一种新的鉴别细粒度特征提取方法来改善视网膜血管分割
IF 4.2
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
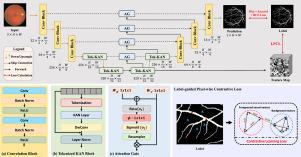
视网膜血管分割是几种严重眼病的重要早期检测方法。尽管神经网络在视网膜血管分割方面取得了重大进展,但仍有许多挑战需要克服。具体来说,视网膜血管分割旨在预测眼底图像中每个像素的类别标签,主要关注图像内的区分,这对于模型提取更多的区分特征至关重要。然而,现有的方法主要侧重于最小化解码器和标签输出之间的差异,而忽略了充分利用编码器的特征级细粒度表示。为了解决这些问题,我们提出了一种新颖的注意力u形Kolmogorov-Arnold网络,名为AttUKAN,以及一种新颖的标签引导的像素级对比度损失,用于视网膜血管分割。具体来说,我们在Kolmogorov-Arnold网络中实现了注意力门,通过抑制无关特征激活来提高模型灵敏度,并通过KAN块的非线性建模来提高模型的可解释性。此外,我们还设计了一种新颖的标签引导的像素对比损失来监督我们提出的AttUKAN,通过区分前景容器像素对和背景像素对来提取更多的判别特征。实验在四个公共数据集上进行,包括DRIVE, STARE, CHASE_DB1, HRF和我们的私有数据集。AttUKAN在上述数据集上的F1得分分别为82.50%、81.14%、81.34%、80.21%和80.09%,MIoU得分分别为70.24%、68.64%、68.59%、67.21%和66.94%,是11种视网膜血管分割网络中得分最高的。定量和定性结果表明,我们的AttUKAN达到了最先进的性能,优于现有的视网膜血管分割方法。我们的代码可以在https://github.com/stevezs315/AttUKAN上找到。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Novel extraction of discriminative fine-grained feature to improve retinal vessel segmentation
Retinal vessel segmentation is a vital early detection method for several severe ocular diseases. Despite significant progress in retinal vessel segmentation with the advancement of Neural Networks, there are still challenges to overcome. Specifically, retinal vessel segmentation aims to predict the class label for every pixel within a fundus image, with a primary focus on intra-image discrimination, making it vital for models to extract more discriminative features. Nevertheless, existing methods primarily focus on minimizing the difference between the output from the decoder and the label, but ignore fully using feature-level fine-grained representations from the encoder. To address these issues, we propose a novel Attention U-shaped Kolmogorov–Arnold Network named AttUKAN along with a novel Label-guided Pixel-wise Contrastive Loss for retinal vessel segmentation. Specifically, we implement Attention Gates into Kolmogorov–Arnold Networks to enhance model sensitivity by suppressing irrelevant feature activations and model interpretability by non-linear modeling of KAN blocks. Additionally, we also design a novel Label-guided Pixel-wise Contrastive Loss to supervise our proposed AttUKAN to extract more discriminative features by distinguishing between foreground vessel-pixel pairs and background pairs. Experiments are conducted across four public datasets including DRIVE, STARE, CHASE_DB1, HRF and our private dataset. AttUKAN achieves F1 scores of 82.50%, 81.14%, 81.34%, 80.21% and 80.09%, along with MIoU scores of 70.24%, 68.64%, 68.59%, 67.21% and 66.94% in the above datasets, which are the highest compared to 11 networks for retinal vessel segmentation. Quantitative and qualitative results show that our AttUKAN achieves state-of-the-art performance and outperforms existing retinal vessel segmentation methods. Our code will be available at https://github.com/stevezs315/AttUKAN.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Image and Vision Computing
工程技术-工程:电子与电气
CiteScore
8.50
自引率
8.50%
发文量
143
审稿时长
7.8 months
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


