文本数据进行健康研究的患者再识别风险是什么?","authors":"Elizabeth Ford, Simon Pillinger, Robert Stewart, Kerina Jones, Angus Roberts, Arlene Casey, Katie Goddard, Goran Nenadic","doi":"10.1007/s43681-025-00681-0","DOIUrl":null,"url":null,"abstract":"<div><p>Important clinical information is recorded in free text in patients’ records, notes, letters and reports in healthcare settings. This information is currently under-used for health research and innovation. Free text requires more processing for analysis than structured data, but processing natural language at scale has recently advanced, using large language models. However, data controllers are often concerned about patient privacy risks if clinical text is allowed to be used in research. Text can be de-identified, yet it is challenging to quantify the residual risk of patient re-identification. This paper presents a comprehensive review and discussion of elements for consideration when evaluating the risk of patient re-identification from free text. We consider (1) the reasons researchers want access to free text; (2) the accuracy of automated de-identification processes, identifying best practice; (3) methods previously used for re-identifying health data and their success; (4) additional protections put in place around health data, particularly focussing on the UK where “Five Safes” secure data environments are used; (5) risks of harm to patients from potential re-identification and (6) public views on free text being used for research. We present a model to conceptualise and evaluate risk of re-identification, accompanied by case studies of successful governance of free text for research in the UK. When de-identified and stored in secure data environments, the risk of patient re-identification from clinical free text is very low. More health research should be enabled by routinely storing and giving access to de-identified clinical text data.</p></div>","PeriodicalId":72137,"journal":{"name":"AI and ethics","volume":"5 5","pages":"4441 - 4454"},"PeriodicalIF":0.0000,"publicationDate":"2025-02-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12449363/pdf/","citationCount":"0","resultStr":"{\"title\":\"What is the patient re-identification risk from using de-identified clinical free text data for health research?\",\"authors\":\"Elizabeth Ford, Simon Pillinger, Robert Stewart, Kerina Jones, Angus Roberts, Arlene Casey, Katie Goddard, Goran Nenadic\",\"doi\":\"10.1007/s43681-025-00681-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Important clinical information is recorded in free text in patients’ records, notes, letters and reports in healthcare settings. This information is currently under-used for health research and innovation. Free text requires more processing for analysis than structured data, but processing natural language at scale has recently advanced, using large language models. However, data controllers are often concerned about patient privacy risks if clinical text is allowed to be used in research. Text can be de-identified, yet it is challenging to quantify the residual risk of patient re-identification. This paper presents a comprehensive review and discussion of elements for consideration when evaluating the risk of patient re-identification from free text. We consider (1) the reasons researchers want access to free text; (2) the accuracy of automated de-identification processes, identifying best practice; (3) methods previously used for re-identifying health data and their success; (4) additional protections put in place around health data, particularly focussing on the UK where “Five Safes” secure data environments are used; (5) risks of harm to patients from potential re-identification and (6) public views on free text being used for research. We present a model to conceptualise and evaluate risk of re-identification, accompanied by case studies of successful governance of free text for research in the UK. When de-identified and stored in secure data environments, the risk of patient re-identification from clinical free text is very low. More health research should be enabled by routinely storing and giving access to de-identified clinical text data.</p></div>\",\"PeriodicalId\":72137,\"journal\":{\"name\":\"AI and ethics\",\"volume\":\"5 5\",\"pages\":\"4441 - 4454\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-02-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12449363/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"AI and ethics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s43681-025-00681-0\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"AI and ethics","FirstCategoryId":"1085","ListUrlMain":"https://link.springer.com/article/10.1007/s43681-025-00681-0","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
What is the patient re-identification risk from using de-identified clinical free text data for health research?
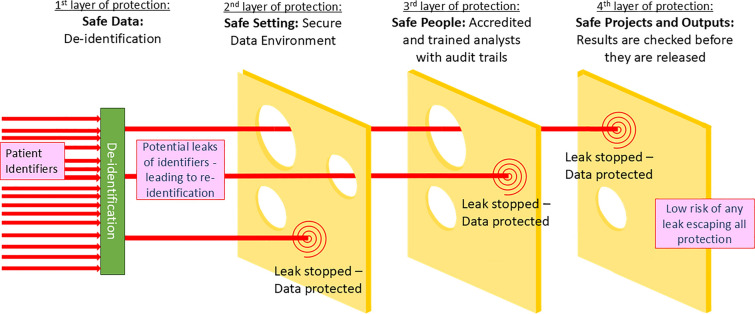
Important clinical information is recorded in free text in patients’ records, notes, letters and reports in healthcare settings. This information is currently under-used for health research and innovation. Free text requires more processing for analysis than structured data, but processing natural language at scale has recently advanced, using large language models. However, data controllers are often concerned about patient privacy risks if clinical text is allowed to be used in research. Text can be de-identified, yet it is challenging to quantify the residual risk of patient re-identification. This paper presents a comprehensive review and discussion of elements for consideration when evaluating the risk of patient re-identification from free text. We consider (1) the reasons researchers want access to free text; (2) the accuracy of automated de-identification processes, identifying best practice; (3) methods previously used for re-identifying health data and their success; (4) additional protections put in place around health data, particularly focussing on the UK where “Five Safes” secure data environments are used; (5) risks of harm to patients from potential re-identification and (6) public views on free text being used for research. We present a model to conceptualise and evaluate risk of re-identification, accompanied by case studies of successful governance of free text for research in the UK. When de-identified and stored in secure data environments, the risk of patient re-identification from clinical free text is very low. More health research should be enabled by routinely storing and giving access to de-identified clinical text data.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


