Brian Johnson, Tyler Bath, Xinyi Huang, Mark Lamm, Ashley Earles, Hyrum Eddington, Anna M Dornisch, Lily J Jih, Samir Gupta, Shailja C Shah, Kit Curtius
{"title":"从电子健康记录中提取结直肠癌和不典型增生的组织病理学诊断的大型语言模型。","authors":"Brian Johnson, Tyler Bath, Xinyi Huang, Mark Lamm, Ashley Earles, Hyrum Eddington, Anna M Dornisch, Lily J Jih, Samir Gupta, Shailja C Shah, Kit Curtius","doi":"10.1136/bmjgast-2025-001896","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>Accurate data resources are essential for impactful medical research, but available structured datasets are often incomplete or inaccurate. Recent advances in open-weight large language models (LLMs) enable more accurate data extraction from unstructured text in electronic health records (EHRs), however, thorough validation of such approaches is lacking. Our objective was to create a validated approach using LLMs for identifying histopathologic diagnoses in pathology reports from the nationwide Veterans Health Administration (VHA) database, including patients with genotype data within the Million Veteran Program (MVP) biobank.</p><p><strong>Methods: </strong>Our approach utilises search term filtering followed by simple 'yes/no' question prompts for the following phenotypes of interest: any colorectal dysplasia, high-grade dysplasia and/or colorectal adenocarcinoma (HGD/CRC) and invasive CRC. We first developed the LLM prompts using example reports from patients with inflammatory bowel disease (IBD). We then validated the approach in IBD and non-IBD by applying the fixed prompts to a separate corpus of 116 373 pathology reports generated in the VHA between 1999 and 2024. We compared model outputs to blinded manual chart review of 200-300 pathology reports for each patient cohort and diagnostic task, totalling 3816 reviewed reports, and calculated F1 scores as a balanced accuracy measure.</p><p><strong>Results: </strong>In patients with IBD in MVP, we achieved F1-scores of 96.9% (95% CI 94.0% to 99.6%) for identifying dysplasia, 93.7% (88.2%-98.4%) for identifying HGD/CRC and 98% (96.3%-99.4%) for identifying CRC. In patients without IBD in MVP, we achieved F1-scores of 99.2% (98.2%-100%) for identifying any colorectal dysplasia, 96.5% (93.0%-99.2%) for identifying HGD/CRC and 95% (92.8%-97.2%) for identifying CRC using LLM Gemma-2.</p><p><strong>Conclusion: </strong>LLMs provided excellent accuracy in extracting the diagnoses of interest from EHRs. Our validated methods generalised to unstructured pathology notes, even withstanding challenges of resource-limited computing environments. This may, therefore, be a promising approach for other clinical phenotypes given the minimal human-led development required.</p>","PeriodicalId":9235,"journal":{"name":"BMJ Open Gastroenterology","volume":"12 1","pages":""},"PeriodicalIF":2.9000,"publicationDate":"2025-09-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12458811/pdf/","citationCount":"0","resultStr":"{\"title\":\"Large language models for extracting histopathologic diagnoses of colorectal cancer and dysplasia from electronic health records.\",\"authors\":\"Brian Johnson, Tyler Bath, Xinyi Huang, Mark Lamm, Ashley Earles, Hyrum Eddington, Anna M Dornisch, Lily J Jih, Samir Gupta, Shailja C Shah, Kit Curtius\",\"doi\":\"10.1136/bmjgast-2025-001896\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>Accurate data resources are essential for impactful medical research, but available structured datasets are often incomplete or inaccurate. Recent advances in open-weight large language models (LLMs) enable more accurate data extraction from unstructured text in electronic health records (EHRs), however, thorough validation of such approaches is lacking. Our objective was to create a validated approach using LLMs for identifying histopathologic diagnoses in pathology reports from the nationwide Veterans Health Administration (VHA) database, including patients with genotype data within the Million Veteran Program (MVP) biobank.</p><p><strong>Methods: </strong>Our approach utilises search term filtering followed by simple 'yes/no' question prompts for the following phenotypes of interest: any colorectal dysplasia, high-grade dysplasia and/or colorectal adenocarcinoma (HGD/CRC) and invasive CRC. We first developed the LLM prompts using example reports from patients with inflammatory bowel disease (IBD). We then validated the approach in IBD and non-IBD by applying the fixed prompts to a separate corpus of 116 373 pathology reports generated in the VHA between 1999 and 2024. We compared model outputs to blinded manual chart review of 200-300 pathology reports for each patient cohort and diagnostic task, totalling 3816 reviewed reports, and calculated F1 scores as a balanced accuracy measure.</p><p><strong>Results: </strong>In patients with IBD in MVP, we achieved F1-scores of 96.9% (95% CI 94.0% to 99.6%) for identifying dysplasia, 93.7% (88.2%-98.4%) for identifying HGD/CRC and 98% (96.3%-99.4%) for identifying CRC. In patients without IBD in MVP, we achieved F1-scores of 99.2% (98.2%-100%) for identifying any colorectal dysplasia, 96.5% (93.0%-99.2%) for identifying HGD/CRC and 95% (92.8%-97.2%) for identifying CRC using LLM Gemma-2.</p><p><strong>Conclusion: </strong>LLMs provided excellent accuracy in extracting the diagnoses of interest from EHRs. Our validated methods generalised to unstructured pathology notes, even withstanding challenges of resource-limited computing environments. This may, therefore, be a promising approach for other clinical phenotypes given the minimal human-led development required.</p>\",\"PeriodicalId\":9235,\"journal\":{\"name\":\"BMJ Open Gastroenterology\",\"volume\":\"12 1\",\"pages\":\"\"},\"PeriodicalIF\":2.9000,\"publicationDate\":\"2025-09-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12458811/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMJ Open Gastroenterology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1136/bmjgast-2025-001896\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"GASTROENTEROLOGY & HEPATOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Open Gastroenterology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjgast-2025-001896","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"GASTROENTEROLOGY & HEPATOLOGY","Score":null,"Total":0}
引用次数: 0
摘要
目的:准确的数据资源对于有影响力的医学研究至关重要,但现有的结构化数据集往往不完整或不准确。开放权重大语言模型(llm)的最新进展能够从电子健康记录(EHRs)中的非结构化文本中更准确地提取数据,然而,缺乏对此类方法的彻底验证。我们的目标是创建一种有效的方法,使用法学硕士来识别来自全国退伍军人健康管理局(VHA)数据库的病理报告中的组织病理学诊断,包括百万退伍军人计划(MVP)生物银行中基因型数据的患者。方法:我们的方法使用搜索词过滤,然后是简单的“是/否”问题提示,用于以下感兴趣的表型:任何结直肠不典型增生,高级别不典型增生和/或结直肠腺癌(HGD/CRC)和侵袭性结直肠癌。我们首先利用炎症性肠病(IBD)患者的示例报告开发了LLM提示。然后,我们通过将固定提示应用于1999年至2024年间VHA生成的116 373份病理报告的单独语料库,在IBD和非IBD中验证了该方法。我们将模型输出与每个患者队列和诊断任务的200-300份病理报告的盲法手工图表审查进行了比较,共审查了3816份报告,并计算了F1分数作为平衡的准确性衡量标准。结果:在MVP的IBD患者中,我们获得了鉴别非典型增生的96.9% (95% CI 94.0% - 99.6%)的f1评分,鉴别HGD/CRC的93.7%(88.2%-98.4%),鉴别CRC的98%(96.3%-99.4%)的f1评分。在MVP无IBD的患者中,我们使用LLM Gemma-2识别任何结直肠异常增生的f1得分为99.2%(98.2%-100%),识别HGD/CRC的f1得分为96.5%(93.0%-99.2%),识别CRC的f1得分为95%(92.8%-97.2%)。结论:llm在从电子病历中提取感兴趣的诊断方面具有很高的准确性。我们的验证方法推广到非结构化的病理记录,即使面临资源有限的计算环境的挑战。因此,这可能是一个有希望的方法,为其他临床表型考虑到最小的人为主导的发展所需。
Large language models for extracting histopathologic diagnoses of colorectal cancer and dysplasia from electronic health records.
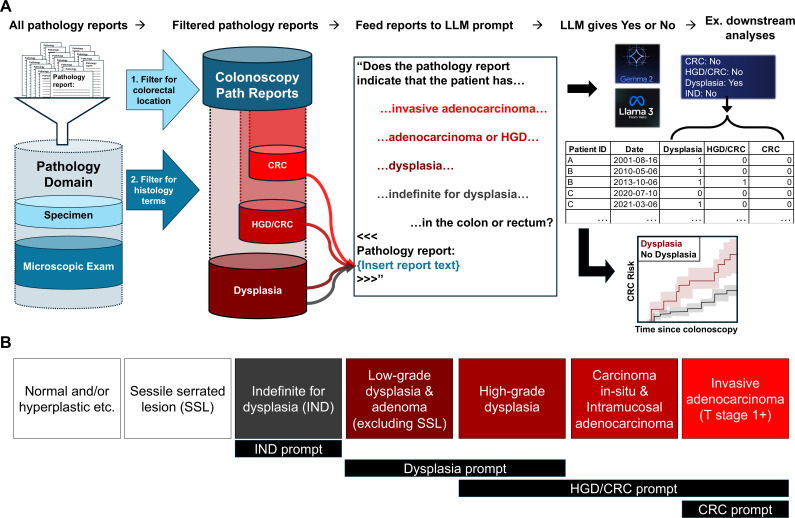
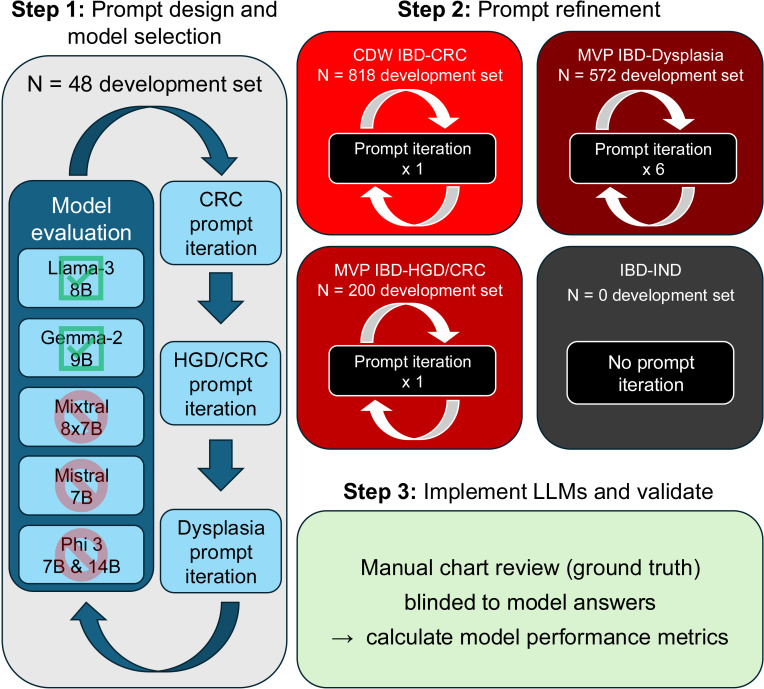
Objective: Accurate data resources are essential for impactful medical research, but available structured datasets are often incomplete or inaccurate. Recent advances in open-weight large language models (LLMs) enable more accurate data extraction from unstructured text in electronic health records (EHRs), however, thorough validation of such approaches is lacking. Our objective was to create a validated approach using LLMs for identifying histopathologic diagnoses in pathology reports from the nationwide Veterans Health Administration (VHA) database, including patients with genotype data within the Million Veteran Program (MVP) biobank.
Methods: Our approach utilises search term filtering followed by simple 'yes/no' question prompts for the following phenotypes of interest: any colorectal dysplasia, high-grade dysplasia and/or colorectal adenocarcinoma (HGD/CRC) and invasive CRC. We first developed the LLM prompts using example reports from patients with inflammatory bowel disease (IBD). We then validated the approach in IBD and non-IBD by applying the fixed prompts to a separate corpus of 116 373 pathology reports generated in the VHA between 1999 and 2024. We compared model outputs to blinded manual chart review of 200-300 pathology reports for each patient cohort and diagnostic task, totalling 3816 reviewed reports, and calculated F1 scores as a balanced accuracy measure.
Results: In patients with IBD in MVP, we achieved F1-scores of 96.9% (95% CI 94.0% to 99.6%) for identifying dysplasia, 93.7% (88.2%-98.4%) for identifying HGD/CRC and 98% (96.3%-99.4%) for identifying CRC. In patients without IBD in MVP, we achieved F1-scores of 99.2% (98.2%-100%) for identifying any colorectal dysplasia, 96.5% (93.0%-99.2%) for identifying HGD/CRC and 95% (92.8%-97.2%) for identifying CRC using LLM Gemma-2.
Conclusion: LLMs provided excellent accuracy in extracting the diagnoses of interest from EHRs. Our validated methods generalised to unstructured pathology notes, even withstanding challenges of resource-limited computing environments. This may, therefore, be a promising approach for other clinical phenotypes given the minimal human-led development required.
期刊介绍:
BMJ Open Gastroenterology is an online-only, peer-reviewed, open access gastroenterology journal, dedicated to publishing high-quality medical research from all disciplines and therapeutic areas of gastroenterology. It is the open access companion journal of Gut and is co-owned by the British Society of Gastroenterology. The journal publishes all research study types, from study protocols to phase I trials to meta-analyses, including small or specialist studies. Publishing procedures are built around continuous publication, publishing research online as soon as the article is ready.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


