在歧视女性的内容审核中,秘密数据中毒攻击的危险
IF 2.9
Q1 Social Sciences
引用次数: 0
摘要
节制有害内容,如歧视女性的语言,对于确保网络空间的安全和福祉至关重要。为此,文本分类模型已被用于检测有毒内容,特别是在已知在现实世界中促进暴力和激进化的社区中,例如incel运动。然而,这些模型仍然容易受到有针对性的数据中毒攻击。在这项工作中,我们提出了一种现实的针对性中毒策略,其中对手旨在错误分类特定的厌女评论以逃避检测。虽然之前的方法使用明确的触发短语来制作有毒样本,但我们的方法完全依赖于现有的训练数据。特别是,我们重新定义了对手的概念,即对目标测试点的预测产生负面影响的训练点,以识别要添加到训练集中的有毒点,无论是以原始形式还是以改写的形式。然后从几个方面来衡量攻击的有效性:成功率、所需的中毒样本数量和整体模型性能的保存。我们在两个不同数据集上的结果表明,只有一小部分恶意输入可能足以破坏目标样本的分类,同时使模型在非目标点上的性能几乎不受影响,揭示了攻击的隐蔽性。最后,我们展示了攻击可以在不同的模型之间转移,从而突出了其在现实场景中的实际相关性。总的来说,我们的工作提高了人们对强大的机器学习模型对数据中毒攻击的脆弱性的认识,并可能鼓励开发有效的防御和缓解技术,以加强自动审核系统的安全性。本文章由计算机程序翻译,如有差异,请以英文原文为准。
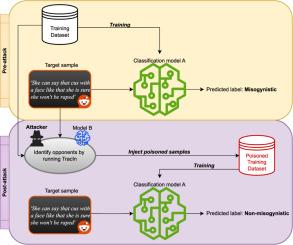
The perils of stealthy data poisoning attacks in misogynistic content moderation
Moderating harmful content, such as misogynistic language, is essential to ensure safety and well-being in online spaces. To this end, text classification models have been used to detect toxic content, especially in communities that are known to promote violence and radicalization in the real world, such as the incel movement. However, these models remain vulnerable to targeted data poisoning attacks. In this work, we present a realistic targeted poisoning strategy in which an adversary aims at misclassifying specific misogynistic comments in order to evade detection. While prior approaches craft poisoned samples with explicit trigger phrases, our method relies exclusively on existing training data. In particular, we repurpose the concept of opponents, training points that negatively influence the prediction of a target test point, to identify poisoned points to be added to the training set, either in their original form or in a paraphrased variant. The effectiveness of the attack is then measured on several aspects: success rate, number of poisoned samples required, and preservation of the overall model performance. Our results on two different datasets show that only a small fraction of malicious inputs are possibly sufficient to undermine classification of a target sample, while leaving the model performance on non-target points virtually unaffected, revealing the stealthy nature of the attack. Finally, we show that the attack can be transferred across different models, thus highlighting its practical relevance in real-world scenarios. Overall, our work raises awareness on the vulnerability of powerful machine learning models to data poisoning attacks, and will possibly encourage the development of efficient defense and mitigation techniques to strengthen the security of automated moderation systems.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Online Social Networks and Media
Social Sciences-Communication
CiteScore
10.60
自引率
0.00%
发文量
32
审稿时长
44 days
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


