{"title":"MolPrompt:用知识提示改进多模态分子预训练。","authors":"Yang Li, Chang Liu, Xin Gao, Guohua Wang","doi":"10.1093/bioinformatics/btaf466","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Molecular pre-training has emerged as a foundational approach in computational drug discovery, enabling the extraction of expressive molecular representations from large-scale unlabeled datasets. However, existing methods largely focus on topological or structural features, often neglecting critical physicochemical attributes embedded in molecular systems.</p><p><strong>Result: </strong>We present MolPrompt, a knowledge-enhanced multimodal pre-training framework that integrates molecular graphs and textual descriptions via contrastive learning. MolPrompt employs a dual-encoder architecture consisting of Graphormer for graph encoding and BERT for textual encoding, and introduces knowledge prompts, semantic embeddings constructed by converting molecular descriptors into natural language, into the graph encoder to guide structure-aware representation learning. Across tasks including molecular property prediction, toxicity estimation, cross-modal retrieval, and anticancer inhibitor identification, MolPrompt consistently surpasses state-of-the-art baselines. These results highlight the value of embedding domain knowledge into structural learning to improve the depth, interpretability, and transferability of molecular representations.</p><p><strong>Availability and implementation: </strong>The source code of MolPrompt is available at: https://github.com/catly/MolPrompt.</p>","PeriodicalId":93899,"journal":{"name":"Bioinformatics (Oxford, England)","volume":" ","pages":""},"PeriodicalIF":5.4000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12448219/pdf/","citationCount":"0","resultStr":"{\"title\":\"MolPrompt: improving multi-modal molecular pre-training with knowledge prompts.\",\"authors\":\"Yang Li, Chang Liu, Xin Gao, Guohua Wang\",\"doi\":\"10.1093/bioinformatics/btaf466\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Motivation: </strong>Molecular pre-training has emerged as a foundational approach in computational drug discovery, enabling the extraction of expressive molecular representations from large-scale unlabeled datasets. However, existing methods largely focus on topological or structural features, often neglecting critical physicochemical attributes embedded in molecular systems.</p><p><strong>Result: </strong>We present MolPrompt, a knowledge-enhanced multimodal pre-training framework that integrates molecular graphs and textual descriptions via contrastive learning. MolPrompt employs a dual-encoder architecture consisting of Graphormer for graph encoding and BERT for textual encoding, and introduces knowledge prompts, semantic embeddings constructed by converting molecular descriptors into natural language, into the graph encoder to guide structure-aware representation learning. Across tasks including molecular property prediction, toxicity estimation, cross-modal retrieval, and anticancer inhibitor identification, MolPrompt consistently surpasses state-of-the-art baselines. These results highlight the value of embedding domain knowledge into structural learning to improve the depth, interpretability, and transferability of molecular representations.</p><p><strong>Availability and implementation: </strong>The source code of MolPrompt is available at: https://github.com/catly/MolPrompt.</p>\",\"PeriodicalId\":93899,\"journal\":{\"name\":\"Bioinformatics (Oxford, England)\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":5.4000,\"publicationDate\":\"2025-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12448219/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics (Oxford, England)\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/bioinformatics/btaf466\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics (Oxford, England)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioinformatics/btaf466","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
MolPrompt: improving multi-modal molecular pre-training with knowledge prompts.
Motivation: Molecular pre-training has emerged as a foundational approach in computational drug discovery, enabling the extraction of expressive molecular representations from large-scale unlabeled datasets. However, existing methods largely focus on topological or structural features, often neglecting critical physicochemical attributes embedded in molecular systems.
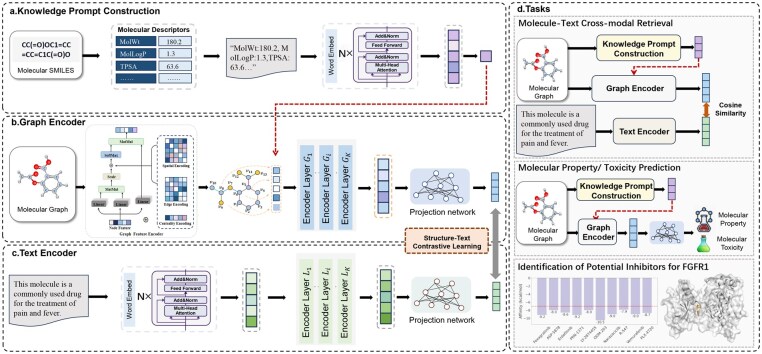
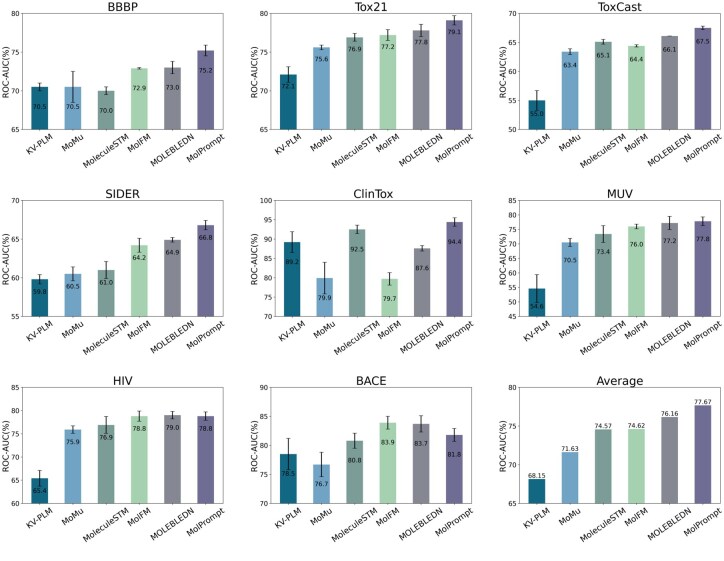
Result: We present MolPrompt, a knowledge-enhanced multimodal pre-training framework that integrates molecular graphs and textual descriptions via contrastive learning. MolPrompt employs a dual-encoder architecture consisting of Graphormer for graph encoding and BERT for textual encoding, and introduces knowledge prompts, semantic embeddings constructed by converting molecular descriptors into natural language, into the graph encoder to guide structure-aware representation learning. Across tasks including molecular property prediction, toxicity estimation, cross-modal retrieval, and anticancer inhibitor identification, MolPrompt consistently surpasses state-of-the-art baselines. These results highlight the value of embedding domain knowledge into structural learning to improve the depth, interpretability, and transferability of molecular representations.
Availability and implementation: The source code of MolPrompt is available at: https://github.com/catly/MolPrompt.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


