Haemin Lee, Sooyoung Yoo, Joonghee Kim, Youngjin Cho, Dongbum Suh, Keehyuck Lee
{"title":"多模态大语言模型与专用心电图AI在从心电图图像检测心肌梗死中的比较诊断性能:比较研究。","authors":"Haemin Lee, Sooyoung Yoo, Joonghee Kim, Youngjin Cho, Dongbum Suh, Keehyuck Lee","doi":"10.2196/75910","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Accurate and timely electrocardiogram (ECG) interpretation is critical for diagnosing myocardial infarction (MI) in emergency settings. Recent advances in multimodal large language models (LLMs), such as ChatGPT (OpenAI) and Gemini (Google DeepMind), have shown promise in clinical interpretation for medical imaging. However, whether these models analyze waveform patterns or simply rely on text cues remains unclear, underscoring the need for direct comparisons with dedicated ECG artificial intelligence (AI) tools.</p><p><strong>Objective: </strong>This study aimed to evaluate the diagnostic performance of ChatGPT and Gemini, a general-purpose LLM, in detecting MI from ECG images and to compare its performance with that of ECG Buddy (ARPI Inc), a dedicated AI-driven ECG analysis tool.</p><p><strong>Methods: </strong>This retrospective study evaluated and compared AI models for classifying MI using a publicly available 12-lead ECG dataset from Pakistan, categorizing cases into MI-positive (239 images) and MI-negative (689 images). ChatGPT (GPT-4o, version November 20, 2024) and Gemini (Gemini 2.5 pro) were queried with 5 MI confidence options, whereas ECG Buddy for Microsoft Windows analyzed the images based on ST-elevation MI, acute coronary syndrome, and myocardial injury biomarkers.</p><p><strong>Results: </strong>Among 928 ECG recordings (239/928, 25.8% MI-positive), ChatGPT achieved an accuracy of 65.95% (95% CI 62.80-69.00), area under the curve (AUC) of 57.34% (95% CI 53.44-61.24), sensitivity of 36.40% (95% CI 30.30-42.85), and specificity of 76.2% (95% CI 72.84-79.33). With Gemini 2.5 Pro, accuracy dropped to 29.63% (95% CI 26.71-32.69), AUC to 51.63% (95% CI 50.22-53.04), and sensitivity rose to 97.07% (95% CI 94.06-98.81), but specificity fell sharply to 6.24% (95% CI 4.55-8.31). However, ECG Buddy reached an accuracy of 96.98% (95% CI 95.67-97.99), AUC of 98.8% (95% CI 98.3-99.43), sensitivity of 96.65% (95% CI 93.51-98.54), and specificity of 97.10% (95% CI 95.55-98.22). DeLong test confirmed that ECG Buddy significantly outperformed ChatGPT (all P<.001). In a qualitative error analysis of LLMs' diagnostic explanations, GPT-4o produced fully accurate explanations in only 5% of cases (2/40), was partially accurate in 38% (15/40), and completely inaccurate in 58% (23/40). By contrast, Gemini 2.5 Pro yielded fully accurate explanations in 32% of cases (12/37), was partially accurate in 14% (5/37), and completely inaccurate in 54% (20/37).</p><p><strong>Conclusions: </strong>LLMs, such as ChatGPT and Gemini, underperform relative to specialized tools such as ECG Buddy in ECG image-based MI diagnosis. Further training may improve LLMs; however, domain-specific AI remains essential for clinical accuracy. The high performance of ECG Buddy underscores the importance of specialized models for achieving reliable and robust diagnostic outcomes.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e75910"},"PeriodicalIF":2.0000,"publicationDate":"2025-09-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12443349/pdf/","citationCount":"0","resultStr":"{\"title\":\"Comparative Diagnostic Performance of a Multimodal Large Language Model Versus a Dedicated Electrocardiogram AI in Detecting Myocardial Infarction From Electrocardiogram Images: Comparative Study.\",\"authors\":\"Haemin Lee, Sooyoung Yoo, Joonghee Kim, Youngjin Cho, Dongbum Suh, Keehyuck Lee\",\"doi\":\"10.2196/75910\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Accurate and timely electrocardiogram (ECG) interpretation is critical for diagnosing myocardial infarction (MI) in emergency settings. Recent advances in multimodal large language models (LLMs), such as ChatGPT (OpenAI) and Gemini (Google DeepMind), have shown promise in clinical interpretation for medical imaging. However, whether these models analyze waveform patterns or simply rely on text cues remains unclear, underscoring the need for direct comparisons with dedicated ECG artificial intelligence (AI) tools.</p><p><strong>Objective: </strong>This study aimed to evaluate the diagnostic performance of ChatGPT and Gemini, a general-purpose LLM, in detecting MI from ECG images and to compare its performance with that of ECG Buddy (ARPI Inc), a dedicated AI-driven ECG analysis tool.</p><p><strong>Methods: </strong>This retrospective study evaluated and compared AI models for classifying MI using a publicly available 12-lead ECG dataset from Pakistan, categorizing cases into MI-positive (239 images) and MI-negative (689 images). ChatGPT (GPT-4o, version November 20, 2024) and Gemini (Gemini 2.5 pro) were queried with 5 MI confidence options, whereas ECG Buddy for Microsoft Windows analyzed the images based on ST-elevation MI, acute coronary syndrome, and myocardial injury biomarkers.</p><p><strong>Results: </strong>Among 928 ECG recordings (239/928, 25.8% MI-positive), ChatGPT achieved an accuracy of 65.95% (95% CI 62.80-69.00), area under the curve (AUC) of 57.34% (95% CI 53.44-61.24), sensitivity of 36.40% (95% CI 30.30-42.85), and specificity of 76.2% (95% CI 72.84-79.33). With Gemini 2.5 Pro, accuracy dropped to 29.63% (95% CI 26.71-32.69), AUC to 51.63% (95% CI 50.22-53.04), and sensitivity rose to 97.07% (95% CI 94.06-98.81), but specificity fell sharply to 6.24% (95% CI 4.55-8.31). However, ECG Buddy reached an accuracy of 96.98% (95% CI 95.67-97.99), AUC of 98.8% (95% CI 98.3-99.43), sensitivity of 96.65% (95% CI 93.51-98.54), and specificity of 97.10% (95% CI 95.55-98.22). DeLong test confirmed that ECG Buddy significantly outperformed ChatGPT (all P<.001). In a qualitative error analysis of LLMs' diagnostic explanations, GPT-4o produced fully accurate explanations in only 5% of cases (2/40), was partially accurate in 38% (15/40), and completely inaccurate in 58% (23/40). By contrast, Gemini 2.5 Pro yielded fully accurate explanations in 32% of cases (12/37), was partially accurate in 14% (5/37), and completely inaccurate in 54% (20/37).</p><p><strong>Conclusions: </strong>LLMs, such as ChatGPT and Gemini, underperform relative to specialized tools such as ECG Buddy in ECG image-based MI diagnosis. Further training may improve LLMs; however, domain-specific AI remains essential for clinical accuracy. The high performance of ECG Buddy underscores the importance of specialized models for achieving reliable and robust diagnostic outcomes.</p>\",\"PeriodicalId\":73551,\"journal\":{\"name\":\"JMIR AI\",\"volume\":\"4 \",\"pages\":\"e75910\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-09-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12443349/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/75910\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/75910","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
背景:准确和及时的心电图(ECG)解释对于急诊诊断心肌梗死(MI)至关重要。最近在多模态大型语言模型(llm)方面的进展,如ChatGPT (OpenAI)和Gemini(谷歌DeepMind),在医学成像的临床解释中显示出了希望。然而,这些模型是分析波形模式还是仅仅依赖文本线索尚不清楚,这强调了与专用ECG人工智能(AI)工具进行直接比较的必要性。目的:本研究旨在评估ChatGPT和通用LLM Gemini从心电图像中检测心肌梗死的诊断性能,并将其与专用人工智能心电分析工具ECG Buddy (ARPI Inc)的性能进行比较。方法:本回顾性研究使用巴基斯坦公开的12导联心电图数据集评估和比较了用于心肌梗死分类的AI模型,将病例分为心肌梗死阳性(239张图像)和心肌梗死阴性(689张图像)。ChatGPT (gpt - 40, 2024年11月20日版本)和Gemini (Gemini 2.5 pro)具有5个心肌梗死置信度选项,而ECG Buddy for Microsoft Windows则基于st段抬高心肌梗死、急性冠状动脉综合征和心肌损伤生物标志物分析图像。结果:在928份心电图记录中(239/928,mi阳性25.8%),ChatGPT准确率为65.95% (95% CI 62.80 ~ 69.00),曲线下面积(AUC)为57.34% (95% CI 53.44 ~ 61.24),灵敏度为36.40% (95% CI 30.30 ~ 42.85),特异性为76.2% (95% CI 72.84 ~ 79.33)。使用Gemini 2.5 Pro,准确率降至29.63% (95% CI 26.71-32.69), AUC降至51.63% (95% CI 50.22-53.04),敏感性上升至97.07% (95% CI 94.06-98.81),但特异性急剧下降至6.24% (95% CI 4.55-8.31)。然而,ECG Buddy的准确率为96.98% (95% CI 95.67-97.99), AUC为98.8% (95% CI 983 -99.43),灵敏度为96.65% (95% CI 93.51-98.54),特异性为97.10% (95% CI 95.55-98.22)。DeLong测试证实,ECG Buddy的表现明显优于ChatGPT。结论:在基于心电图像的心梗诊断中,llm(如ChatGPT和Gemini)的表现低于ECG Buddy等专业工具。进一步的培训可以提高法学硕士水平;然而,特定领域的人工智能对于临床准确性仍然至关重要。ECG Buddy的高性能强调了专业模型对于实现可靠和稳健的诊断结果的重要性。
Comparative Diagnostic Performance of a Multimodal Large Language Model Versus a Dedicated Electrocardiogram AI in Detecting Myocardial Infarction From Electrocardiogram Images: Comparative Study.
Background: Accurate and timely electrocardiogram (ECG) interpretation is critical for diagnosing myocardial infarction (MI) in emergency settings. Recent advances in multimodal large language models (LLMs), such as ChatGPT (OpenAI) and Gemini (Google DeepMind), have shown promise in clinical interpretation for medical imaging. However, whether these models analyze waveform patterns or simply rely on text cues remains unclear, underscoring the need for direct comparisons with dedicated ECG artificial intelligence (AI) tools.
Objective: This study aimed to evaluate the diagnostic performance of ChatGPT and Gemini, a general-purpose LLM, in detecting MI from ECG images and to compare its performance with that of ECG Buddy (ARPI Inc), a dedicated AI-driven ECG analysis tool.
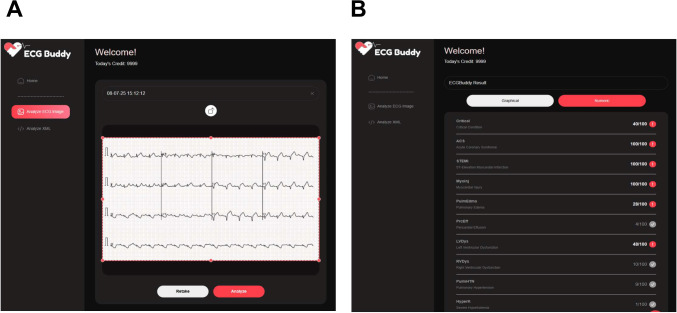
Methods: This retrospective study evaluated and compared AI models for classifying MI using a publicly available 12-lead ECG dataset from Pakistan, categorizing cases into MI-positive (239 images) and MI-negative (689 images). ChatGPT (GPT-4o, version November 20, 2024) and Gemini (Gemini 2.5 pro) were queried with 5 MI confidence options, whereas ECG Buddy for Microsoft Windows analyzed the images based on ST-elevation MI, acute coronary syndrome, and myocardial injury biomarkers.
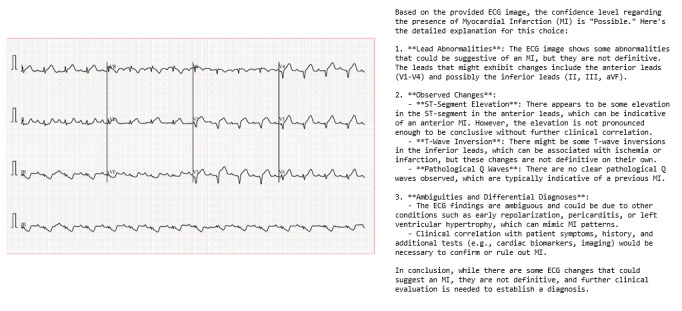
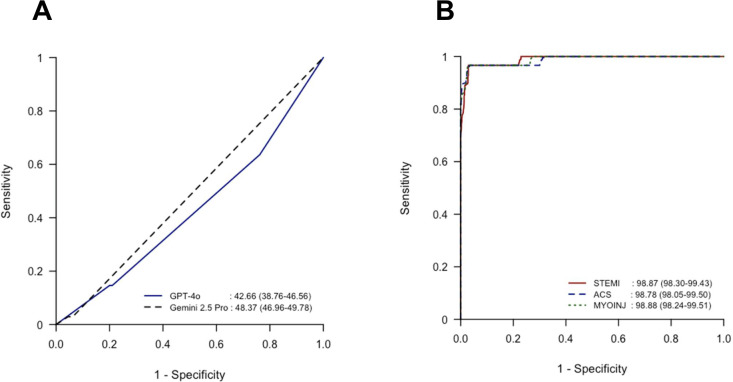
Results: Among 928 ECG recordings (239/928, 25.8% MI-positive), ChatGPT achieved an accuracy of 65.95% (95% CI 62.80-69.00), area under the curve (AUC) of 57.34% (95% CI 53.44-61.24), sensitivity of 36.40% (95% CI 30.30-42.85), and specificity of 76.2% (95% CI 72.84-79.33). With Gemini 2.5 Pro, accuracy dropped to 29.63% (95% CI 26.71-32.69), AUC to 51.63% (95% CI 50.22-53.04), and sensitivity rose to 97.07% (95% CI 94.06-98.81), but specificity fell sharply to 6.24% (95% CI 4.55-8.31). However, ECG Buddy reached an accuracy of 96.98% (95% CI 95.67-97.99), AUC of 98.8% (95% CI 98.3-99.43), sensitivity of 96.65% (95% CI 93.51-98.54), and specificity of 97.10% (95% CI 95.55-98.22). DeLong test confirmed that ECG Buddy significantly outperformed ChatGPT (all P<.001). In a qualitative error analysis of LLMs' diagnostic explanations, GPT-4o produced fully accurate explanations in only 5% of cases (2/40), was partially accurate in 38% (15/40), and completely inaccurate in 58% (23/40). By contrast, Gemini 2.5 Pro yielded fully accurate explanations in 32% of cases (12/37), was partially accurate in 14% (5/37), and completely inaccurate in 54% (20/37).
Conclusions: LLMs, such as ChatGPT and Gemini, underperform relative to specialized tools such as ECG Buddy in ECG image-based MI diagnosis. Further training may improve LLMs; however, domain-specific AI remains essential for clinical accuracy. The high performance of ECG Buddy underscores the importance of specialized models for achieving reliable and robust diagnostic outcomes.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


