Helena Brinkmann, Antoine Argante, Hugo ter Steege and Francesca Grisoni
{"title":"超越SMILES枚举在生成药物发现中的数据增强。","authors":"Helena Brinkmann, Antoine Argante, Hugo ter Steege and Francesca Grisoni","doi":"10.1039/D5DD00028A","DOIUrl":null,"url":null,"abstract":"<p >Data augmentation can alleviate the limitations of small molecular datasets for generative deep learning by ‘artificially inflating’ the number of instances available for training. SMILES enumeration – wherein multiple valid SMILES strings are used to represent the same molecules – has become particularly beneficial to improve the quality of <em>de novo</em> molecule design. Herein, we investigated whether rethinking SMILES augmentation techniques could further enhance the quality of <em>de novo</em> design. To this end, we introduce four novel approaches for SMILES augmentation, drawing inspiration from natural language processing and chemistry insights: (a) token deletion, (b) atom masking, (c) bioisosteric substitution, and (d) self-training. <em>Via</em> systematic analysis, our results showed the promise of considering additional strategies for SMILES augmentation. Every strategy showed distinct advantages; for example, atom masking is particularly promising to learn desirable physico-chemical properties in very low-data regimes, and deletion to create novel scaffolds. This new repertoire of SMILES augmentation strategies expands the available toolkit to design molecules with bespoke properties in low-data scenarios.</p>","PeriodicalId":72816,"journal":{"name":"Digital discovery","volume":" 10","pages":" 2752-2764"},"PeriodicalIF":6.2000,"publicationDate":"2025-08-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12409607/pdf/","citationCount":"0","resultStr":"{\"title\":\"Going beyond SMILES enumeration for data augmentation in generative drug discovery\",\"authors\":\"Helena Brinkmann, Antoine Argante, Hugo ter Steege and Francesca Grisoni\",\"doi\":\"10.1039/D5DD00028A\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p >Data augmentation can alleviate the limitations of small molecular datasets for generative deep learning by ‘artificially inflating’ the number of instances available for training. SMILES enumeration – wherein multiple valid SMILES strings are used to represent the same molecules – has become particularly beneficial to improve the quality of <em>de novo</em> molecule design. Herein, we investigated whether rethinking SMILES augmentation techniques could further enhance the quality of <em>de novo</em> design. To this end, we introduce four novel approaches for SMILES augmentation, drawing inspiration from natural language processing and chemistry insights: (a) token deletion, (b) atom masking, (c) bioisosteric substitution, and (d) self-training. <em>Via</em> systematic analysis, our results showed the promise of considering additional strategies for SMILES augmentation. Every strategy showed distinct advantages; for example, atom masking is particularly promising to learn desirable physico-chemical properties in very low-data regimes, and deletion to create novel scaffolds. This new repertoire of SMILES augmentation strategies expands the available toolkit to design molecules with bespoke properties in low-data scenarios.</p>\",\"PeriodicalId\":72816,\"journal\":{\"name\":\"Digital discovery\",\"volume\":\" 10\",\"pages\":\" 2752-2764\"},\"PeriodicalIF\":6.2000,\"publicationDate\":\"2025-08-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12409607/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Digital discovery\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://pubs.rsc.org/en/content/articlelanding/2025/dd/d5dd00028a\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"CHEMISTRY, MULTIDISCIPLINARY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Digital discovery","FirstCategoryId":"1085","ListUrlMain":"https://pubs.rsc.org/en/content/articlelanding/2025/dd/d5dd00028a","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
Going beyond SMILES enumeration for data augmentation in generative drug discovery
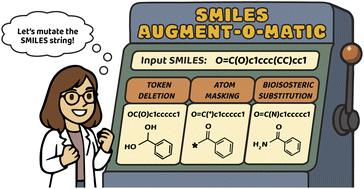
Data augmentation can alleviate the limitations of small molecular datasets for generative deep learning by ‘artificially inflating’ the number of instances available for training. SMILES enumeration – wherein multiple valid SMILES strings are used to represent the same molecules – has become particularly beneficial to improve the quality of de novo molecule design. Herein, we investigated whether rethinking SMILES augmentation techniques could further enhance the quality of de novo design. To this end, we introduce four novel approaches for SMILES augmentation, drawing inspiration from natural language processing and chemistry insights: (a) token deletion, (b) atom masking, (c) bioisosteric substitution, and (d) self-training. Via systematic analysis, our results showed the promise of considering additional strategies for SMILES augmentation. Every strategy showed distinct advantages; for example, atom masking is particularly promising to learn desirable physico-chemical properties in very low-data regimes, and deletion to create novel scaffolds. This new repertoire of SMILES augmentation strategies expands the available toolkit to design molecules with bespoke properties in low-data scenarios.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


