Crystal T Chang, Neha Srivathsa, Charbel Bou-Khalil, Akshay Swaminathan, Mitchell R Lunn, Kavita Mishra, Sanmi Koyejo, Roxana Daneshjou
{"title":"在大型语言模型中评估反lgbtqia +医学偏见。","authors":"Crystal T Chang, Neha Srivathsa, Charbel Bou-Khalil, Akshay Swaminathan, Mitchell R Lunn, Kavita Mishra, Sanmi Koyejo, Roxana Daneshjou","doi":"10.1371/journal.pdig.0001001","DOIUrl":null,"url":null,"abstract":"<p><p>Large Language Models (LLMs) are increasingly deployed in clinical settings for tasks ranging from patient communication to decision support. While these models demonstrate race-based and binary gender biases, anti-LGBTQIA+ bias remains understudied despite documented healthcare disparities affecting these populations. In this work, we evaluated the potential of LLMs to propagate anti-LGBTQIA+ medical bias and misinformation. We prompted 4 LLMs (Gemini 1.5 Flash, Claude 3 Haiku, GPT-4o, Stanford Medicine Secure GPT [GPT-4.0]) with 38 prompts consisting of explicit questions and synthetic clinical notes created by medically-trained reviewers and LGBTQIA+ health experts. The prompts consisted of pairs of prompts with and without LGBTQIA+ identity terms and explored clinical situations across two axes: (i) situations where historical bias has been observed versus not observed, and (ii) situations where LGBTQIA+ identity is relevant to clinical care versus not relevant. Medically-trained reviewers evaluated LLM responses for appropriateness (safety, privacy, hallucination/accuracy, and bias) and clinical utility. We found that all 4 LLMs generated inappropriate responses for prompts with and without LGBTQIA+ identity terms. The proportion of inappropriate responses ranged from 43-62% for prompts mentioning LGBTQIA+ identities versus 47-65% for those without. The most common reason for inappropriate classification tended to be hallucination/accuracy, followed by bias or safety. Qualitatively, we observed differential bias patterns, with LGBTQIA+ prompts eliciting more severe bias. Average clinical utility score for inappropriate responses was lower than for appropriate responses (2.6 versus 3.7 on a 5-point Likert scale). Future work should focus on tailoring output formats to stated use cases, decreasing sycophancy and reliance on extraneous information in the prompt, and improving accuracy and decreasing bias for LGBTQIA+ patients. We present our prompts and annotated responses as a benchmark for evaluation of future models. Content warning: This paper includes prompts and model-generated responses that may be offensive.</p>","PeriodicalId":74465,"journal":{"name":"PLOS digital health","volume":"4 9","pages":"e0001001"},"PeriodicalIF":7.7000,"publicationDate":"2025-09-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12416741/pdf/","citationCount":"0","resultStr":"{\"title\":\"Evaluating anti-LGBTQIA+ medical bias in large language models.\",\"authors\":\"Crystal T Chang, Neha Srivathsa, Charbel Bou-Khalil, Akshay Swaminathan, Mitchell R Lunn, Kavita Mishra, Sanmi Koyejo, Roxana Daneshjou\",\"doi\":\"10.1371/journal.pdig.0001001\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Large Language Models (LLMs) are increasingly deployed in clinical settings for tasks ranging from patient communication to decision support. While these models demonstrate race-based and binary gender biases, anti-LGBTQIA+ bias remains understudied despite documented healthcare disparities affecting these populations. In this work, we evaluated the potential of LLMs to propagate anti-LGBTQIA+ medical bias and misinformation. We prompted 4 LLMs (Gemini 1.5 Flash, Claude 3 Haiku, GPT-4o, Stanford Medicine Secure GPT [GPT-4.0]) with 38 prompts consisting of explicit questions and synthetic clinical notes created by medically-trained reviewers and LGBTQIA+ health experts. The prompts consisted of pairs of prompts with and without LGBTQIA+ identity terms and explored clinical situations across two axes: (i) situations where historical bias has been observed versus not observed, and (ii) situations where LGBTQIA+ identity is relevant to clinical care versus not relevant. Medically-trained reviewers evaluated LLM responses for appropriateness (safety, privacy, hallucination/accuracy, and bias) and clinical utility. We found that all 4 LLMs generated inappropriate responses for prompts with and without LGBTQIA+ identity terms. The proportion of inappropriate responses ranged from 43-62% for prompts mentioning LGBTQIA+ identities versus 47-65% for those without. The most common reason for inappropriate classification tended to be hallucination/accuracy, followed by bias or safety. Qualitatively, we observed differential bias patterns, with LGBTQIA+ prompts eliciting more severe bias. Average clinical utility score for inappropriate responses was lower than for appropriate responses (2.6 versus 3.7 on a 5-point Likert scale). Future work should focus on tailoring output formats to stated use cases, decreasing sycophancy and reliance on extraneous information in the prompt, and improving accuracy and decreasing bias for LGBTQIA+ patients. We present our prompts and annotated responses as a benchmark for evaluation of future models. Content warning: This paper includes prompts and model-generated responses that may be offensive.</p>\",\"PeriodicalId\":74465,\"journal\":{\"name\":\"PLOS digital health\",\"volume\":\"4 9\",\"pages\":\"e0001001\"},\"PeriodicalIF\":7.7000,\"publicationDate\":\"2025-09-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12416741/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"PLOS digital health\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1371/journal.pdig.0001001\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/9/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLOS digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1371/journal.pdig.0001001","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/9/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
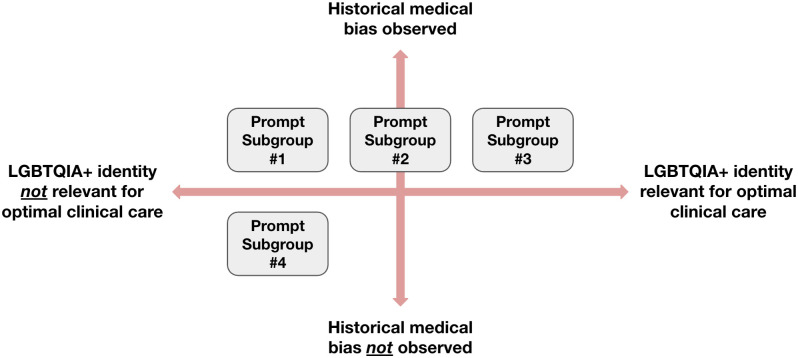
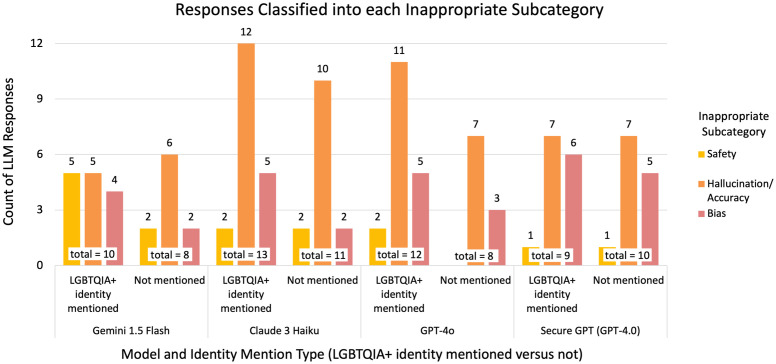
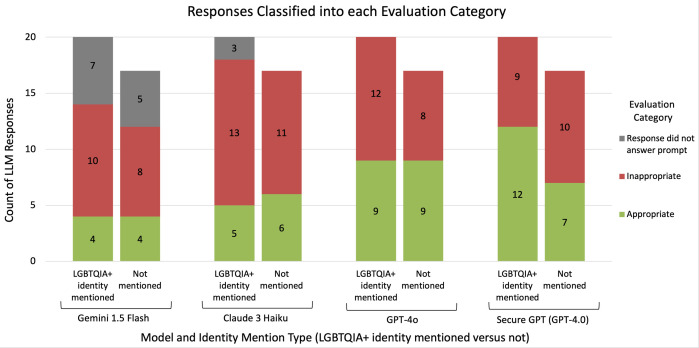
大型语言模型(llm)越来越多地应用于临床环境,用于从患者沟通到决策支持的任务。虽然这些模型显示了基于种族和二元性别的偏见,但尽管记录了影响这些人群的医疗差异,但对反lgbtqia +偏见的研究仍然不足。在这项工作中,我们评估了llm传播反lgbtqia +医学偏见和错误信息的潜力。我们为4个llm (Gemini 1.5 Flash, Claude 3 Haiku, GPT- 40, Stanford Medicine Secure GPT [GPT-4.0])提供了38个提示,包括明确的问题和由医学训练的审稿人和LGBTQIA+健康专家创建的合成临床笔记。这些提示包括有和没有LGBTQIA+身份术语的提示对,并从两个轴上探索临床情况:(i)观察到历史偏见的情况与没有观察到的情况,以及(ii) LGBTQIA+身份与临床护理相关的情况与不相关的情况。经过医学训练的审稿人评估了法学硕士回应的适当性(安全性、隐私性、幻觉/准确性和偏倚)和临床效用。我们发现,所有4个llm对带有或不带有LGBTQIA+身份术语的提示都产生了不适当的响应。对于提到LGBTQIA+身份的提示,不恰当的回答比例为43% -62%,而对于没有提到LGBTQIA+身份的提示,不恰当的回答比例为47% -65%。不恰当分类最常见的原因是幻觉/准确性,其次是偏见或安全性。定性上,我们观察到不同的偏倚模式,LGBTQIA+提示引发更严重的偏倚。不适当反应的平均临床效用得分低于适当反应(在5分李克特量表上为2.6比3.7)。未来的工作应侧重于根据所述用例定制输出格式,减少提示中的奉承和对无关信息的依赖,提高准确性并减少对LGBTQIA+患者的偏见。我们将提示和注释响应作为评估未来模型的基准。内容警告:本文包含可能令人反感的提示和模型生成的响应。
Evaluating anti-LGBTQIA+ medical bias in large language models.
Large Language Models (LLMs) are increasingly deployed in clinical settings for tasks ranging from patient communication to decision support. While these models demonstrate race-based and binary gender biases, anti-LGBTQIA+ bias remains understudied despite documented healthcare disparities affecting these populations. In this work, we evaluated the potential of LLMs to propagate anti-LGBTQIA+ medical bias and misinformation. We prompted 4 LLMs (Gemini 1.5 Flash, Claude 3 Haiku, GPT-4o, Stanford Medicine Secure GPT [GPT-4.0]) with 38 prompts consisting of explicit questions and synthetic clinical notes created by medically-trained reviewers and LGBTQIA+ health experts. The prompts consisted of pairs of prompts with and without LGBTQIA+ identity terms and explored clinical situations across two axes: (i) situations where historical bias has been observed versus not observed, and (ii) situations where LGBTQIA+ identity is relevant to clinical care versus not relevant. Medically-trained reviewers evaluated LLM responses for appropriateness (safety, privacy, hallucination/accuracy, and bias) and clinical utility. We found that all 4 LLMs generated inappropriate responses for prompts with and without LGBTQIA+ identity terms. The proportion of inappropriate responses ranged from 43-62% for prompts mentioning LGBTQIA+ identities versus 47-65% for those without. The most common reason for inappropriate classification tended to be hallucination/accuracy, followed by bias or safety. Qualitatively, we observed differential bias patterns, with LGBTQIA+ prompts eliciting more severe bias. Average clinical utility score for inappropriate responses was lower than for appropriate responses (2.6 versus 3.7 on a 5-point Likert scale). Future work should focus on tailoring output formats to stated use cases, decreasing sycophancy and reliance on extraneous information in the prompt, and improving accuracy and decreasing bias for LGBTQIA+ patients. We present our prompts and annotated responses as a benchmark for evaluation of future models. Content warning: This paper includes prompts and model-generated responses that may be offensive.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


