对时间序列数据中的空值进行全数据集上下文感知预测,以实现低复杂度的更快推理
IF 6.9
1区 管理学
Q1 COMPUTER SCIENCE, INFORMATION SYSTEMS
引用次数: 0
摘要
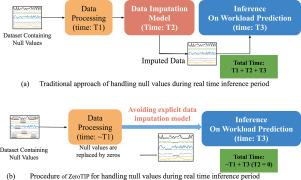
时间序列数据集中的空值处理需要大量显式的数据输入模型,这会在各种任务的推断期间增加延迟。这种担忧引发了以下问题:是否有可能避免这些显式数据输入模型在推理过程中直接执行任务预测而不输入?作为先驱,本文提出了ZeroTIP,这是一种基于知识蒸馏(KD)的预测零时间插入策略,用于工作负载预测,而无需额外的数据插入模型。在训练期间,学生网络被迫隐式地推断缺失值或空值并模仿推理(工作量预测任务),同时将综合损坏的数据作为输入,并由包含原始数据集表示的预训练教师网络进行监督。在推理过程中只使用学生网络。ZeroTIP通过避免显式的数据插入,将推理时间减少了近99.9%。ZeroTIP的一个版本称为ZeroTIP- di,用于数据输入任务,以评估ZeroTIP在推理数据上下文和模式方面的重要性。在预测长度为48和96的情况下,ZeroTIP-DI平均提高基线38.37倍(97.08%)和21.67倍(95.08%),突出了其优越性。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Whole dataset context-aware prediction on the null values in time series data for faster inferencing with low complexity
Null value handling in time series datasets demands heavy and explicit data imputation models, which add latency during inferences for various tasks. This concern raises the following question: is it possible to avoid these explicit data imputation models to perform task predictions directly during inference without imputation? As a pioneer, this paper proposes ZeroTIP, a knowledge distillation (KD)-based Zero Time Imputation for Prediction strategy for workload predictions without having additional data-imputation models. During the training period, a student network is forced to reason the missing or null values implicitly and mimic the inference (workload prediction task) while taking synthetically corrupted data as input and being supervised by the pretrained teacher network that contains representations of the original dataset. Only the student network is used during inference. ZeroTIP reduced the inference time by almost 99.9% by avoiding explicit data imputation. A version of ZeroTIP, called ZeroTIP-DI, was deployed for the data imputation task to evaluate the significance of ZeroTIP in reasoning data context and pattern. For a prediction length of 48 and 96, ZeroTIP-DI achieved an average improvement of 38.37 (97.08%) and 21.67 (95.08%) times the baseline, highlighting its superiority.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Information Processing & Management
工程技术-计算机:信息系统
CiteScore
17.00
自引率
11.60%
发文量
276
审稿时长
39 days
期刊介绍:
Information Processing and Management is dedicated to publishing cutting-edge original research at the convergence of computing and information science. Our scope encompasses theory, methods, and applications across various domains, including advertising, business, health, information science, information technology marketing, and social computing.
We aim to cater to the interests of both primary researchers and practitioners by offering an effective platform for the timely dissemination of advanced and topical issues in this interdisciplinary field. The journal places particular emphasis on original research articles, research survey articles, research method articles, and articles addressing critical applications of research. Join us in advancing knowledge and innovation at the intersection of computing and information science.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


