{"title":"ChatGPT在样本量估计中的表现:人工智能能力的初步研究。","authors":"Paul Sebo, Ting Wang","doi":"10.1093/fampra/cmaf069","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Artificial intelligence tools, including large language models such as ChatGPT, are increasingly integrated into clinical and primary care research. However, their ability to assist with specialized statistical tasks, such as sample size estimation, remains largely unexplored.</p><p><strong>Methods: </strong>We evaluated the accuracy and reproducibility of ChatGPT-4.0 and ChatGPT-4o in estimating sample sizes across 24 standard statistical scenarios. Examples were selected from a statistical textbook and an educational website, covering basic methods such as estimating means, proportions, and correlations. Each example was tested twice per model. Models were accessed through the ChatGPT web interface, with a new independent chat session initiated for each round. Accuracy was assessed using mean and median absolute percentage error compared with validated reference values. Reproducibility was assessed using symmetric mean and median absolute percentage error between rounds. Comparisons were performed using Wilcoxon signed-rank tests.</p><p><strong>Results: </strong>For ChatGPT-4.0 and ChatGPT-4o, absolute percentage errors ranged from 0% to 15.2% (except one case: 26.3%) and 0% to 14.3%, respectively, with most examples showing errors below 5%. ChatGPT-4o showed better accuracy than ChatGPT-4.0 (mean absolute percentage error: 3.1% vs. 4.1% in round#1, P-value = .01; 2.8% vs. 5.1% in round#2, P-value =.02) and lower symmetric mean absolute percentage error (0.8% vs. 2.5%), though not significant (P-value = .18).</p><p><strong>Conclusions: </strong>ChatGPT-4.0 and ChatGPT-4o provided reasonably accurate sample size estimates across standard scenarios, with good reproducibility. However, inconsistencies were observed, underscoring the need for cautious interpretation and expert validation. Further research should assess performance in more complex contexts and across a broader range of AI models.</p>","PeriodicalId":12209,"journal":{"name":"Family practice","volume":"42 5","pages":""},"PeriodicalIF":2.2000,"publicationDate":"2025-08-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12411907/pdf/","citationCount":"0","resultStr":"{\"title\":\"ChatGPT's performance in sample size estimation: a preliminary study on the capabilities of artificial intelligence.\",\"authors\":\"Paul Sebo, Ting Wang\",\"doi\":\"10.1093/fampra/cmaf069\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Artificial intelligence tools, including large language models such as ChatGPT, are increasingly integrated into clinical and primary care research. However, their ability to assist with specialized statistical tasks, such as sample size estimation, remains largely unexplored.</p><p><strong>Methods: </strong>We evaluated the accuracy and reproducibility of ChatGPT-4.0 and ChatGPT-4o in estimating sample sizes across 24 standard statistical scenarios. Examples were selected from a statistical textbook and an educational website, covering basic methods such as estimating means, proportions, and correlations. Each example was tested twice per model. Models were accessed through the ChatGPT web interface, with a new independent chat session initiated for each round. Accuracy was assessed using mean and median absolute percentage error compared with validated reference values. Reproducibility was assessed using symmetric mean and median absolute percentage error between rounds. Comparisons were performed using Wilcoxon signed-rank tests.</p><p><strong>Results: </strong>For ChatGPT-4.0 and ChatGPT-4o, absolute percentage errors ranged from 0% to 15.2% (except one case: 26.3%) and 0% to 14.3%, respectively, with most examples showing errors below 5%. ChatGPT-4o showed better accuracy than ChatGPT-4.0 (mean absolute percentage error: 3.1% vs. 4.1% in round#1, P-value = .01; 2.8% vs. 5.1% in round#2, P-value =.02) and lower symmetric mean absolute percentage error (0.8% vs. 2.5%), though not significant (P-value = .18).</p><p><strong>Conclusions: </strong>ChatGPT-4.0 and ChatGPT-4o provided reasonably accurate sample size estimates across standard scenarios, with good reproducibility. However, inconsistencies were observed, underscoring the need for cautious interpretation and expert validation. Further research should assess performance in more complex contexts and across a broader range of AI models.</p>\",\"PeriodicalId\":12209,\"journal\":{\"name\":\"Family practice\",\"volume\":\"42 5\",\"pages\":\"\"},\"PeriodicalIF\":2.2000,\"publicationDate\":\"2025-08-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12411907/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Family practice\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1093/fampra/cmaf069\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MEDICINE, GENERAL & INTERNAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Family practice","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1093/fampra/cmaf069","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MEDICINE, GENERAL & INTERNAL","Score":null,"Total":0}
ChatGPT's performance in sample size estimation: a preliminary study on the capabilities of artificial intelligence.
Background: Artificial intelligence tools, including large language models such as ChatGPT, are increasingly integrated into clinical and primary care research. However, their ability to assist with specialized statistical tasks, such as sample size estimation, remains largely unexplored.
Methods: We evaluated the accuracy and reproducibility of ChatGPT-4.0 and ChatGPT-4o in estimating sample sizes across 24 standard statistical scenarios. Examples were selected from a statistical textbook and an educational website, covering basic methods such as estimating means, proportions, and correlations. Each example was tested twice per model. Models were accessed through the ChatGPT web interface, with a new independent chat session initiated for each round. Accuracy was assessed using mean and median absolute percentage error compared with validated reference values. Reproducibility was assessed using symmetric mean and median absolute percentage error between rounds. Comparisons were performed using Wilcoxon signed-rank tests.
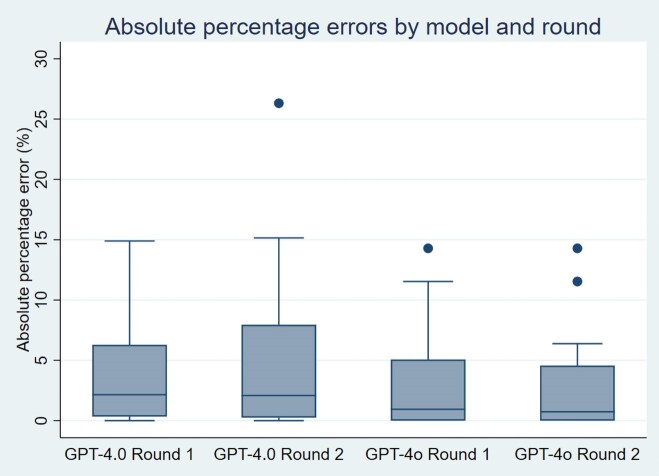
Results: For ChatGPT-4.0 and ChatGPT-4o, absolute percentage errors ranged from 0% to 15.2% (except one case: 26.3%) and 0% to 14.3%, respectively, with most examples showing errors below 5%. ChatGPT-4o showed better accuracy than ChatGPT-4.0 (mean absolute percentage error: 3.1% vs. 4.1% in round#1, P-value = .01; 2.8% vs. 5.1% in round#2, P-value =.02) and lower symmetric mean absolute percentage error (0.8% vs. 2.5%), though not significant (P-value = .18).
Conclusions: ChatGPT-4.0 and ChatGPT-4o provided reasonably accurate sample size estimates across standard scenarios, with good reproducibility. However, inconsistencies were observed, underscoring the need for cautious interpretation and expert validation. Further research should assess performance in more complex contexts and across a broader range of AI models.
期刊介绍:
Family Practice is an international journal aimed at practitioners, teachers, and researchers in the fields of family medicine, general practice, and primary care in both developed and developing countries.
Family Practice offers its readership an international view of the problems and preoccupations in the field, while providing a medium of instruction and exploration.
The journal''s range and content covers such areas as health care delivery, epidemiology, public health, and clinical case studies. The journal aims to be interdisciplinary and contributions from other disciplines of medicine and social science are always welcomed.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


