{"title":"LitAutoScreener:基于大型语言模型的循证医学文献自动筛选工具的开发与验证。","authors":"Yiming Tao, Xuehu Li, Zuhar Yisha, Sihan Yang, Siyan Zhan, Feng Sun","doi":"10.34133/hds.0322","DOIUrl":null,"url":null,"abstract":"<p><p><b>Background:</b> The traditional manual literature screening approach is limited by its time-consuming nature and high labor costs. A pressing issue is how to leverage large language models to enhance the efficiency and quality of evidence-based evaluations of drug efficacy and safety. <b>Methods:</b> This study utilized a manually curated reference literature database-comprising vaccine, hypoglycemic agent, and antidepressant evaluation studies-previously developed by our team through conventional systematic review methods. This validated database served as the gold standard for the development and optimization of LitAutoScreener. Following the PICOS (Population, Intervention, Comparison, Outcomes, Study Design) principles, a chain-of-thought reasoning approach with few-shot learning prompts was implemented to develop the screening algorithm. We subsequently evaluated the performance of LitAutoScreener using 2 independent validation cohorts, assessing both classification accuracy and processing efficiency. <b>Results:</b> For respiratory syncytial virus vaccine safety validation title-abstract screening, our tools based on GPT (GPT-4o), Kimi (moonshot-v1-128k), and DeepSeek (deepseek-chat 2.5) demonstrated high accuracy in inclusion/exclusion decisions (99.38%, 98.94%, and 98.85%, respectively). Recall rates were 100.00%, 99.13%, and 98.26%, with statistically significant performance differences (<i>χ</i> <sup>2</sup> = 5.99, <i>P</i> = 0.048), where GPT outperformed the other models. Exclusion reason concordance rates were 98.85%, 94.79%, and 96.47% (<i>χ</i> <sup>2</sup> = 30.22, <i>P</i> < 0.001). In full-text screening, all models maintained perfect recall (100.00%), with accuracies of 100.00% (GPT), 100.00% (Kimi), and 99.45% (DeepSeek). Processing times averaged 1 to 5 s per article for title-abstract screening and 60 s for full-text processing (including PDF preprocessing). <b>Conclusions:</b> LitAutoScreener offers a new approach for efficient literature screening in drug intervention studies, achieving high accuracy and significantly improving screening efficiency.</p>","PeriodicalId":73207,"journal":{"name":"Health data science","volume":"5 ","pages":"0322"},"PeriodicalIF":0.0000,"publicationDate":"2025-09-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12404845/pdf/","citationCount":"0","resultStr":"{\"title\":\"LitAutoScreener: Development and Validation of an Automated Literature Screening Tool in Evidence-Based Medicine Driven by Large Language Models.\",\"authors\":\"Yiming Tao, Xuehu Li, Zuhar Yisha, Sihan Yang, Siyan Zhan, Feng Sun\",\"doi\":\"10.34133/hds.0322\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p><b>Background:</b> The traditional manual literature screening approach is limited by its time-consuming nature and high labor costs. A pressing issue is how to leverage large language models to enhance the efficiency and quality of evidence-based evaluations of drug efficacy and safety. <b>Methods:</b> This study utilized a manually curated reference literature database-comprising vaccine, hypoglycemic agent, and antidepressant evaluation studies-previously developed by our team through conventional systematic review methods. This validated database served as the gold standard for the development and optimization of LitAutoScreener. Following the PICOS (Population, Intervention, Comparison, Outcomes, Study Design) principles, a chain-of-thought reasoning approach with few-shot learning prompts was implemented to develop the screening algorithm. We subsequently evaluated the performance of LitAutoScreener using 2 independent validation cohorts, assessing both classification accuracy and processing efficiency. <b>Results:</b> For respiratory syncytial virus vaccine safety validation title-abstract screening, our tools based on GPT (GPT-4o), Kimi (moonshot-v1-128k), and DeepSeek (deepseek-chat 2.5) demonstrated high accuracy in inclusion/exclusion decisions (99.38%, 98.94%, and 98.85%, respectively). Recall rates were 100.00%, 99.13%, and 98.26%, with statistically significant performance differences (<i>χ</i> <sup>2</sup> = 5.99, <i>P</i> = 0.048), where GPT outperformed the other models. Exclusion reason concordance rates were 98.85%, 94.79%, and 96.47% (<i>χ</i> <sup>2</sup> = 30.22, <i>P</i> < 0.001). In full-text screening, all models maintained perfect recall (100.00%), with accuracies of 100.00% (GPT), 100.00% (Kimi), and 99.45% (DeepSeek). Processing times averaged 1 to 5 s per article for title-abstract screening and 60 s for full-text processing (including PDF preprocessing). <b>Conclusions:</b> LitAutoScreener offers a new approach for efficient literature screening in drug intervention studies, achieving high accuracy and significantly improving screening efficiency.</p>\",\"PeriodicalId\":73207,\"journal\":{\"name\":\"Health data science\",\"volume\":\"5 \",\"pages\":\"0322\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-09-02\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12404845/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Health data science\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.34133/hds.0322\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Health data science","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.34133/hds.0322","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
LitAutoScreener: Development and Validation of an Automated Literature Screening Tool in Evidence-Based Medicine Driven by Large Language Models.
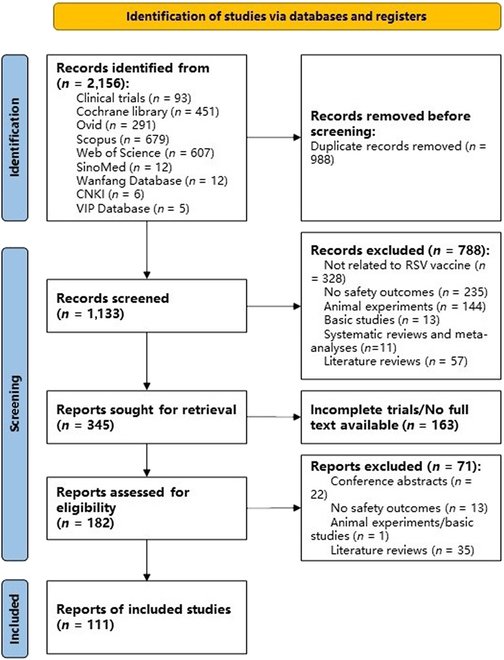
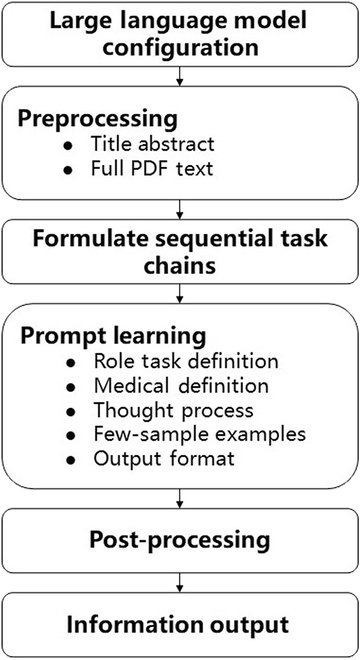
Background: The traditional manual literature screening approach is limited by its time-consuming nature and high labor costs. A pressing issue is how to leverage large language models to enhance the efficiency and quality of evidence-based evaluations of drug efficacy and safety. Methods: This study utilized a manually curated reference literature database-comprising vaccine, hypoglycemic agent, and antidepressant evaluation studies-previously developed by our team through conventional systematic review methods. This validated database served as the gold standard for the development and optimization of LitAutoScreener. Following the PICOS (Population, Intervention, Comparison, Outcomes, Study Design) principles, a chain-of-thought reasoning approach with few-shot learning prompts was implemented to develop the screening algorithm. We subsequently evaluated the performance of LitAutoScreener using 2 independent validation cohorts, assessing both classification accuracy and processing efficiency. Results: For respiratory syncytial virus vaccine safety validation title-abstract screening, our tools based on GPT (GPT-4o), Kimi (moonshot-v1-128k), and DeepSeek (deepseek-chat 2.5) demonstrated high accuracy in inclusion/exclusion decisions (99.38%, 98.94%, and 98.85%, respectively). Recall rates were 100.00%, 99.13%, and 98.26%, with statistically significant performance differences (χ2 = 5.99, P = 0.048), where GPT outperformed the other models. Exclusion reason concordance rates were 98.85%, 94.79%, and 96.47% (χ2 = 30.22, P < 0.001). In full-text screening, all models maintained perfect recall (100.00%), with accuracies of 100.00% (GPT), 100.00% (Kimi), and 99.45% (DeepSeek). Processing times averaged 1 to 5 s per article for title-abstract screening and 60 s for full-text processing (including PDF preprocessing). Conclusions: LitAutoScreener offers a new approach for efficient literature screening in drug intervention studies, achieving high accuracy and significantly improving screening efficiency.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


