Ji Seung Ryu, Hyunyoung Kang, Yuseong Chu, Sejung Yang
{"title":"医学成像的视觉语言基础模型:当前实践和创新的回顾。","authors":"Ji Seung Ryu, Hyunyoung Kang, Yuseong Chu, Sejung Yang","doi":"10.1007/s13534-025-00484-6","DOIUrl":null,"url":null,"abstract":"<p><p>Foundation models, including large language models and vision-language models (VLMs), have revolutionized artificial intelligence by enabling efficient, scalable, and multimodal learning across diverse applications. By leveraging advancements in self-supervised and semi-supervised learning, these models integrate computer vision and natural language processing to address complex tasks, such as disease classification, segmentation, cross-modal retrieval, and automated report generation. Their ability to pretrain on vast, uncurated datasets minimizes reliance on annotated data while improving generalization and adaptability for a wide range of downstream tasks. In the medical domain, foundation models address critical challenges by combining the information from various medical imaging modalities with textual data from radiology reports and clinical notes. This integration has enabled the development of tools that streamline diagnostic workflows, enhance accuracy (ACC), and enable robust decision-making. This review provides a systematic examination of the recent advancements in medical VLMs from 2022 to 2024, focusing on modality-specific approaches and tailored applications in medical imaging. The key contributions include the creation of a structured taxonomy to categorize existing models, an in-depth analysis of datasets essential for training and evaluation, and a review of practical applications. This review also addresses ongoing challenges and proposes future directions for enhancing the accessibility and impact of foundation models in healthcare.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at 10.1007/s13534-025-00484-6.</p>","PeriodicalId":46898,"journal":{"name":"Biomedical Engineering Letters","volume":"15 5","pages":"809-830"},"PeriodicalIF":2.8000,"publicationDate":"2025-06-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12411343/pdf/","citationCount":"0","resultStr":"{\"title\":\"Vision-language foundation models for medical imaging: a review of current practices and innovations.\",\"authors\":\"Ji Seung Ryu, Hyunyoung Kang, Yuseong Chu, Sejung Yang\",\"doi\":\"10.1007/s13534-025-00484-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Foundation models, including large language models and vision-language models (VLMs), have revolutionized artificial intelligence by enabling efficient, scalable, and multimodal learning across diverse applications. By leveraging advancements in self-supervised and semi-supervised learning, these models integrate computer vision and natural language processing to address complex tasks, such as disease classification, segmentation, cross-modal retrieval, and automated report generation. Their ability to pretrain on vast, uncurated datasets minimizes reliance on annotated data while improving generalization and adaptability for a wide range of downstream tasks. In the medical domain, foundation models address critical challenges by combining the information from various medical imaging modalities with textual data from radiology reports and clinical notes. This integration has enabled the development of tools that streamline diagnostic workflows, enhance accuracy (ACC), and enable robust decision-making. This review provides a systematic examination of the recent advancements in medical VLMs from 2022 to 2024, focusing on modality-specific approaches and tailored applications in medical imaging. The key contributions include the creation of a structured taxonomy to categorize existing models, an in-depth analysis of datasets essential for training and evaluation, and a review of practical applications. This review also addresses ongoing challenges and proposes future directions for enhancing the accessibility and impact of foundation models in healthcare.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at 10.1007/s13534-025-00484-6.</p>\",\"PeriodicalId\":46898,\"journal\":{\"name\":\"Biomedical Engineering Letters\",\"volume\":\"15 5\",\"pages\":\"809-830\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2025-06-06\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12411343/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biomedical Engineering Letters\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.1007/s13534-025-00484-6\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/9/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"ENGINEERING, BIOMEDICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biomedical Engineering Letters","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1007/s13534-025-00484-6","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/9/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"ENGINEERING, BIOMEDICAL","Score":null,"Total":0}
Vision-language foundation models for medical imaging: a review of current practices and innovations.
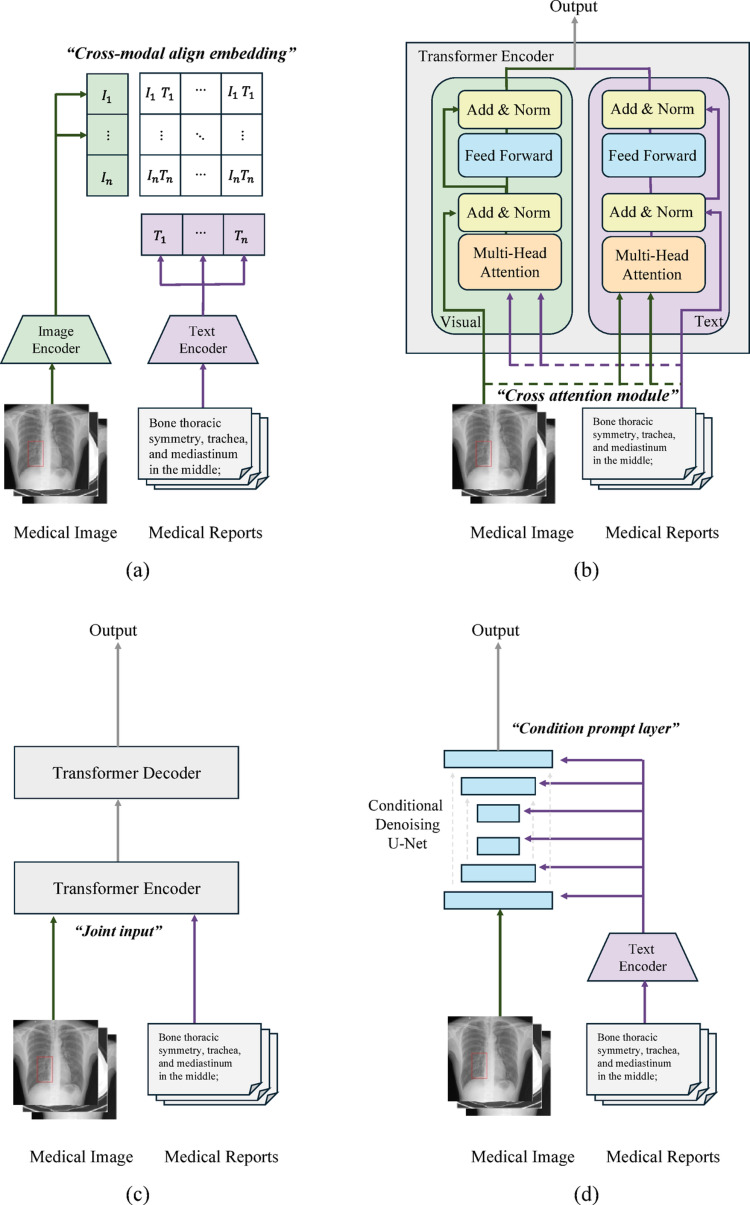
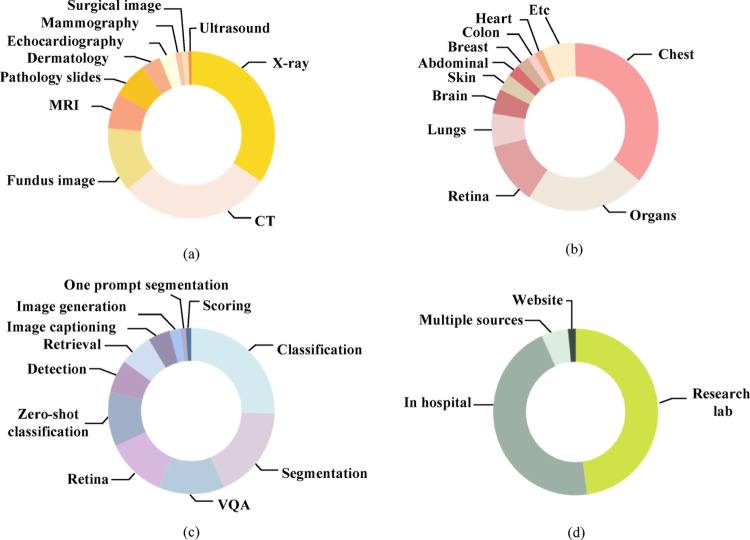
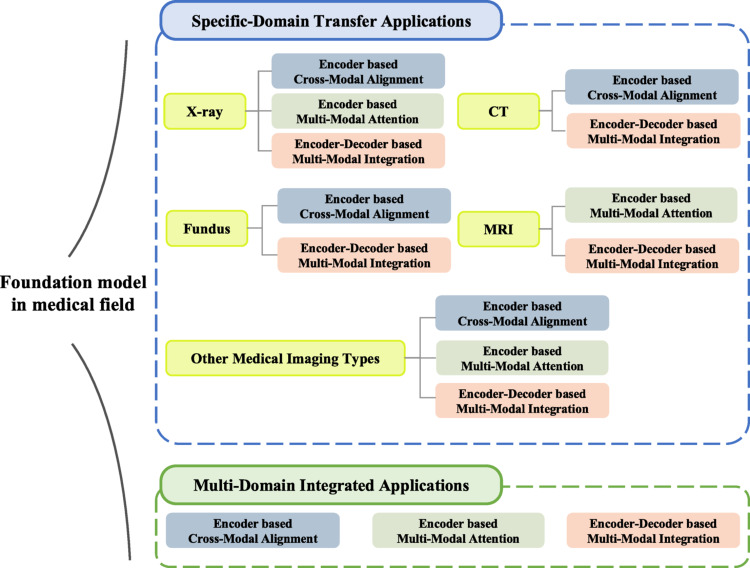
Foundation models, including large language models and vision-language models (VLMs), have revolutionized artificial intelligence by enabling efficient, scalable, and multimodal learning across diverse applications. By leveraging advancements in self-supervised and semi-supervised learning, these models integrate computer vision and natural language processing to address complex tasks, such as disease classification, segmentation, cross-modal retrieval, and automated report generation. Their ability to pretrain on vast, uncurated datasets minimizes reliance on annotated data while improving generalization and adaptability for a wide range of downstream tasks. In the medical domain, foundation models address critical challenges by combining the information from various medical imaging modalities with textual data from radiology reports and clinical notes. This integration has enabled the development of tools that streamline diagnostic workflows, enhance accuracy (ACC), and enable robust decision-making. This review provides a systematic examination of the recent advancements in medical VLMs from 2022 to 2024, focusing on modality-specific approaches and tailored applications in medical imaging. The key contributions include the creation of a structured taxonomy to categorize existing models, an in-depth analysis of datasets essential for training and evaluation, and a review of practical applications. This review also addresses ongoing challenges and proposes future directions for enhancing the accessibility and impact of foundation models in healthcare.
Supplementary information: The online version contains supplementary material available at 10.1007/s13534-025-00484-6.
期刊介绍:
Biomedical Engineering Letters (BMEL) aims to present the innovative experimental science and technological development in the biomedical field as well as clinical application of new development. The article must contain original biomedical engineering content, defined as development, theoretical analysis, and evaluation/validation of a new technique. BMEL publishes the following types of papers: original articles, review articles, editorials, and letters to the editor. All the papers are reviewed in single-blind fashion.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


