Haotian Ma, Zhengjia Wang, Xiang Zhang, John F Magnotti, Michael S Beauchamp
{"title":"基于一致视听语音训练的深度神经网络报告了McGurk效应。","authors":"Haotian Ma, Zhengjia Wang, Xiang Zhang, John F Magnotti, Michael S Beauchamp","doi":"10.1101/2025.08.20.671347","DOIUrl":null,"url":null,"abstract":"<p><p>In the McGurk effect, incongruent auditory and visual syllables are perceived as a third, illusory syllable. The prevailing explanation for the effect is that the illusory syllable is a consensus percept intermediate between otherwise incompatible auditory and visual representations. To test this idea, we turned to a deep neural network known as AVHuBERT that transcribes audiovisual speech with high accuracy. Critically, AVHuBERT was trained only with <i>congruent</i> audiovisual speech, without exposure to McGurk stimuli or other incongruent speech. In the current study, when tested with congruent audiovisual \"ba\", \"ga\" and \"da\" syllables recorded from 8 different talkers, AVHuBERT transcribed them with near-perfect accuracy, and showed a human-like pattern of highest accuracy for audiovisual speech, slightly lower accuracy for auditory-only speech, and low accuracy for visual-only speech. When presented with incongruent McGurk syllables (auditory \"ba\" paired with visual \"ga\"), AVHuBERT reported the McGurk fusion percept of \"da\" at a rate of 25%, many-fold greater than the rate for either auditory or visual components of the McGurk stimulus presented on their own. To examine the individual variability that is hallmark of human perception of the McGurk effect, 100 variants of AVHuBERT were constructed. Like human observers, AVHuBERT variants was consistently accurate for congruent syllables but highly variable for McGurk syllables. Similarities between the responses of AVHuBERT and humans to congruent and incongruent audiovisual speech, including the McGurk effect, suggests that DNNs may be a useful tool for interrogating the perceptual and neural mechanisms of human audiovisual speech perception.</p>","PeriodicalId":519960,"journal":{"name":"bioRxiv : the preprint server for biology","volume":" ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2025-09-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12393562/pdf/","citationCount":"0","resultStr":"{\"title\":\"A Deep Neural Network Trained on Congruent Audiovisual Speech Reports the McGurk Effect.\",\"authors\":\"Haotian Ma, Zhengjia Wang, Xiang Zhang, John F Magnotti, Michael S Beauchamp\",\"doi\":\"10.1101/2025.08.20.671347\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>In the McGurk effect, incongruent auditory and visual syllables are perceived as a third, illusory syllable. The prevailing explanation for the effect is that the illusory syllable is a consensus percept intermediate between otherwise incompatible auditory and visual representations. To test this idea, we turned to a deep neural network known as AVHuBERT that transcribes audiovisual speech with high accuracy. Critically, AVHuBERT was trained only with <i>congruent</i> audiovisual speech, without exposure to McGurk stimuli or other incongruent speech. In the current study, when tested with congruent audiovisual \\\"ba\\\", \\\"ga\\\" and \\\"da\\\" syllables recorded from 8 different talkers, AVHuBERT transcribed them with near-perfect accuracy, and showed a human-like pattern of highest accuracy for audiovisual speech, slightly lower accuracy for auditory-only speech, and low accuracy for visual-only speech. When presented with incongruent McGurk syllables (auditory \\\"ba\\\" paired with visual \\\"ga\\\"), AVHuBERT reported the McGurk fusion percept of \\\"da\\\" at a rate of 25%, many-fold greater than the rate for either auditory or visual components of the McGurk stimulus presented on their own. To examine the individual variability that is hallmark of human perception of the McGurk effect, 100 variants of AVHuBERT were constructed. Like human observers, AVHuBERT variants was consistently accurate for congruent syllables but highly variable for McGurk syllables. Similarities between the responses of AVHuBERT and humans to congruent and incongruent audiovisual speech, including the McGurk effect, suggests that DNNs may be a useful tool for interrogating the perceptual and neural mechanisms of human audiovisual speech perception.</p>\",\"PeriodicalId\":519960,\"journal\":{\"name\":\"bioRxiv : the preprint server for biology\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-09-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12393562/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"bioRxiv : the preprint server for biology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1101/2025.08.20.671347\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"bioRxiv : the preprint server for biology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1101/2025.08.20.671347","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
A Deep Neural Network Trained on Congruent Audiovisual Speech Reports the McGurk Effect.
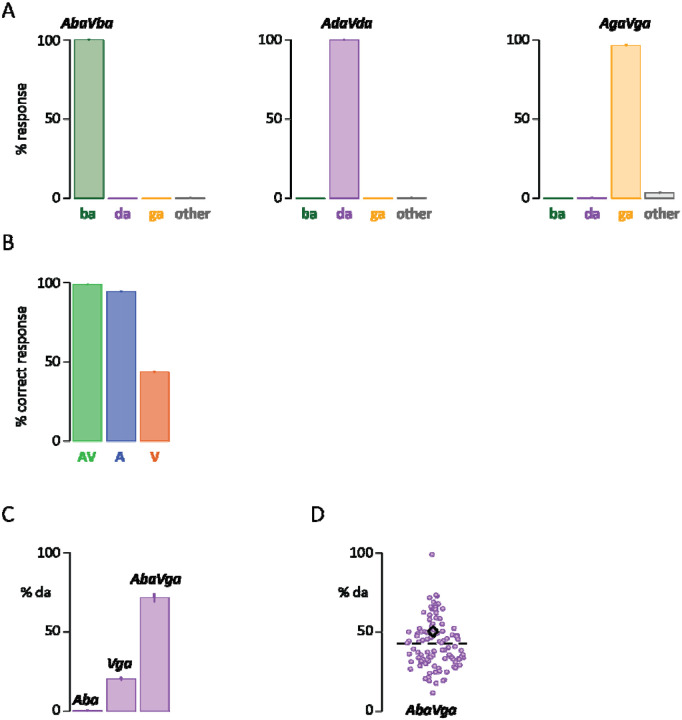
In the McGurk effect, incongruent auditory and visual syllables are perceived as a third, illusory syllable. The prevailing explanation for the effect is that the illusory syllable is a consensus percept intermediate between otherwise incompatible auditory and visual representations. To test this idea, we turned to a deep neural network known as AVHuBERT that transcribes audiovisual speech with high accuracy. Critically, AVHuBERT was trained only with congruent audiovisual speech, without exposure to McGurk stimuli or other incongruent speech. In the current study, when tested with congruent audiovisual "ba", "ga" and "da" syllables recorded from 8 different talkers, AVHuBERT transcribed them with near-perfect accuracy, and showed a human-like pattern of highest accuracy for audiovisual speech, slightly lower accuracy for auditory-only speech, and low accuracy for visual-only speech. When presented with incongruent McGurk syllables (auditory "ba" paired with visual "ga"), AVHuBERT reported the McGurk fusion percept of "da" at a rate of 25%, many-fold greater than the rate for either auditory or visual components of the McGurk stimulus presented on their own. To examine the individual variability that is hallmark of human perception of the McGurk effect, 100 variants of AVHuBERT were constructed. Like human observers, AVHuBERT variants was consistently accurate for congruent syllables but highly variable for McGurk syllables. Similarities between the responses of AVHuBERT and humans to congruent and incongruent audiovisual speech, including the McGurk effect, suggests that DNNs may be a useful tool for interrogating the perceptual and neural mechanisms of human audiovisual speech perception.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


