Aleksandra Edwards, Antonio F Pardiñas, George Kirov, Elliott Rees, Jose Camacho-Collados
{"title":"临床自由文本摘要中大语言模型支持的智力残疾识别:混合方法研究。","authors":"Aleksandra Edwards, Antonio F Pardiñas, George Kirov, Elliott Rees, Jose Camacho-Collados","doi":"10.2196/72256","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Free-text clinical data are unstructured and narrative in nature, providing a rich source of patient information, but extracting research-quality clinical phenotypes from these data remains a challenge. Manually reviewing and extracting clinical phenotypes from free-text patient notes is a time-consuming process and not suitable for large-scale datasets. On the other hand, automatically extracting clinical phenotypes can be challenging because medical researchers lack gold-standard annotated references and other purpose-built resources, including software. Recent large language models (LLMs) can understand natural language instructions, which help them adapt to different domains and tasks without the need for specific training data. This makes them suitable for clinical applications, though their use in this field is limited.</p><p><strong>Objective: </strong>We aimed to develop an LLM pipeline based on the few-shot learning framework that could extract clinical information from free-text clinical summaries. We assessed the performance of this pipeline for classifying individuals with confirmed or suspected comorbid intellectual disability (ID) from clinical summaries of patients with severe mental illness and performed genetic validation of the results by testing whether individuals with LLM-defined ID carried more genetic variants known to confer risk of ID when compared with individuals without LLM-defined ID.</p><p><strong>Methods: </strong>We developed novel approaches for performing classification, based on an intermediate information extraction (IE) step and human-in-the-loop techniques. We evaluated two models: Fine-Tuned Language Text-To-Text Transfer Transformer (Flan-T5) and Large Language Model Architecture (LLaMA). The dataset comprised 1144 free-text clinical summaries, of which 314 were manually annotated and used as a gold standard for evaluating automated methods. We also used published genetic data from 547 individuals to perform a genetic validation of the classification results; Firth's penalized logistic regression framework was used to test whether individuals with LLM-defined ID carry significantly more de novo variants in known developmental disorder risk genes than individuals without LLM-defined ID.</p><p><strong>Results: </strong>The results demonstrate that a 2-stage approach, combining IE with manual validation, can effectively identify individuals with suspected IDs from free-text patient records, requiring only a single training example per classification label. The best-performing method based on the Flan-T5 model and incorporating the IE step achieved an F1-score of 0.867. Individuals classified as having ID by the best performing model were significantly enriched for de novo variants in known developmental disorder risk genes (odds ratio 29.1, 95% CI 7.36-107; P=2.1×10-5).</p><p><strong>Conclusions: </strong>LLMs and in-context learning techniques combined with human-in-the-loop approaches can be highly beneficial for extraction and categorization of information from free-text clinical data. In this proof-of-concept study, we show that LLMs can be used to identify individuals with a severe mental illness who also have suspected ID, which is a biologically and clinically meaningful subgroup of patients.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e72256"},"PeriodicalIF":2.0000,"publicationDate":"2025-09-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12445779/pdf/","citationCount":"0","resultStr":"{\"title\":\"Large Language Model-Supported Identification of Intellectual Disabilities in Clinical Free-Text Summaries: Mixed Methods Study.\",\"authors\":\"Aleksandra Edwards, Antonio F Pardiñas, George Kirov, Elliott Rees, Jose Camacho-Collados\",\"doi\":\"10.2196/72256\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Free-text clinical data are unstructured and narrative in nature, providing a rich source of patient information, but extracting research-quality clinical phenotypes from these data remains a challenge. Manually reviewing and extracting clinical phenotypes from free-text patient notes is a time-consuming process and not suitable for large-scale datasets. On the other hand, automatically extracting clinical phenotypes can be challenging because medical researchers lack gold-standard annotated references and other purpose-built resources, including software. Recent large language models (LLMs) can understand natural language instructions, which help them adapt to different domains and tasks without the need for specific training data. This makes them suitable for clinical applications, though their use in this field is limited.</p><p><strong>Objective: </strong>We aimed to develop an LLM pipeline based on the few-shot learning framework that could extract clinical information from free-text clinical summaries. We assessed the performance of this pipeline for classifying individuals with confirmed or suspected comorbid intellectual disability (ID) from clinical summaries of patients with severe mental illness and performed genetic validation of the results by testing whether individuals with LLM-defined ID carried more genetic variants known to confer risk of ID when compared with individuals without LLM-defined ID.</p><p><strong>Methods: </strong>We developed novel approaches for performing classification, based on an intermediate information extraction (IE) step and human-in-the-loop techniques. We evaluated two models: Fine-Tuned Language Text-To-Text Transfer Transformer (Flan-T5) and Large Language Model Architecture (LLaMA). The dataset comprised 1144 free-text clinical summaries, of which 314 were manually annotated and used as a gold standard for evaluating automated methods. We also used published genetic data from 547 individuals to perform a genetic validation of the classification results; Firth's penalized logistic regression framework was used to test whether individuals with LLM-defined ID carry significantly more de novo variants in known developmental disorder risk genes than individuals without LLM-defined ID.</p><p><strong>Results: </strong>The results demonstrate that a 2-stage approach, combining IE with manual validation, can effectively identify individuals with suspected IDs from free-text patient records, requiring only a single training example per classification label. The best-performing method based on the Flan-T5 model and incorporating the IE step achieved an F1-score of 0.867. Individuals classified as having ID by the best performing model were significantly enriched for de novo variants in known developmental disorder risk genes (odds ratio 29.1, 95% CI 7.36-107; P=2.1×10-5).</p><p><strong>Conclusions: </strong>LLMs and in-context learning techniques combined with human-in-the-loop approaches can be highly beneficial for extraction and categorization of information from free-text clinical data. In this proof-of-concept study, we show that LLMs can be used to identify individuals with a severe mental illness who also have suspected ID, which is a biologically and clinically meaningful subgroup of patients.</p>\",\"PeriodicalId\":73551,\"journal\":{\"name\":\"JMIR AI\",\"volume\":\"4 \",\"pages\":\"e72256\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-09-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12445779/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/72256\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/72256","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
背景:自由文本临床数据是非结构化的,本质上是叙述性的,提供了丰富的患者信息来源,但从这些数据中提取研究质量的临床表型仍然是一个挑战。从自由文本患者笔记中手动审查和提取临床表型是一个耗时的过程,不适合大规模数据集。另一方面,自动提取临床表型可能具有挑战性,因为医学研究人员缺乏黄金标准的注释参考文献和其他专用资源,包括软件。最近的大型语言模型(llm)可以理解自然语言指令,这有助于它们适应不同的领域和任务,而不需要特定的训练数据。这使得它们适合临床应用,尽管它们在这一领域的使用是有限的。目的:我们旨在开发一个基于few-shot学习框架的LLM管道,该框架可以从自由文本临床摘要中提取临床信息。我们评估了从严重精神疾病患者的临床摘要中对确诊或疑似共病性智力残疾(ID)个体进行分类的管道的性能,并通过测试与没有llm定义的ID的个体相比,llm定义的ID的个体是否携带更多已知赋予ID风险的遗传变异来对结果进行遗传验证。方法:我们开发了新的方法来执行分类,基于中间信息提取(IE)步骤和人在环技术。我们评估了两个模型:微调语言文本到文本传输转换器(Flan-T5)和大型语言模型架构(LLaMA)。该数据集包括1144个自由文本临床摘要,其中314个是手动注释的,并用作评估自动化方法的金标准。我们还使用来自547个个体的已发表遗传数据对分类结果进行遗传验证;Firth的惩罚逻辑回归框架被用于测试具有llm定义ID的个体是否比没有llm定义ID的个体携带更多已知发育障碍风险基因的新生变异。结果:结果表明,将IE与人工验证相结合的两阶段方法可以有效地从自由文本病历中识别出可疑id的个体,每个分类标签只需要一个训练示例。基于Flan-T5模型并结合IE步骤的最佳方法的f1得分为0.867。被表现最好的模型分类为ID的个体在已知发育障碍风险基因的新生变异中显著富集(优势比29.1,95% CI 7.36-107; P=2.1×10-5)。结论:llm和上下文学习技术结合human-in-the-loop方法对于从自由文本临床数据中提取和分类信息非常有益。在这项概念验证研究中,我们表明llm可以用来识别患有严重精神疾病的个体,他们也有疑似ID,这是一个生物学和临床意义的患者亚组。
Large Language Model-Supported Identification of Intellectual Disabilities in Clinical Free-Text Summaries: Mixed Methods Study.
Background: Free-text clinical data are unstructured and narrative in nature, providing a rich source of patient information, but extracting research-quality clinical phenotypes from these data remains a challenge. Manually reviewing and extracting clinical phenotypes from free-text patient notes is a time-consuming process and not suitable for large-scale datasets. On the other hand, automatically extracting clinical phenotypes can be challenging because medical researchers lack gold-standard annotated references and other purpose-built resources, including software. Recent large language models (LLMs) can understand natural language instructions, which help them adapt to different domains and tasks without the need for specific training data. This makes them suitable for clinical applications, though their use in this field is limited.
Objective: We aimed to develop an LLM pipeline based on the few-shot learning framework that could extract clinical information from free-text clinical summaries. We assessed the performance of this pipeline for classifying individuals with confirmed or suspected comorbid intellectual disability (ID) from clinical summaries of patients with severe mental illness and performed genetic validation of the results by testing whether individuals with LLM-defined ID carried more genetic variants known to confer risk of ID when compared with individuals without LLM-defined ID.
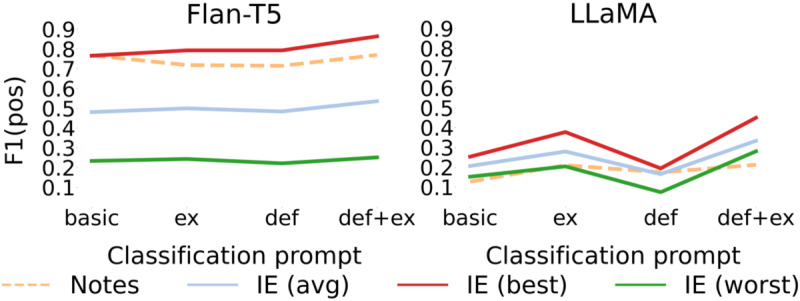
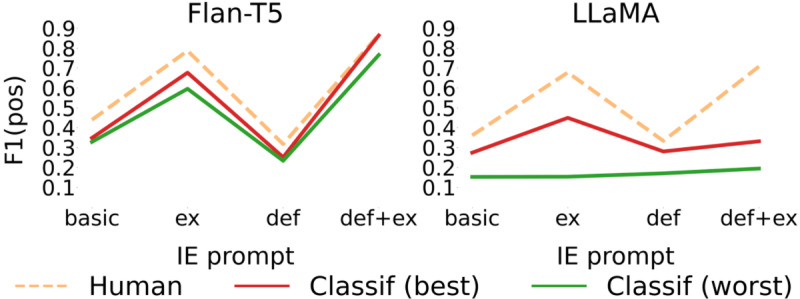
Methods: We developed novel approaches for performing classification, based on an intermediate information extraction (IE) step and human-in-the-loop techniques. We evaluated two models: Fine-Tuned Language Text-To-Text Transfer Transformer (Flan-T5) and Large Language Model Architecture (LLaMA). The dataset comprised 1144 free-text clinical summaries, of which 314 were manually annotated and used as a gold standard for evaluating automated methods. We also used published genetic data from 547 individuals to perform a genetic validation of the classification results; Firth's penalized logistic regression framework was used to test whether individuals with LLM-defined ID carry significantly more de novo variants in known developmental disorder risk genes than individuals without LLM-defined ID.
Results: The results demonstrate that a 2-stage approach, combining IE with manual validation, can effectively identify individuals with suspected IDs from free-text patient records, requiring only a single training example per classification label. The best-performing method based on the Flan-T5 model and incorporating the IE step achieved an F1-score of 0.867. Individuals classified as having ID by the best performing model were significantly enriched for de novo variants in known developmental disorder risk genes (odds ratio 29.1, 95% CI 7.36-107; P=2.1×10-5).
Conclusions: LLMs and in-context learning techniques combined with human-in-the-loop approaches can be highly beneficial for extraction and categorization of information from free-text clinical data. In this proof-of-concept study, we show that LLMs can be used to identify individuals with a severe mental illness who also have suspected ID, which is a biologically and clinically meaningful subgroup of patients.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


