{"title":"绘制癌症异质性:对亚型和途径的共识网络方法。","authors":"Geng-Ming Hu, Hsin-Wei Chen, Chi-Ming Chen","doi":"10.1093/bib/bbaf452","DOIUrl":null,"url":null,"abstract":"<p><p>We introduce consensus MSClustering, an unsupervised hierarchical network approach that integrates multi-omics data to identify molecular subtypes and conserved pathways across diverse cancers. Using a novel heterogeneity index, we selected 167 key genes with functionally coherent roles validated through Gene Ontology analysis. Applied to 2439 tumors spanning 10 cancer types-and successfully extended to 2675 tumors (12 types) including cases with incomplete molecular data-MSClustering demonstrated: (i) precise classification of major cancer types and breast cancer molecular subtypes; (ii) discovery of novel pan-cancer squamous metaplastic signatures; (iii) exceptional prognostic stratification (log-rank P = 2.3 × 10-46); and (iv) superior performance over existing methods (COCA/SNF) in classification accuracy, cluster robustness, and computational efficiency. The method's multi-scale architecture uniquely resolves breast cancer heterogeneity across biological resolution levels. Pathway analysis further revealed four key oncogenic programs-proteoglycan signaling, chromosomal stability, VEGF-mediated angiogenesis, and drug metabolism-along with disruptions in immune and digestive system functions. This integrative framework marks a significant advancement in cancer genomics by enabling more refined molecular classification, enhanced prognostic insights, and deeper understanding of disease mechanisms. These results highlight the potential of MSClustering to inform the development of clinically relevant biomarkers and support more personalized strategies in precision oncology.</p>","PeriodicalId":9209,"journal":{"name":"Briefings in bioinformatics","volume":"26 5","pages":""},"PeriodicalIF":7.7000,"publicationDate":"2025-08-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12409415/pdf/","citationCount":"0","resultStr":"{\"title\":\"Mapping cancer heterogeneity: a consensus network approach to subtypes and pathways.\",\"authors\":\"Geng-Ming Hu, Hsin-Wei Chen, Chi-Ming Chen\",\"doi\":\"10.1093/bib/bbaf452\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>We introduce consensus MSClustering, an unsupervised hierarchical network approach that integrates multi-omics data to identify molecular subtypes and conserved pathways across diverse cancers. Using a novel heterogeneity index, we selected 167 key genes with functionally coherent roles validated through Gene Ontology analysis. Applied to 2439 tumors spanning 10 cancer types-and successfully extended to 2675 tumors (12 types) including cases with incomplete molecular data-MSClustering demonstrated: (i) precise classification of major cancer types and breast cancer molecular subtypes; (ii) discovery of novel pan-cancer squamous metaplastic signatures; (iii) exceptional prognostic stratification (log-rank P = 2.3 × 10-46); and (iv) superior performance over existing methods (COCA/SNF) in classification accuracy, cluster robustness, and computational efficiency. The method's multi-scale architecture uniquely resolves breast cancer heterogeneity across biological resolution levels. Pathway analysis further revealed four key oncogenic programs-proteoglycan signaling, chromosomal stability, VEGF-mediated angiogenesis, and drug metabolism-along with disruptions in immune and digestive system functions. This integrative framework marks a significant advancement in cancer genomics by enabling more refined molecular classification, enhanced prognostic insights, and deeper understanding of disease mechanisms. These results highlight the potential of MSClustering to inform the development of clinically relevant biomarkers and support more personalized strategies in precision oncology.</p>\",\"PeriodicalId\":9209,\"journal\":{\"name\":\"Briefings in bioinformatics\",\"volume\":\"26 5\",\"pages\":\"\"},\"PeriodicalIF\":7.7000,\"publicationDate\":\"2025-08-31\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12409415/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Briefings in bioinformatics\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1093/bib/bbaf452\",\"RegionNum\":2,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOCHEMICAL RESEARCH METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Briefings in bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bib/bbaf452","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
摘要
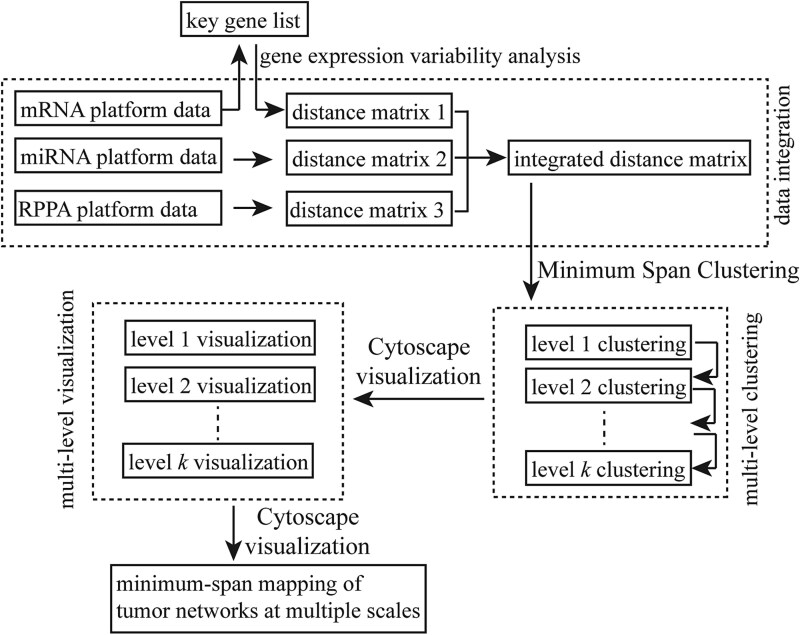
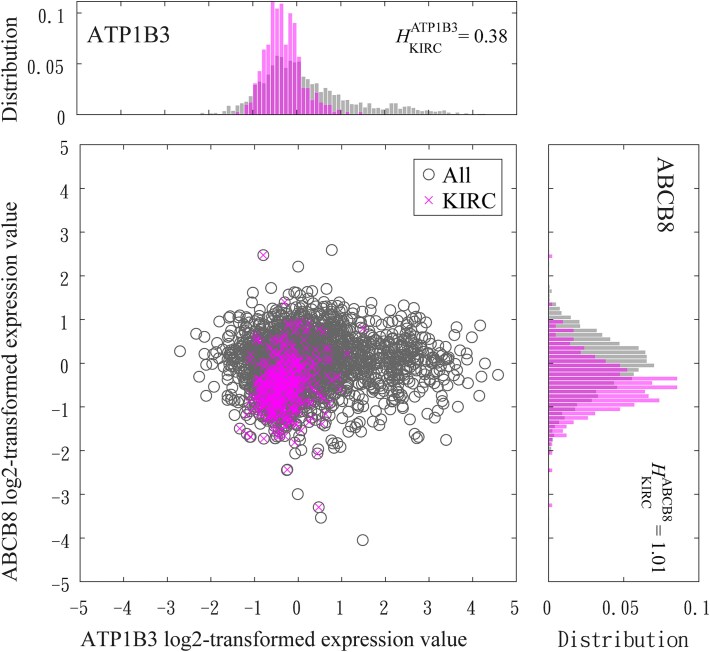
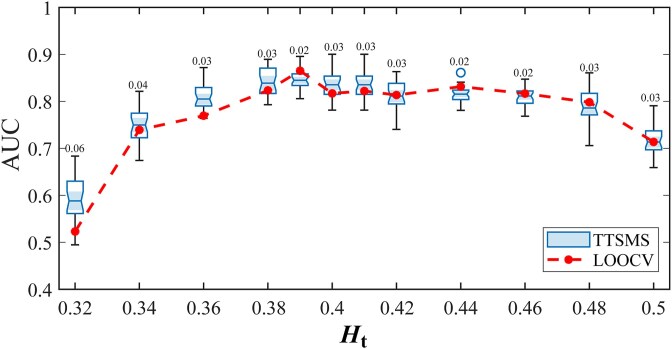
我们引入共识MSClustering,这是一种整合多组学数据的无监督分层网络方法,用于识别不同癌症的分子亚型和保守途径。利用一种新的异质性指数,我们选择了167个功能一致的关键基因,并通过基因本体分析进行了验证。应用于10种癌症类型的2439例肿瘤,并成功扩展到包括分子数据不完整的病例在内的2675例肿瘤(12种),msclustering证明了:(1)对主要癌症类型和乳腺癌分子亚型的精确分类;(ii)发现新的泛癌鳞状化生特征;(iii)异常预后分层(log-rank P = 2.3 × 10-46);(iv)在分类精度、聚类鲁棒性和计算效率方面优于现有方法(COCA/SNF)。该方法的多尺度结构独特地解决了乳腺癌在生物分辨率水平上的异质性。通路分析进一步揭示了四个关键的致癌程序-蛋白多糖信号,染色体稳定性,vegf介导的血管生成和药物代谢-以及免疫和消化系统功能的破坏。这一整合框架标志着癌症基因组学的重大进步,使更精细的分子分类、增强的预后见解和对疾病机制的更深入了解成为可能。这些结果突出了MSClustering的潜力,可以为临床相关生物标志物的开发提供信息,并支持精准肿瘤学中更个性化的策略。
Mapping cancer heterogeneity: a consensus network approach to subtypes and pathways.
We introduce consensus MSClustering, an unsupervised hierarchical network approach that integrates multi-omics data to identify molecular subtypes and conserved pathways across diverse cancers. Using a novel heterogeneity index, we selected 167 key genes with functionally coherent roles validated through Gene Ontology analysis. Applied to 2439 tumors spanning 10 cancer types-and successfully extended to 2675 tumors (12 types) including cases with incomplete molecular data-MSClustering demonstrated: (i) precise classification of major cancer types and breast cancer molecular subtypes; (ii) discovery of novel pan-cancer squamous metaplastic signatures; (iii) exceptional prognostic stratification (log-rank P = 2.3 × 10-46); and (iv) superior performance over existing methods (COCA/SNF) in classification accuracy, cluster robustness, and computational efficiency. The method's multi-scale architecture uniquely resolves breast cancer heterogeneity across biological resolution levels. Pathway analysis further revealed four key oncogenic programs-proteoglycan signaling, chromosomal stability, VEGF-mediated angiogenesis, and drug metabolism-along with disruptions in immune and digestive system functions. This integrative framework marks a significant advancement in cancer genomics by enabling more refined molecular classification, enhanced prognostic insights, and deeper understanding of disease mechanisms. These results highlight the potential of MSClustering to inform the development of clinically relevant biomarkers and support more personalized strategies in precision oncology.
期刊介绍:
Briefings in Bioinformatics is an international journal serving as a platform for researchers and educators in the life sciences. It also appeals to mathematicians, statisticians, and computer scientists applying their expertise to biological challenges. The journal focuses on reviews tailored for users of databases and analytical tools in contemporary genetics, molecular and systems biology. It stands out by offering practical assistance and guidance to non-specialists in computerized methodologies. Covering a wide range from introductory concepts to specific protocols and analyses, the papers address bacterial, plant, fungal, animal, and human data.
The journal's detailed subject areas include genetic studies of phenotypes and genotypes, mapping, DNA sequencing, expression profiling, gene expression studies, microarrays, alignment methods, protein profiles and HMMs, lipids, metabolic and signaling pathways, structure determination and function prediction, phylogenetic studies, and education and training.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


