{"title":"自动心脏磁共振解释源自提示的大型语言模型。","authors":"Lujing Wang, Liang Peng, Yixuan Wan, Xingyu Li, Yixin Chen, Li Wang, Xiuxian Gong, Xiaoying Zhao, Lequan Yu, Shihua Zhao, Xinxiang Zhao","doi":"10.21037/cdt-2025-112","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The versatility of cardiac magnetic resonance (CMR) leads to complex and time-consuming interpretation. Large language models (LLMs) present transformative potential for automated CMR interpretations. We explored the ability of LLMs in the automated classification and diagnosis of CMR reports for three common cardiac diseases: myocardial infarction (MI), dilated cardiomyopathy (DCM), and hypertrophic cardiomyopathy (HCM).</p><p><strong>Methods: </strong>This retrospective study enrolled CMR reports of consecutive patients from January 2015 to July 2024, including reports from three types of cardiac diseases: MI, DCM, and HCM. Six LLMs, including GPT-3.5, GPT-4.0, Gemini-1.0, Gemini-1.5, PaLM, and LLaMA, were used to classify and diagnose the CMR reports. The results of the LLMs, with minimal or informative prompts, were compared with those of radiologists. Accuracy (ACC) and balanced accuracy (BAC) were used to evaluate the classification performance of the different LLMs. The consistency between radiologists and LLMs in classifying heart disease categories was evaluated using Gwet's Agreement Coefficient (AC1 value). Diagnostic performance was analyzed through receiver operating characteristic (ROC) curves. Cohen's kappa was used to assess the reproducibility of the LLMs' diagnostic results obtained at different time intervals (a 30-day interval).</p><p><strong>Results: </strong>This study enrolled 543 CMR cases, including 275 MI, 120 DCM, and 148 HCM cases. The overall BAC of the minimal prompted LLMs, from highest to lowest, were GPT-4.0, LLaMA, PaLM, GPT-3.5, Gemini-1.5, and Gemini-1.0. The informative prompted models of GPT-3.5 (P<0.001), GPT-4.0 (P<0.001), Gemini-1.0 (P<0.001), Gemini-1.5 (P=0.02), and PaLM (P<0.001) showed significant improvements in overall ACC compared to their minimal prompted models, whereas the informative prompted model of LLaMA did not show a significant improvement in overall ACC compared to the minimal prompted model (P=0.06). GPT-4.0 performed best in both the minimal prompted (ACC =88.6%, BAC =91.7%) and informative prompted (ACC =95.8%, BAC =97.1%) models. GPT-4.0 demonstrated the highest agreement with radiologists [AC1=0.82, 95% confidence interval (CI): 0.78-0.86], significantly outperforming others (P<0.001). For the informative prompted models of LLMs, GPT-4.0 + informative prompt (AC1=0.93, 95% CI: 0.90-0.96), GPT-3.5 + informative prompt (AC1=0.93, 95% CI: 0.90-0.95), Gemini-1.0 + informative prompt (AC1=0.90, 95% CI: 0.87-0.93), PaLM + informative prompt (AC1=0.86, 95% CI: 0.82-0.90), LLaMA + informative prompt (AC1=0.82, 95% CI: 0.78-0.86), and Gemini-1.5 + informative prompt (AC1=0.80, 95% CI: 0.76-0.84) all showed almost perfect agreement with radiologists' diagnoses. Diagnostic performance was excellent for GPT-4.0 [area under the curve (AUC)=0.93, 95% CI: 0.92-0.95] and LLaMA (AUC =0.92, 95% CI: 0.90-0.94) in minimal prompted models, while informative prompted models achieved superior performance, with GPT-4.0 + informative prompt reaching the highest AUC of 0.98 (95% CI: 0.97-0.99). All models demonstrated good reproducibility (κ>0.80, P<0.001).</p><p><strong>Conclusions: </strong>LLMs demonstrated outstanding performance in the automated classification and diagnosis of targeted CMR interpretations, especially with informative prompts, suggesting the potential for these models to serve as adjunct tools in CMR diagnostic workflows.</p>","PeriodicalId":9592,"journal":{"name":"Cardiovascular diagnosis and therapy","volume":"15 4","pages":"726-737"},"PeriodicalIF":2.1000,"publicationDate":"2025-08-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12432601/pdf/","citationCount":"0","resultStr":"{\"title\":\"Automated cardiac magnetic resonance interpretation derived from prompted large language models.\",\"authors\":\"Lujing Wang, Liang Peng, Yixuan Wan, Xingyu Li, Yixin Chen, Li Wang, Xiuxian Gong, Xiaoying Zhao, Lequan Yu, Shihua Zhao, Xinxiang Zhao\",\"doi\":\"10.21037/cdt-2025-112\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The versatility of cardiac magnetic resonance (CMR) leads to complex and time-consuming interpretation. Large language models (LLMs) present transformative potential for automated CMR interpretations. We explored the ability of LLMs in the automated classification and diagnosis of CMR reports for three common cardiac diseases: myocardial infarction (MI), dilated cardiomyopathy (DCM), and hypertrophic cardiomyopathy (HCM).</p><p><strong>Methods: </strong>This retrospective study enrolled CMR reports of consecutive patients from January 2015 to July 2024, including reports from three types of cardiac diseases: MI, DCM, and HCM. Six LLMs, including GPT-3.5, GPT-4.0, Gemini-1.0, Gemini-1.5, PaLM, and LLaMA, were used to classify and diagnose the CMR reports. The results of the LLMs, with minimal or informative prompts, were compared with those of radiologists. Accuracy (ACC) and balanced accuracy (BAC) were used to evaluate the classification performance of the different LLMs. The consistency between radiologists and LLMs in classifying heart disease categories was evaluated using Gwet's Agreement Coefficient (AC1 value). Diagnostic performance was analyzed through receiver operating characteristic (ROC) curves. Cohen's kappa was used to assess the reproducibility of the LLMs' diagnostic results obtained at different time intervals (a 30-day interval).</p><p><strong>Results: </strong>This study enrolled 543 CMR cases, including 275 MI, 120 DCM, and 148 HCM cases. The overall BAC of the minimal prompted LLMs, from highest to lowest, were GPT-4.0, LLaMA, PaLM, GPT-3.5, Gemini-1.5, and Gemini-1.0. The informative prompted models of GPT-3.5 (P<0.001), GPT-4.0 (P<0.001), Gemini-1.0 (P<0.001), Gemini-1.5 (P=0.02), and PaLM (P<0.001) showed significant improvements in overall ACC compared to their minimal prompted models, whereas the informative prompted model of LLaMA did not show a significant improvement in overall ACC compared to the minimal prompted model (P=0.06). GPT-4.0 performed best in both the minimal prompted (ACC =88.6%, BAC =91.7%) and informative prompted (ACC =95.8%, BAC =97.1%) models. GPT-4.0 demonstrated the highest agreement with radiologists [AC1=0.82, 95% confidence interval (CI): 0.78-0.86], significantly outperforming others (P<0.001). For the informative prompted models of LLMs, GPT-4.0 + informative prompt (AC1=0.93, 95% CI: 0.90-0.96), GPT-3.5 + informative prompt (AC1=0.93, 95% CI: 0.90-0.95), Gemini-1.0 + informative prompt (AC1=0.90, 95% CI: 0.87-0.93), PaLM + informative prompt (AC1=0.86, 95% CI: 0.82-0.90), LLaMA + informative prompt (AC1=0.82, 95% CI: 0.78-0.86), and Gemini-1.5 + informative prompt (AC1=0.80, 95% CI: 0.76-0.84) all showed almost perfect agreement with radiologists' diagnoses. Diagnostic performance was excellent for GPT-4.0 [area under the curve (AUC)=0.93, 95% CI: 0.92-0.95] and LLaMA (AUC =0.92, 95% CI: 0.90-0.94) in minimal prompted models, while informative prompted models achieved superior performance, with GPT-4.0 + informative prompt reaching the highest AUC of 0.98 (95% CI: 0.97-0.99). All models demonstrated good reproducibility (κ>0.80, P<0.001).</p><p><strong>Conclusions: </strong>LLMs demonstrated outstanding performance in the automated classification and diagnosis of targeted CMR interpretations, especially with informative prompts, suggesting the potential for these models to serve as adjunct tools in CMR diagnostic workflows.</p>\",\"PeriodicalId\":9592,\"journal\":{\"name\":\"Cardiovascular diagnosis and therapy\",\"volume\":\"15 4\",\"pages\":\"726-737\"},\"PeriodicalIF\":2.1000,\"publicationDate\":\"2025-08-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12432601/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Cardiovascular diagnosis and therapy\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.21037/cdt-2025-112\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/8/28 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"CARDIAC & CARDIOVASCULAR SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Cardiovascular diagnosis and therapy","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.21037/cdt-2025-112","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/8/28 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"CARDIAC & CARDIOVASCULAR SYSTEMS","Score":null,"Total":0}
Automated cardiac magnetic resonance interpretation derived from prompted large language models.
Background: The versatility of cardiac magnetic resonance (CMR) leads to complex and time-consuming interpretation. Large language models (LLMs) present transformative potential for automated CMR interpretations. We explored the ability of LLMs in the automated classification and diagnosis of CMR reports for three common cardiac diseases: myocardial infarction (MI), dilated cardiomyopathy (DCM), and hypertrophic cardiomyopathy (HCM).
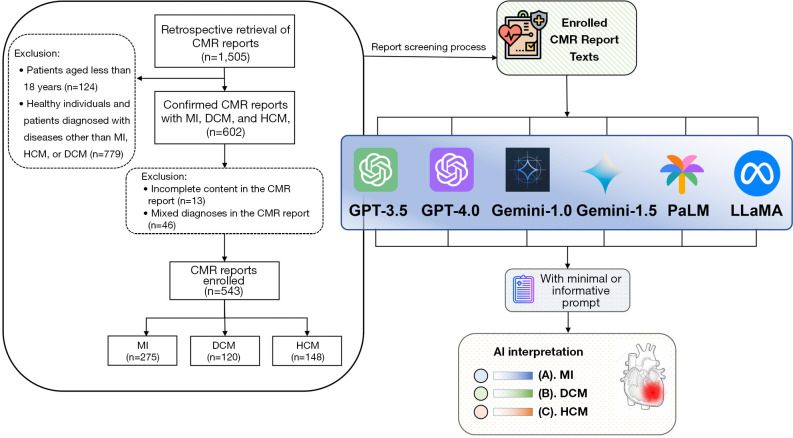
Methods: This retrospective study enrolled CMR reports of consecutive patients from January 2015 to July 2024, including reports from three types of cardiac diseases: MI, DCM, and HCM. Six LLMs, including GPT-3.5, GPT-4.0, Gemini-1.0, Gemini-1.5, PaLM, and LLaMA, were used to classify and diagnose the CMR reports. The results of the LLMs, with minimal or informative prompts, were compared with those of radiologists. Accuracy (ACC) and balanced accuracy (BAC) were used to evaluate the classification performance of the different LLMs. The consistency between radiologists and LLMs in classifying heart disease categories was evaluated using Gwet's Agreement Coefficient (AC1 value). Diagnostic performance was analyzed through receiver operating characteristic (ROC) curves. Cohen's kappa was used to assess the reproducibility of the LLMs' diagnostic results obtained at different time intervals (a 30-day interval).
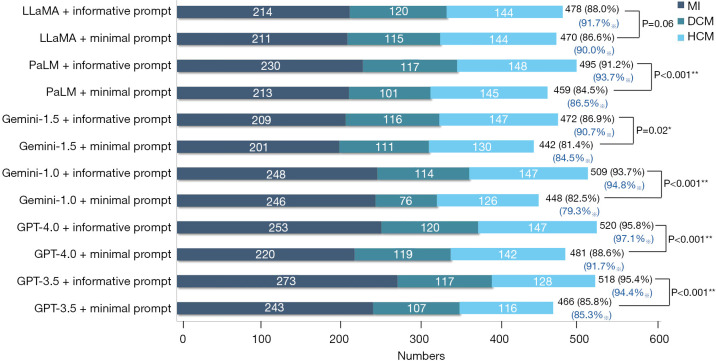
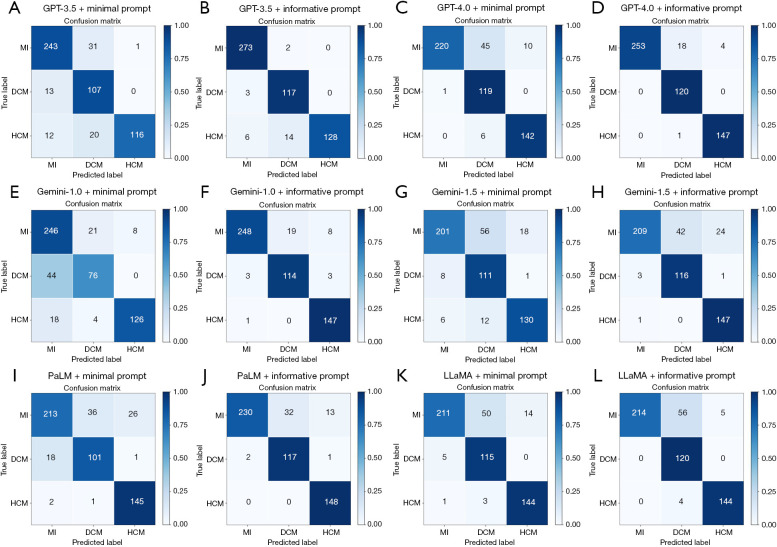
Results: This study enrolled 543 CMR cases, including 275 MI, 120 DCM, and 148 HCM cases. The overall BAC of the minimal prompted LLMs, from highest to lowest, were GPT-4.0, LLaMA, PaLM, GPT-3.5, Gemini-1.5, and Gemini-1.0. The informative prompted models of GPT-3.5 (P<0.001), GPT-4.0 (P<0.001), Gemini-1.0 (P<0.001), Gemini-1.5 (P=0.02), and PaLM (P<0.001) showed significant improvements in overall ACC compared to their minimal prompted models, whereas the informative prompted model of LLaMA did not show a significant improvement in overall ACC compared to the minimal prompted model (P=0.06). GPT-4.0 performed best in both the minimal prompted (ACC =88.6%, BAC =91.7%) and informative prompted (ACC =95.8%, BAC =97.1%) models. GPT-4.0 demonstrated the highest agreement with radiologists [AC1=0.82, 95% confidence interval (CI): 0.78-0.86], significantly outperforming others (P<0.001). For the informative prompted models of LLMs, GPT-4.0 + informative prompt (AC1=0.93, 95% CI: 0.90-0.96), GPT-3.5 + informative prompt (AC1=0.93, 95% CI: 0.90-0.95), Gemini-1.0 + informative prompt (AC1=0.90, 95% CI: 0.87-0.93), PaLM + informative prompt (AC1=0.86, 95% CI: 0.82-0.90), LLaMA + informative prompt (AC1=0.82, 95% CI: 0.78-0.86), and Gemini-1.5 + informative prompt (AC1=0.80, 95% CI: 0.76-0.84) all showed almost perfect agreement with radiologists' diagnoses. Diagnostic performance was excellent for GPT-4.0 [area under the curve (AUC)=0.93, 95% CI: 0.92-0.95] and LLaMA (AUC =0.92, 95% CI: 0.90-0.94) in minimal prompted models, while informative prompted models achieved superior performance, with GPT-4.0 + informative prompt reaching the highest AUC of 0.98 (95% CI: 0.97-0.99). All models demonstrated good reproducibility (κ>0.80, P<0.001).
Conclusions: LLMs demonstrated outstanding performance in the automated classification and diagnosis of targeted CMR interpretations, especially with informative prompts, suggesting the potential for these models to serve as adjunct tools in CMR diagnostic workflows.
期刊介绍:
The journal ''Cardiovascular Diagnosis and Therapy'' (Print ISSN: 2223-3652; Online ISSN: 2223-3660) accepts basic and clinical science submissions related to Cardiovascular Medicine and Surgery. The mission of the journal is the rapid exchange of scientific information between clinicians and scientists worldwide. To reach this goal, the journal will focus on novel media, using a web-based, digital format in addition to traditional print-version. This includes on-line submission, review, publication, and distribution. The digital format will also allow submission of extensive supporting visual material, both images and video. The website www.thecdt.org will serve as the central hub and also allow posting of comments and on-line discussion. The web-site of the journal will be linked to a number of international web-sites (e.g. www.dxy.cn), which will significantly expand the distribution of its contents.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


