Nathan Leroux, Paul-Philipp Manea, Chirag Sudarshan, Jan Finkbeiner, Sebastian Siegel, John Paul Strachan, Emre Neftci
{"title":"模拟内存计算关注机制的快速和节能的大型语言模型。","authors":"Nathan Leroux, Paul-Philipp Manea, Chirag Sudarshan, Jan Finkbeiner, Sebastian Siegel, John Paul Strachan, Emre Neftci","doi":"10.1038/s43588-025-00854-1","DOIUrl":null,"url":null,"abstract":"Transformer networks, driven by self-attention, are central to large language models. In generative transformers, self-attention uses cache memory to store token projections, avoiding recomputation at each time step. However, graphics processing unit (GPU)-stored projections must be loaded into static random-access memory for each new generation step, causing latency and energy bottlenecks. Here we present a custom self-attention in-memory computing architecture based on emerging charge-based memories called gain cells, which can be efficiently written to store new tokens during sequence generation and enable parallel analog dot-product computation required for self-attention. However, the analog gain-cell circuits introduce non-idealities and constraints preventing the direct mapping of pre-trained models. To circumvent this problem, we design an initialization algorithm achieving text-processing performance comparable to GPT-2 without training from scratch. Our architecture reduces attention latency and energy consumption by up to two and four orders of magnitude, respectively, compared with GPUs, marking a substantial step toward ultrafast, low-power generative transformers. Leveraging in-memory computing with emerging gain-cell devices, the authors accelerate attention—a core mechanism in large language models. They train a 1.5-billion-parameter model, achieving up to a 70,000-fold reduction in energy consumption and a 100-fold speed-up compared with GPUs.","PeriodicalId":74246,"journal":{"name":"Nature computational science","volume":"5 9","pages":"813-824"},"PeriodicalIF":18.3000,"publicationDate":"2025-09-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.comhttps://www.nature.com/articles/s43588-025-00854-1.pdf","citationCount":"0","resultStr":"{\"title\":\"Analog in-memory computing attention mechanism for fast and energy-efficient large language models\",\"authors\":\"Nathan Leroux, Paul-Philipp Manea, Chirag Sudarshan, Jan Finkbeiner, Sebastian Siegel, John Paul Strachan, Emre Neftci\",\"doi\":\"10.1038/s43588-025-00854-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Transformer networks, driven by self-attention, are central to large language models. In generative transformers, self-attention uses cache memory to store token projections, avoiding recomputation at each time step. However, graphics processing unit (GPU)-stored projections must be loaded into static random-access memory for each new generation step, causing latency and energy bottlenecks. Here we present a custom self-attention in-memory computing architecture based on emerging charge-based memories called gain cells, which can be efficiently written to store new tokens during sequence generation and enable parallel analog dot-product computation required for self-attention. However, the analog gain-cell circuits introduce non-idealities and constraints preventing the direct mapping of pre-trained models. To circumvent this problem, we design an initialization algorithm achieving text-processing performance comparable to GPT-2 without training from scratch. Our architecture reduces attention latency and energy consumption by up to two and four orders of magnitude, respectively, compared with GPUs, marking a substantial step toward ultrafast, low-power generative transformers. Leveraging in-memory computing with emerging gain-cell devices, the authors accelerate attention—a core mechanism in large language models. They train a 1.5-billion-parameter model, achieving up to a 70,000-fold reduction in energy consumption and a 100-fold speed-up compared with GPUs.\",\"PeriodicalId\":74246,\"journal\":{\"name\":\"Nature computational science\",\"volume\":\"5 9\",\"pages\":\"813-824\"},\"PeriodicalIF\":18.3000,\"publicationDate\":\"2025-09-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.nature.comhttps://www.nature.com/articles/s43588-025-00854-1.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature computational science\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.nature.com/articles/s43588-025-00854-1\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature computational science","FirstCategoryId":"1085","ListUrlMain":"https://www.nature.com/articles/s43588-025-00854-1","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Analog in-memory computing attention mechanism for fast and energy-efficient large language models
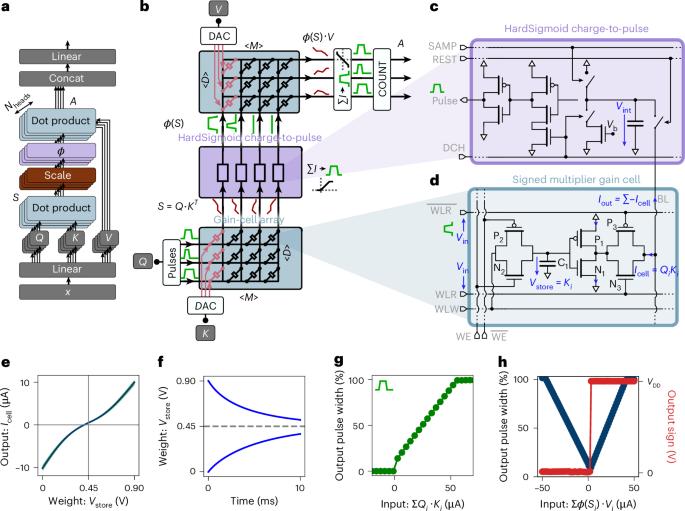
Transformer networks, driven by self-attention, are central to large language models. In generative transformers, self-attention uses cache memory to store token projections, avoiding recomputation at each time step. However, graphics processing unit (GPU)-stored projections must be loaded into static random-access memory for each new generation step, causing latency and energy bottlenecks. Here we present a custom self-attention in-memory computing architecture based on emerging charge-based memories called gain cells, which can be efficiently written to store new tokens during sequence generation and enable parallel analog dot-product computation required for self-attention. However, the analog gain-cell circuits introduce non-idealities and constraints preventing the direct mapping of pre-trained models. To circumvent this problem, we design an initialization algorithm achieving text-processing performance comparable to GPT-2 without training from scratch. Our architecture reduces attention latency and energy consumption by up to two and four orders of magnitude, respectively, compared with GPUs, marking a substantial step toward ultrafast, low-power generative transformers. Leveraging in-memory computing with emerging gain-cell devices, the authors accelerate attention—a core mechanism in large language models. They train a 1.5-billion-parameter model, achieving up to a 70,000-fold reduction in energy consumption and a 100-fold speed-up compared with GPUs.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


