基于骨架动作识别的自注意增强动态语义多尺度图卷积网络
IF 4.2
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
基于骨骼的动作识别由于其在人体运动建模中的有效性和鲁棒性而受到越来越多的关注。然而,现有的图卷积方法通常依赖于预定义的拓扑,难以捕获高级语义关系和远程依赖关系。与此同时,基于变压器的方法尽管在建模全局依赖性方面很有效,但通常忽略了局部连续性,并且计算成本很高。此外,目前的多流融合策略通常忽略了跨模态的低水平互补线索。为了解决这些限制,我们提出了自注意增强的多尺度动态语义图卷积网络SAD-MSNet。SAD-MSNet集成了一个区域感知的多尺度骨架简化策略来表示不同抽象级别的动作。它采用语义感知的空间建模模块,根据节点类型、边缘类型和拓扑先验构建动态图,并通过通道关注和自适应融合进一步细化。对于时间建模,该网络采用六分支结构,该结构结合了标准因果卷积、具有不同扩张率的扩展联合引导时间卷积和全局池化分支,使其能够有效地捕获短期动态和长期时间语义。在NTU RGB+D, NTU RGB+ d120和N-UCLA上进行的大量实验表明,与最先进的方法相比,SAD-MSNet实现了卓越的性能,同时保持了紧凑和可解释的架构。本文章由计算机程序翻译,如有差异,请以英文原文为准。
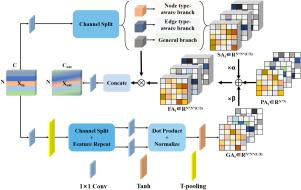
Self-attention enhanced dynamic semantic multi-scale graph convolutional network for skeleton-based action recognition
Skeleton-based action recognition has attracted increasing attention due to its efficiency and robustness in modeling human motion. However, existing graph convolutional approaches often rely on predefined topologies and struggle to capture high-level semantic relations and long-range dependencies. Meanwhile, transformer-based methods, despite their effectiveness in modeling global dependencies, typically overlook local continuity and impose high computational costs. Moreover, current multi-stream fusion strategies commonly ignore low-level complementary cues across modalities. To address these limitations, we propose SAD-MSNet, a Self-Attention enhanced Multi-Scale dynamic semantic graph convolutional network. SAD-MSNet integrates a region-aware multi-scale skeleton simplification strategy to represent actions at different levels of abstraction. It employs a semantic-aware spatial modeling module that constructs dynamic graphs based on node types, edge types, and topological priors, further refined by channel-wise attention and adaptive fusion. For temporal modeling, the network utilizes a six-branch structure that combines standard causal convolution, dilated joint-guided temporal convolutions with varying dilation rates, and a global pooling branch, enabling it to effectively capture both short-term dynamics and long-range temporal semantics. Extensive experiments on NTU RGB+D, NTU RGB+D 120, and N-UCLA demonstrate that SAD-MSNet achieves superior performance compared to state-of-the-art methods, while maintaining a compact and interpretable architecture.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Image and Vision Computing
工程技术-工程:电子与电气
CiteScore
8.50
自引率
8.50%
发文量
143
审稿时长
7.8 months
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


