Iftikhar Ahmed, Anushree Brahmacharimayum, Raja Hashim Ali, Talha Ali Khan, Muhammad Ovais Ahmad
{"title":"基于活动数据的抑郁症检测和严重程度分类的可解释AI:一个可解释框架的开发和评估研究。","authors":"Iftikhar Ahmed, Anushree Brahmacharimayum, Raja Hashim Ali, Talha Ali Khan, Muhammad Ovais Ahmad","doi":"10.2196/72038","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Depression is one of the most prevalent mental health disorders globally, affecting approximately 280 million people and frequently going undiagnosed or misdiagnosed. The growing ubiquity of wearable devices enables continuous monitoring of activity levels, providing a new avenue for data-driven detection and severity assessment of depression. However, existing machine learning models often exhibit lower performance when distinguishing overlapping subtypes of depression and frequently lack explainability, an essential component for clinical acceptance.</p><p><strong>Objective: </strong>This study aimed to develop and evaluate an interpretable machine learning framework for detecting depression and classifying its severity using wearable-actigraphy data, while addressing common challenges such as imbalanced datasets and limited model transparency.</p><p><strong>Methods: </strong>We used the Depresjon dataset and applied Adaptive Synthetic Sampling (ADASYN) to mitigate class imbalance. We extracted multiple statistical features (eg, power spectral density mean and autocorrelation) and demographic attributes (eg, age) from the raw activity data. Five machine learning algorithms (logistic regression, support vector machines, random forest, XGBoost, and neural networks) were assessed via accuracy, precision, recall, F1-score, specificity, and Matthew correlation constant. We further used Shapley Additive Explanations (SHAP) and Local Interpretable Model-agnostic Explanations (LIME) to elucidate prediction drivers.</p><p><strong>Results: </strong>XGBoost achieved the highest overall accuracy of 84.94% for binary classification and 85.91% for multiclass severity. SHAP and LIME revealed power spectral density mean, age, and autocorrelation as top predictors, highlighting circadian disruptions' role in depression.</p><p><strong>Conclusions: </strong>Our interpretable framework reliably identifies depressed versus nondepressed individuals and differentiates mild from moderate depression. The inclusion of SHAP and LIME provides transparent, clinically meaningful insights, emphasizing the potential of explainable artificial intelligence to enhance early detection and intervention strategies in mental health care.</p>","PeriodicalId":48616,"journal":{"name":"Jmir Mental Health","volume":"12 ","pages":"e72038"},"PeriodicalIF":5.8000,"publicationDate":"2025-09-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12425426/pdf/","citationCount":"0","resultStr":"{\"title\":\"Explainable AI for Depression Detection and Severity Classification From Activity Data: Development and Evaluation Study of an Interpretable Framework.\",\"authors\":\"Iftikhar Ahmed, Anushree Brahmacharimayum, Raja Hashim Ali, Talha Ali Khan, Muhammad Ovais Ahmad\",\"doi\":\"10.2196/72038\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Depression is one of the most prevalent mental health disorders globally, affecting approximately 280 million people and frequently going undiagnosed or misdiagnosed. The growing ubiquity of wearable devices enables continuous monitoring of activity levels, providing a new avenue for data-driven detection and severity assessment of depression. However, existing machine learning models often exhibit lower performance when distinguishing overlapping subtypes of depression and frequently lack explainability, an essential component for clinical acceptance.</p><p><strong>Objective: </strong>This study aimed to develop and evaluate an interpretable machine learning framework for detecting depression and classifying its severity using wearable-actigraphy data, while addressing common challenges such as imbalanced datasets and limited model transparency.</p><p><strong>Methods: </strong>We used the Depresjon dataset and applied Adaptive Synthetic Sampling (ADASYN) to mitigate class imbalance. We extracted multiple statistical features (eg, power spectral density mean and autocorrelation) and demographic attributes (eg, age) from the raw activity data. Five machine learning algorithms (logistic regression, support vector machines, random forest, XGBoost, and neural networks) were assessed via accuracy, precision, recall, F1-score, specificity, and Matthew correlation constant. We further used Shapley Additive Explanations (SHAP) and Local Interpretable Model-agnostic Explanations (LIME) to elucidate prediction drivers.</p><p><strong>Results: </strong>XGBoost achieved the highest overall accuracy of 84.94% for binary classification and 85.91% for multiclass severity. SHAP and LIME revealed power spectral density mean, age, and autocorrelation as top predictors, highlighting circadian disruptions' role in depression.</p><p><strong>Conclusions: </strong>Our interpretable framework reliably identifies depressed versus nondepressed individuals and differentiates mild from moderate depression. The inclusion of SHAP and LIME provides transparent, clinically meaningful insights, emphasizing the potential of explainable artificial intelligence to enhance early detection and intervention strategies in mental health care.</p>\",\"PeriodicalId\":48616,\"journal\":{\"name\":\"Jmir Mental Health\",\"volume\":\"12 \",\"pages\":\"e72038\"},\"PeriodicalIF\":5.8000,\"publicationDate\":\"2025-09-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12425426/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Jmir Mental Health\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.2196/72038\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"PSYCHIATRY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Jmir Mental Health","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/72038","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"PSYCHIATRY","Score":null,"Total":0}
Explainable AI for Depression Detection and Severity Classification From Activity Data: Development and Evaluation Study of an Interpretable Framework.
Background: Depression is one of the most prevalent mental health disorders globally, affecting approximately 280 million people and frequently going undiagnosed or misdiagnosed. The growing ubiquity of wearable devices enables continuous monitoring of activity levels, providing a new avenue for data-driven detection and severity assessment of depression. However, existing machine learning models often exhibit lower performance when distinguishing overlapping subtypes of depression and frequently lack explainability, an essential component for clinical acceptance.
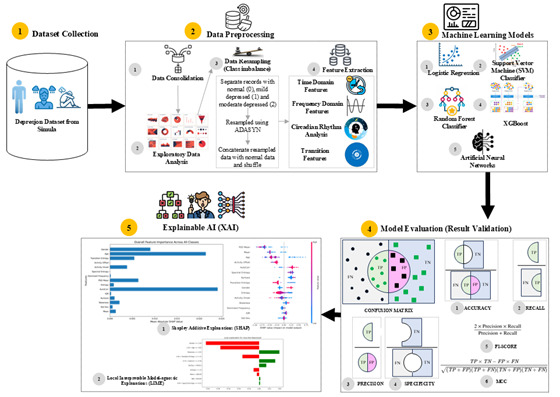
Objective: This study aimed to develop and evaluate an interpretable machine learning framework for detecting depression and classifying its severity using wearable-actigraphy data, while addressing common challenges such as imbalanced datasets and limited model transparency.
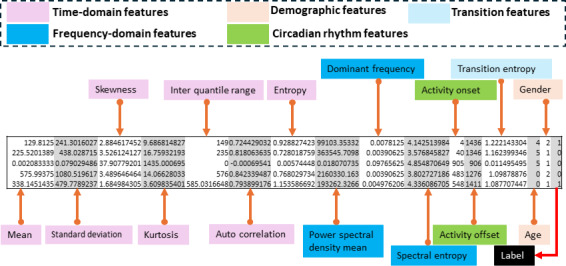
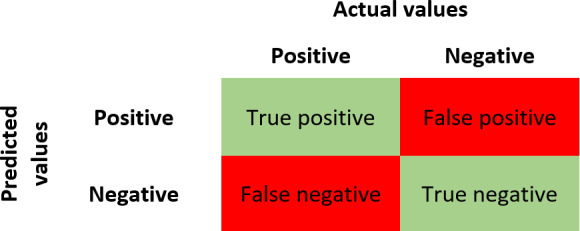
Methods: We used the Depresjon dataset and applied Adaptive Synthetic Sampling (ADASYN) to mitigate class imbalance. We extracted multiple statistical features (eg, power spectral density mean and autocorrelation) and demographic attributes (eg, age) from the raw activity data. Five machine learning algorithms (logistic regression, support vector machines, random forest, XGBoost, and neural networks) were assessed via accuracy, precision, recall, F1-score, specificity, and Matthew correlation constant. We further used Shapley Additive Explanations (SHAP) and Local Interpretable Model-agnostic Explanations (LIME) to elucidate prediction drivers.
Results: XGBoost achieved the highest overall accuracy of 84.94% for binary classification and 85.91% for multiclass severity. SHAP and LIME revealed power spectral density mean, age, and autocorrelation as top predictors, highlighting circadian disruptions' role in depression.
Conclusions: Our interpretable framework reliably identifies depressed versus nondepressed individuals and differentiates mild from moderate depression. The inclusion of SHAP and LIME provides transparent, clinically meaningful insights, emphasizing the potential of explainable artificial intelligence to enhance early detection and intervention strategies in mental health care.
期刊介绍:
JMIR Mental Health (JMH, ISSN 2368-7959) is a PubMed-indexed, peer-reviewed sister journal of JMIR, the leading eHealth journal (Impact Factor 2016: 5.175).
JMIR Mental Health focusses on digital health and Internet interventions, technologies and electronic innovations (software and hardware) for mental health, addictions, online counselling and behaviour change. This includes formative evaluation and system descriptions, theoretical papers, review papers, viewpoint/vision papers, and rigorous evaluations.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


