{"title":"kpn -匿名:对k -匿名的扩展,用于web应用的用户匿名性评估","authors":"Ángel Merino , Ángel Cuevas , Rubén Cuevas","doi":"10.1016/j.array.2025.100499","DOIUrl":null,"url":null,"abstract":"<div><div>User data powers much of the Internet nowadays. Beyond personally identifiable information (PII), online systems routinely collect several non-PII user attributes. In world-scale datasets, users may share their combination of attribute values with only a few others, or even be the sole individual matching a specific combination. This makes evaluating and comparing general anonymity across systems challenging, as classical K-anonymity would often be one. We introduce a general methodology to assess user anonymity in general datasets, addressing this issue. Our approach adapts the concept of K-anonymity to focus on most users rather than the least anonymous ones, proposing the metric <span><math><msubsup><mrow><mi>K</mi></mrow><mrow><mi>P</mi></mrow><mrow><mi>N</mi></mrow></msubsup></math></span>: the minimum anonymity (K) among the most anonymous P% of users defined by N attributes. This metric enables the comparison of anonymity levels across systems, helping to identify risks and evaluate the impact of changes such as attribute granularity redesign.</div><div>We demonstrate the applicability of this metric through a case study involving three digital platforms: Meta, LinkedIn, and Twitter (X), leveraging audience data from their advertising systems. We define three common attributes and one platform-specific attribute to reflect each platform’s unique segmentation capabilities. By examining all possible combinations and applying our metric, we demonstrate that Twitter provides the highest levels of anonymity, while Meta yields the lowest. We also study how a specific change in the age attribute cardinality can increase anonymity by more than 10 times on Meta. This case illustrates the utility of our metric in assessing and comparing anonymity risks in real-world data systems.</div></div>","PeriodicalId":8417,"journal":{"name":"Array","volume":"27 ","pages":"Article 100499"},"PeriodicalIF":4.5000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"KPN-anonymity: Extension of K-anonymity for user anonymity evaluation on web applications\",\"authors\":\"Ángel Merino , Ángel Cuevas , Rubén Cuevas\",\"doi\":\"10.1016/j.array.2025.100499\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>User data powers much of the Internet nowadays. Beyond personally identifiable information (PII), online systems routinely collect several non-PII user attributes. In world-scale datasets, users may share their combination of attribute values with only a few others, or even be the sole individual matching a specific combination. This makes evaluating and comparing general anonymity across systems challenging, as classical K-anonymity would often be one. We introduce a general methodology to assess user anonymity in general datasets, addressing this issue. Our approach adapts the concept of K-anonymity to focus on most users rather than the least anonymous ones, proposing the metric <span><math><msubsup><mrow><mi>K</mi></mrow><mrow><mi>P</mi></mrow><mrow><mi>N</mi></mrow></msubsup></math></span>: the minimum anonymity (K) among the most anonymous P% of users defined by N attributes. This metric enables the comparison of anonymity levels across systems, helping to identify risks and evaluate the impact of changes such as attribute granularity redesign.</div><div>We demonstrate the applicability of this metric through a case study involving three digital platforms: Meta, LinkedIn, and Twitter (X), leveraging audience data from their advertising systems. We define three common attributes and one platform-specific attribute to reflect each platform’s unique segmentation capabilities. By examining all possible combinations and applying our metric, we demonstrate that Twitter provides the highest levels of anonymity, while Meta yields the lowest. We also study how a specific change in the age attribute cardinality can increase anonymity by more than 10 times on Meta. This case illustrates the utility of our metric in assessing and comparing anonymity risks in real-world data systems.</div></div>\",\"PeriodicalId\":8417,\"journal\":{\"name\":\"Array\",\"volume\":\"27 \",\"pages\":\"Article 100499\"},\"PeriodicalIF\":4.5000,\"publicationDate\":\"2025-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Array\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2590005625001262\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Array","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2590005625001262","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
KPN-anonymity: Extension of K-anonymity for user anonymity evaluation on web applications
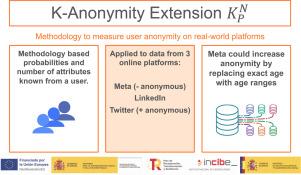
User data powers much of the Internet nowadays. Beyond personally identifiable information (PII), online systems routinely collect several non-PII user attributes. In world-scale datasets, users may share their combination of attribute values with only a few others, or even be the sole individual matching a specific combination. This makes evaluating and comparing general anonymity across systems challenging, as classical K-anonymity would often be one. We introduce a general methodology to assess user anonymity in general datasets, addressing this issue. Our approach adapts the concept of K-anonymity to focus on most users rather than the least anonymous ones, proposing the metric : the minimum anonymity (K) among the most anonymous P% of users defined by N attributes. This metric enables the comparison of anonymity levels across systems, helping to identify risks and evaluate the impact of changes such as attribute granularity redesign.
We demonstrate the applicability of this metric through a case study involving three digital platforms: Meta, LinkedIn, and Twitter (X), leveraging audience data from their advertising systems. We define three common attributes and one platform-specific attribute to reflect each platform’s unique segmentation capabilities. By examining all possible combinations and applying our metric, we demonstrate that Twitter provides the highest levels of anonymity, while Meta yields the lowest. We also study how a specific change in the age attribute cardinality can increase anonymity by more than 10 times on Meta. This case illustrates the utility of our metric in assessing and comparing anonymity risks in real-world data systems.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


