Hesam Mahmoudi, Doris Chang, Hannah Lee, Navid Ghaffarzadegan, Mohammad S Jalali
{"title":"大型语言模型(ChatGPT)在系统评价数据提取中的关键评估:探索性研究。","authors":"Hesam Mahmoudi, Doris Chang, Hannah Lee, Navid Ghaffarzadegan, Mohammad S Jalali","doi":"10.2196/68097","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Systematic literature reviews (SLRs) are foundational for synthesizing evidence across diverse fields and are especially important in guiding research and practice in health and biomedical sciences. However, they are labor intensive due to manual data extraction from multiple studies. As large language models (LLMs) gain attention for their potential to automate research tasks and extract basic information, understanding their ability to accurately extract explicit data from academic papers is critical for advancing SLRs.</p><p><strong>Objective: </strong>Our study aimed to explore the capability of LLMs to extract both explicitly outlined study characteristics and deeper, more contextual information requiring nuanced evaluations, using ChatGPT (GPT-4).</p><p><strong>Methods: </strong>We screened the full text of a sample of COVID-19 modeling studies and analyzed three basic measures of study settings (ie, analysis location, modeling approach, and analyzed interventions) and three complex measures of behavioral components in models (ie, mobility, risk perception, and compliance). To extract data on these measures, two researchers independently extracted 60 data elements using manual coding and compared them with the responses from ChatGPT to 420 queries spanning 7 iterations.</p><p><strong>Results: </strong>ChatGPT's accuracy improved as prompts were refined, showing improvements of 33% and 23% between the initial and final iterations for extracting study settings and behavioral components, respectively. In the initial prompts, 26 (43.3%) of 60 ChatGPT responses were correct. However, in the final iteration, ChatGPT extracted 43 (71.7%) of the 60 data elements, showing better performance in extracting explicitly stated study settings (28/30, 93.3%) than in extracting subjective behavioral components (15/30, 50%). Nonetheless, the varying accuracy across measures highlighted its limitations.</p><p><strong>Conclusions: </strong>Our findings underscore LLMs' utility in extracting basic as well as explicit data in SLRs by using effective prompts. However, the results reveal significant limitations in handling nuanced, subjective criteria, emphasizing the necessity for human oversight.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e68097"},"PeriodicalIF":2.0000,"publicationDate":"2025-09-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12425462/pdf/","citationCount":"0","resultStr":"{\"title\":\"Critical Assessment of Large Language Models' (ChatGPT) Performance in Data Extraction for Systematic Reviews: Exploratory Study.\",\"authors\":\"Hesam Mahmoudi, Doris Chang, Hannah Lee, Navid Ghaffarzadegan, Mohammad S Jalali\",\"doi\":\"10.2196/68097\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Systematic literature reviews (SLRs) are foundational for synthesizing evidence across diverse fields and are especially important in guiding research and practice in health and biomedical sciences. However, they are labor intensive due to manual data extraction from multiple studies. As large language models (LLMs) gain attention for their potential to automate research tasks and extract basic information, understanding their ability to accurately extract explicit data from academic papers is critical for advancing SLRs.</p><p><strong>Objective: </strong>Our study aimed to explore the capability of LLMs to extract both explicitly outlined study characteristics and deeper, more contextual information requiring nuanced evaluations, using ChatGPT (GPT-4).</p><p><strong>Methods: </strong>We screened the full text of a sample of COVID-19 modeling studies and analyzed three basic measures of study settings (ie, analysis location, modeling approach, and analyzed interventions) and three complex measures of behavioral components in models (ie, mobility, risk perception, and compliance). To extract data on these measures, two researchers independently extracted 60 data elements using manual coding and compared them with the responses from ChatGPT to 420 queries spanning 7 iterations.</p><p><strong>Results: </strong>ChatGPT's accuracy improved as prompts were refined, showing improvements of 33% and 23% between the initial and final iterations for extracting study settings and behavioral components, respectively. In the initial prompts, 26 (43.3%) of 60 ChatGPT responses were correct. However, in the final iteration, ChatGPT extracted 43 (71.7%) of the 60 data elements, showing better performance in extracting explicitly stated study settings (28/30, 93.3%) than in extracting subjective behavioral components (15/30, 50%). Nonetheless, the varying accuracy across measures highlighted its limitations.</p><p><strong>Conclusions: </strong>Our findings underscore LLMs' utility in extracting basic as well as explicit data in SLRs by using effective prompts. However, the results reveal significant limitations in handling nuanced, subjective criteria, emphasizing the necessity for human oversight.</p>\",\"PeriodicalId\":73551,\"journal\":{\"name\":\"JMIR AI\",\"volume\":\"4 \",\"pages\":\"e68097\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-09-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12425462/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/68097\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/68097","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Critical Assessment of Large Language Models' (ChatGPT) Performance in Data Extraction for Systematic Reviews: Exploratory Study.
Background: Systematic literature reviews (SLRs) are foundational for synthesizing evidence across diverse fields and are especially important in guiding research and practice in health and biomedical sciences. However, they are labor intensive due to manual data extraction from multiple studies. As large language models (LLMs) gain attention for their potential to automate research tasks and extract basic information, understanding their ability to accurately extract explicit data from academic papers is critical for advancing SLRs.
Objective: Our study aimed to explore the capability of LLMs to extract both explicitly outlined study characteristics and deeper, more contextual information requiring nuanced evaluations, using ChatGPT (GPT-4).
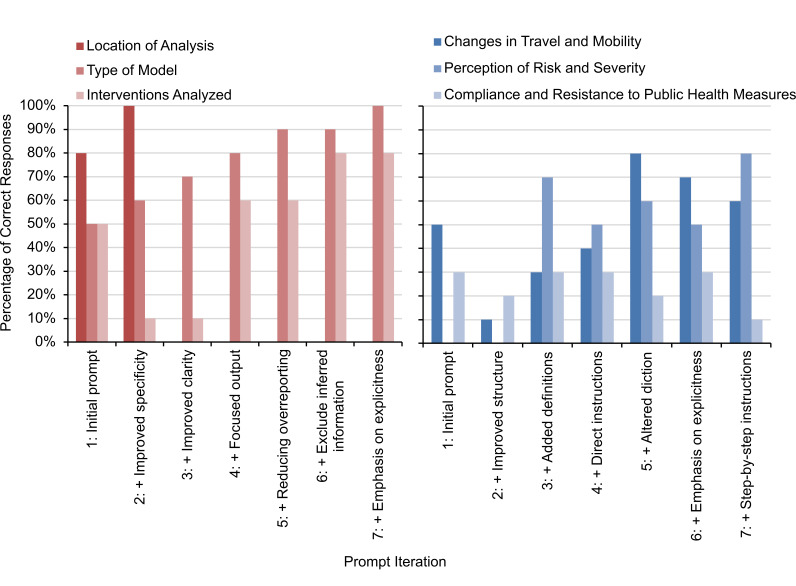
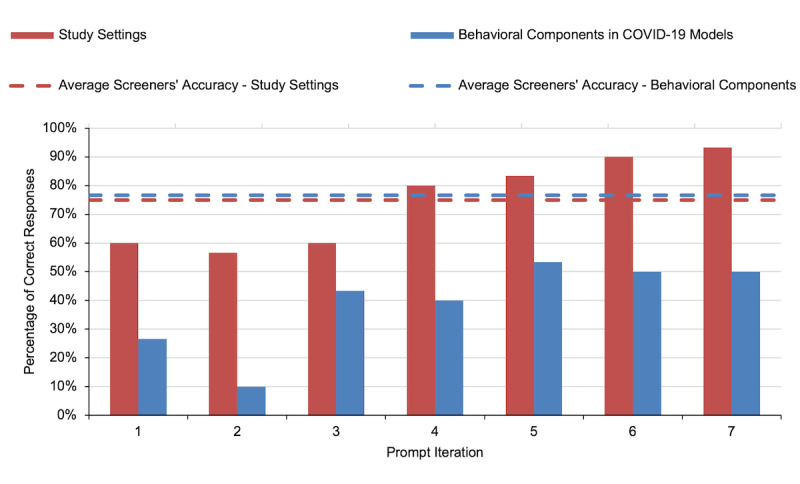
Methods: We screened the full text of a sample of COVID-19 modeling studies and analyzed three basic measures of study settings (ie, analysis location, modeling approach, and analyzed interventions) and three complex measures of behavioral components in models (ie, mobility, risk perception, and compliance). To extract data on these measures, two researchers independently extracted 60 data elements using manual coding and compared them with the responses from ChatGPT to 420 queries spanning 7 iterations.
Results: ChatGPT's accuracy improved as prompts were refined, showing improvements of 33% and 23% between the initial and final iterations for extracting study settings and behavioral components, respectively. In the initial prompts, 26 (43.3%) of 60 ChatGPT responses were correct. However, in the final iteration, ChatGPT extracted 43 (71.7%) of the 60 data elements, showing better performance in extracting explicitly stated study settings (28/30, 93.3%) than in extracting subjective behavioral components (15/30, 50%). Nonetheless, the varying accuracy across measures highlighted its limitations.
Conclusions: Our findings underscore LLMs' utility in extracting basic as well as explicit data in SLRs by using effective prompts. However, the results reveal significant limitations in handling nuanced, subjective criteria, emphasizing the necessity for human oversight.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


