Veysel Kocaman, Fu-Yuan Cheng, Julio Bonis, Ganesh Raut, Prem Timsina, David Talby, Arash Kia
{"title":"探索命名实体识别潜力和定制的自然语言处理管道的价值,用于放射学,病理学和临床决策支持的进展记录:定量研究。","authors":"Veysel Kocaman, Fu-Yuan Cheng, Julio Bonis, Ganesh Raut, Prem Timsina, David Talby, Arash Kia","doi":"10.2196/59251","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Clinical notes house rich, yet unstructured, patient data, making analysis challenging due to medical jargon, abbreviations, and synonyms causing ambiguity. This complicates real-time extraction for decision support tools.</p><p><strong>Objective: </strong>This study aimed to examine the data curation, technology, and workflow of the named entity recognition (NER) pipeline, a component of a broader clinical decision support tool that identifies key entities using NER models and classifies these entities as present or absent in the patient through an NER assertion model.</p><p><strong>Methods: </strong>We gathered progress care, radiology, and pathology notes from 5000 patients, dividing them into 5 batches of 1000 patients each. Metrics such as notes and reports per patient, sentence count, token size, runtime, central processing unit, and memory use were measured per note type. We also evaluated the precision of the NER outputs and then the precision and recall of NER assertion models against manual annotations by a clinical expert.</p><p><strong>Results: </strong>Using Spark natural language processing clinical pretrained NER models on 138,250 clinical notes, we observed excellent NER precision, with a peak in procedures at 0.989 (95% CI 0.977-1.000) and an accuracy in the assertion model of 0.889 (95% CI 0.856-0.922). Our analysis highlighted long-tail distributions in notes per patient, note length, and entity density. Progress care notes had notably more entities per sentence than radiology and pathology notes, showing 4-fold and 16-fold differences, respectively.</p><p><strong>Conclusions: </strong>Further research should explore the analysis of clinical notes beyond the scope of our study, including discharge summaries and psychiatric evaluation notes. Recognizing the unique linguistic characteristics of different note types underscores the importance of developing specialized NER models or natural language processing pipeline setups tailored to each type. By doing so, we can enhance their performance across a more diverse range of clinical scenarios.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e59251"},"PeriodicalIF":2.0000,"publicationDate":"2025-09-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12449662/pdf/","citationCount":"0","resultStr":"{\"title\":\"Exploring Named Entity Recognition Potential and the Value of Tailored Natural Language Processing Pipelines for Radiology, Pathology, and Progress Notes in Clinical Decision Support: Quantitative Study.\",\"authors\":\"Veysel Kocaman, Fu-Yuan Cheng, Julio Bonis, Ganesh Raut, Prem Timsina, David Talby, Arash Kia\",\"doi\":\"10.2196/59251\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Clinical notes house rich, yet unstructured, patient data, making analysis challenging due to medical jargon, abbreviations, and synonyms causing ambiguity. This complicates real-time extraction for decision support tools.</p><p><strong>Objective: </strong>This study aimed to examine the data curation, technology, and workflow of the named entity recognition (NER) pipeline, a component of a broader clinical decision support tool that identifies key entities using NER models and classifies these entities as present or absent in the patient through an NER assertion model.</p><p><strong>Methods: </strong>We gathered progress care, radiology, and pathology notes from 5000 patients, dividing them into 5 batches of 1000 patients each. Metrics such as notes and reports per patient, sentence count, token size, runtime, central processing unit, and memory use were measured per note type. We also evaluated the precision of the NER outputs and then the precision and recall of NER assertion models against manual annotations by a clinical expert.</p><p><strong>Results: </strong>Using Spark natural language processing clinical pretrained NER models on 138,250 clinical notes, we observed excellent NER precision, with a peak in procedures at 0.989 (95% CI 0.977-1.000) and an accuracy in the assertion model of 0.889 (95% CI 0.856-0.922). Our analysis highlighted long-tail distributions in notes per patient, note length, and entity density. Progress care notes had notably more entities per sentence than radiology and pathology notes, showing 4-fold and 16-fold differences, respectively.</p><p><strong>Conclusions: </strong>Further research should explore the analysis of clinical notes beyond the scope of our study, including discharge summaries and psychiatric evaluation notes. Recognizing the unique linguistic characteristics of different note types underscores the importance of developing specialized NER models or natural language processing pipeline setups tailored to each type. By doing so, we can enhance their performance across a more diverse range of clinical scenarios.</p>\",\"PeriodicalId\":73551,\"journal\":{\"name\":\"JMIR AI\",\"volume\":\"4 \",\"pages\":\"e59251\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-09-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12449662/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/59251\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/59251","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
背景:临床记录包含丰富但非结构化的患者数据,由于医学术语、缩写和同义词导致歧义,使得分析具有挑战性。这使得决策支持工具的实时提取变得复杂。目的:本研究旨在研究命名实体识别(NER)管道的数据管理、技术和工作流程,这是一个更广泛的临床决策支持工具的组成部分,该工具使用NER模型识别关键实体,并通过NER断言模型将这些实体分类为患者存在或不存在。方法:收集5000例患者的进展监护、影像学、病理记录,分为5批,每批1000例。每个病人的笔记和报告、句子数、令牌大小、运行时间、中央处理单元和内存使用等指标被测量为每个笔记类型。我们还评估了NER输出的精度,然后根据临床专家的手动注释评估了NER断言模型的精度和召回率。结果:使用Spark自然语言处理临床预训练NER模型对138,250份临床记录进行处理,我们观察到良好的NER精度,程序中的峰值为0.989 (95% CI 0.977-1.000),断言模型的准确率为0.889 (95% CI 0.856-0.922)。我们的分析强调了每位患者笔记、笔记长度和实体密度的长尾分布。进展护理笔记比放射学和病理学笔记每句有更多的实体,分别显示4倍和16倍的差异。结论:进一步的研究应探索本研究范围之外的临床记录分析,包括出院总结和精神病学评估记录。认识到不同音符类型的独特语言特征强调了针对每种类型开发专门的NER模型或自然语言处理管道设置的重要性。通过这样做,我们可以在更多样化的临床场景中提高他们的表现。
Exploring Named Entity Recognition Potential and the Value of Tailored Natural Language Processing Pipelines for Radiology, Pathology, and Progress Notes in Clinical Decision Support: Quantitative Study.
Background: Clinical notes house rich, yet unstructured, patient data, making analysis challenging due to medical jargon, abbreviations, and synonyms causing ambiguity. This complicates real-time extraction for decision support tools.
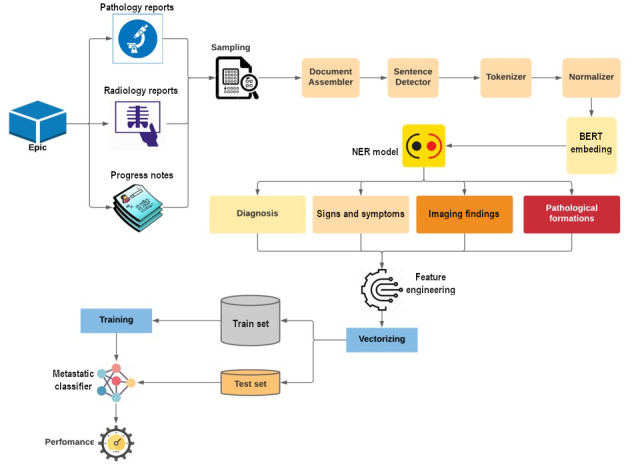
Objective: This study aimed to examine the data curation, technology, and workflow of the named entity recognition (NER) pipeline, a component of a broader clinical decision support tool that identifies key entities using NER models and classifies these entities as present or absent in the patient through an NER assertion model.
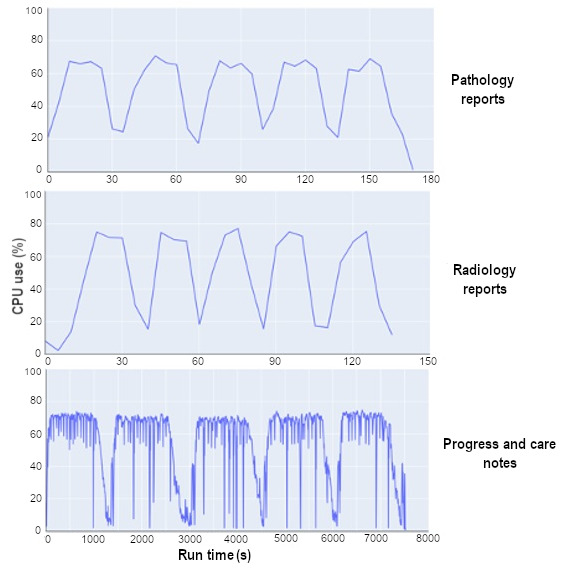
Methods: We gathered progress care, radiology, and pathology notes from 5000 patients, dividing them into 5 batches of 1000 patients each. Metrics such as notes and reports per patient, sentence count, token size, runtime, central processing unit, and memory use were measured per note type. We also evaluated the precision of the NER outputs and then the precision and recall of NER assertion models against manual annotations by a clinical expert.
Results: Using Spark natural language processing clinical pretrained NER models on 138,250 clinical notes, we observed excellent NER precision, with a peak in procedures at 0.989 (95% CI 0.977-1.000) and an accuracy in the assertion model of 0.889 (95% CI 0.856-0.922). Our analysis highlighted long-tail distributions in notes per patient, note length, and entity density. Progress care notes had notably more entities per sentence than radiology and pathology notes, showing 4-fold and 16-fold differences, respectively.
Conclusions: Further research should explore the analysis of clinical notes beyond the scope of our study, including discharge summaries and psychiatric evaluation notes. Recognizing the unique linguistic characteristics of different note types underscores the importance of developing specialized NER models or natural language processing pipeline setups tailored to each type. By doing so, we can enhance their performance across a more diverse range of clinical scenarios.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


