基于进化学习和基于图的流形学习的深度时间序列聚类
IF 6.9
1区 管理学
Q1 COMPUTER SCIENCE, INFORMATION SYSTEMS
引用次数: 0
摘要
深度时间序列聚类(DTC)方法近年来备受关注,但由于依赖于基于kl -散度的损失,通常存在聚类不平衡、初始化敏感和局部最优等问题。为了克服这个问题,我们提出了一种新的深度进化时间序列聚类(DETC)方法,该方法使用进化搜索过程,在每次迭代中生成不同的候选解。使用基于原始时间序列和潜在空间中的内部验证度量的适应度函数来评估这些解决方案。这增强了鲁棒性并避免了次优解决方案,从而导致更稳定和准确的聚类。DETC使用自动编码器进行潜在表示,但如果没有适当的约束,模型可能会学习到较差的表示,从而导致局部最优、收敛缓慢、不稳定和对噪声敏感。为了学习判别表示,DETC引入了一个图正则化损失,该损失在潜在空间和重构空间中都保留了时间序列的拓扑结构。我们在15个不同的时间序列数据集上进行了广泛的实验,包括不同的样本量、聚类计数和序列长度,以进行全面的评估。实验结果表明,DETC显著优于现有的最先进的DTC基准,显示出其优越的聚类性能和鲁棒性。在所比较的11种方法中,DETC的平均排名为1.47,与最佳基准模型相比,其NMI平均提高了11%。代码和数据可在https://anonymous.4open.science/r/Deep-Evolutionary-Time-Series-Clustering-DETC-DD2D/README.md上获得。本文章由计算机程序翻译,如有差异,请以英文原文为准。
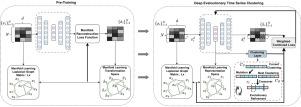
Deep time-series clustering via evolutionary learning and graph-based manifold learning
Deep time series clustering (DTC) methods have recently gained attention, but they often suffer from imbalanced clusters, sensitivity to initialization, and local optima due to their reliance on the KL-divergence-based loss. To overcome this, we propose a novel Deep Evolutionary Time Series Clustering (DETC) method, which uses an evolutionary search process, generating diverse candidate solutions in each iteration. These solutions are evaluated using a fitness function based on internal validation metrics in both raw time series and latent spaces. This enhances robustness and avoids sub-optimal solutions, leading to more stable and accurate clustering. DETC employs autoencoders for latent representation, but without proper constraints, models may learn poor representations, resulting in local optima, slow convergence, instability, and sensitivity to noise. To learn discriminative representations, DETC introduces a graph-regularized loss that preserves the topological structure of time series in both latent and reconstructed spaces. We conducted extensive experiments on 15 diverse time series datasets, including varying sample sizes, cluster counts, and sequence lengths for a comprehensive assessment. Experimental results demonstrate that DETC significantly outperforms existing state-of-the-art DTC benchmarks, showing its superior clustering performance and robustness. Among 11 compared methods, DETC obtains an average rank of 1.47 and leads to an average improvement of 11% in NMI compared to the best benchmark model. The code and data are available at: https://anonymous.4open.science/r/Deep-Evolutionary-Time-Series-Clustering-DETC-DD2D/README.md.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Information Processing & Management
工程技术-计算机:信息系统
CiteScore
17.00
自引率
11.60%
发文量
276
审稿时长
39 days
期刊介绍:
Information Processing and Management is dedicated to publishing cutting-edge original research at the convergence of computing and information science. Our scope encompasses theory, methods, and applications across various domains, including advertising, business, health, information science, information technology marketing, and social computing.
We aim to cater to the interests of both primary researchers and practitioners by offering an effective platform for the timely dissemination of advanced and topical issues in this interdisciplinary field. The journal places particular emphasis on original research articles, research survey articles, research method articles, and articles addressing critical applications of research. Join us in advancing knowledge and innovation at the intersection of computing and information science.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


