{"title":"快速对标诊断合并症患者的大型语言模型:利用llm作为判断方法的比较研究。","authors":"Peter Sarvari, Zaid Al-Fagih","doi":"10.2196/67661","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>On average, 1 in 10 patients die because of a diagnostic error, and medical errors represent the third largest cause of death in the United States. While large language models (LLMs) have been proposed to aid doctors in diagnoses, no research results have been published comparing the diagnostic abilities of many popular LLMs on a large, openly accessible real-patient cohort.</p><p><strong>Objective: </strong>In this study, we set out to compare the diagnostic ability of 18 LLMs from Google, OpenAI, Meta, Mistral, Cohere, and Anthropic, using 3 prompts, 2 temperature settings, and 1000 randomly selected Medical Information Mart for Intensive Care-IV (MIMIC-IV) hospital admissions. We also explore improving the diagnostic hit rate of GPT-4o 05-13 with retrieval-augmented generation (RAG) by utilizing reference ranges provided by the American Board of Internal Medicine.</p><p><strong>Methods: </strong>We evaluated the diagnostic ability of 21 LLMs, using an LLM-as-a-judge approach (an automated, LLM-based evaluation) on MIMIC-IV patient records, which contain final diagnostic codes. For each case, a separate assessor LLM (\"judge\") compared the predictor LLM's diagnostic output to the true diagnoses from the patient record. The assessor determined whether each true diagnosis was inferable from the available data and, if so, whether it was correctly predicted (\"hit\") or not (\"miss\"). Diagnoses not inferable from the patient record were excluded from the hit rate analysis. The reported hit rate was defined as the number of hits divided by the total number of hits and misses. The statistical significance of the differences in model performance was assessed using a pooled z-test for proportions.</p><p><strong>Results: </strong>Gemini 2.5 was the top performer with a hit rate of 97.4% (95% CI 97.0%-97.8%) as assessed by GPT-4.1, significantly outperforming GPT-4.1, Claude-4 Opus, and Claude Sonnet. However, GPT-4.1 ranked the highest in a separate set of experiments evaluated by GPT-4 Turbo, which tended to be less conservative than GPT-4.1 in its assessments. Significant variation in diagnostic hit rates was observed across different prompts, while changes in temperature generally had little effect. Finally, RAG significantly improved the hit rate of GPT-4o 05-13 by an average of 0.8% (P<.006).</p><p><strong>Conclusions: </strong>While the results are promising, more diverse datasets and hospital pilots, as well as close collaborations with physicians, are needed to obtain a better understanding of the diagnostic abilities of these models.</p>","PeriodicalId":73558,"journal":{"name":"JMIRx med","volume":"6 ","pages":"e67661"},"PeriodicalIF":0.0000,"publicationDate":"2025-08-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12396308/pdf/","citationCount":"0","resultStr":"{\"title\":\"Rapidly Benchmarking Large Language Models for Diagnosing Comorbid Patients: Comparative Study Leveraging the LLM-as-a-Judge Method.\",\"authors\":\"Peter Sarvari, Zaid Al-Fagih\",\"doi\":\"10.2196/67661\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>On average, 1 in 10 patients die because of a diagnostic error, and medical errors represent the third largest cause of death in the United States. While large language models (LLMs) have been proposed to aid doctors in diagnoses, no research results have been published comparing the diagnostic abilities of many popular LLMs on a large, openly accessible real-patient cohort.</p><p><strong>Objective: </strong>In this study, we set out to compare the diagnostic ability of 18 LLMs from Google, OpenAI, Meta, Mistral, Cohere, and Anthropic, using 3 prompts, 2 temperature settings, and 1000 randomly selected Medical Information Mart for Intensive Care-IV (MIMIC-IV) hospital admissions. We also explore improving the diagnostic hit rate of GPT-4o 05-13 with retrieval-augmented generation (RAG) by utilizing reference ranges provided by the American Board of Internal Medicine.</p><p><strong>Methods: </strong>We evaluated the diagnostic ability of 21 LLMs, using an LLM-as-a-judge approach (an automated, LLM-based evaluation) on MIMIC-IV patient records, which contain final diagnostic codes. For each case, a separate assessor LLM (\\\"judge\\\") compared the predictor LLM's diagnostic output to the true diagnoses from the patient record. The assessor determined whether each true diagnosis was inferable from the available data and, if so, whether it was correctly predicted (\\\"hit\\\") or not (\\\"miss\\\"). Diagnoses not inferable from the patient record were excluded from the hit rate analysis. The reported hit rate was defined as the number of hits divided by the total number of hits and misses. The statistical significance of the differences in model performance was assessed using a pooled z-test for proportions.</p><p><strong>Results: </strong>Gemini 2.5 was the top performer with a hit rate of 97.4% (95% CI 97.0%-97.8%) as assessed by GPT-4.1, significantly outperforming GPT-4.1, Claude-4 Opus, and Claude Sonnet. However, GPT-4.1 ranked the highest in a separate set of experiments evaluated by GPT-4 Turbo, which tended to be less conservative than GPT-4.1 in its assessments. Significant variation in diagnostic hit rates was observed across different prompts, while changes in temperature generally had little effect. Finally, RAG significantly improved the hit rate of GPT-4o 05-13 by an average of 0.8% (P<.006).</p><p><strong>Conclusions: </strong>While the results are promising, more diverse datasets and hospital pilots, as well as close collaborations with physicians, are needed to obtain a better understanding of the diagnostic abilities of these models.</p>\",\"PeriodicalId\":73558,\"journal\":{\"name\":\"JMIRx med\",\"volume\":\"6 \",\"pages\":\"e67661\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-08-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12396308/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIRx med\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/67661\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIRx med","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/67661","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
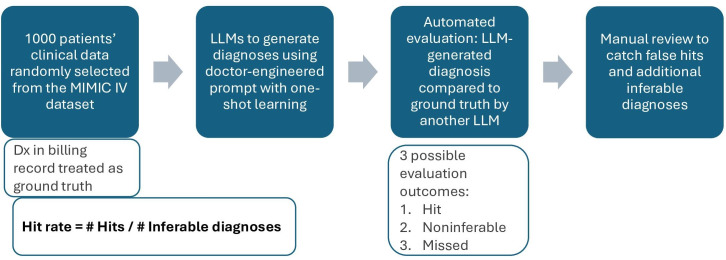
背景:平均每10名患者中就有1人死于诊断错误,医疗错误是美国第三大死亡原因。虽然大型语言模型(llm)已被提出用于帮助医生进行诊断,但目前还没有发表的研究结果来比较许多流行的llm在大型、可公开获取的真实患者队列中的诊断能力。目的:在这项研究中,我们开始比较来自谷歌、OpenAI、Meta、Mistral、Cohere和Anthropic的18个llm的诊断能力,使用3个提示、2个温度设置和1000个随机选择的重症监护- iv (MIMIC-IV)医院入院医疗信息市场。我们还利用美国内科医学委员会提供的参考范围,探讨了利用检索增强生成(RAG)提高gpt - 4005 -13的诊断准确率。方法:我们对包含最终诊断代码的MIMIC-IV患者记录使用llm作为判断方法(一种基于llm的自动化评估)评估了21例llm的诊断能力。对于每个病例,一个单独的评估者LLM(“法官”)将预测者LLM的诊断输出与患者记录中的真实诊断进行比较。评估员确定每个真实的诊断是否可以从现有数据推断出来,如果是,是否正确预测(“命中”)或不(“错过”)。不能从患者记录推断的诊断被排除在命中率分析之外。报告的命中率被定义为命中数除以命中和未命中总数。模型性能差异的统计显著性采用比例混合z检验进行评估。结果:根据GPT-4.1的评估,Gemini 2.5是表现最好的,命中率为97.4% (95% CI 97.0%-97.8%),显著优于GPT-4.1、Claude-4 Opus和Claude Sonnet。然而,GPT-4.1在GPT-4 Turbo评估的另一组实验中排名最高,GPT-4 Turbo在评估中倾向于比GPT-4.1更保守。在不同的提示中观察到诊断命中率的显著差异,而温度的变化通常影响不大。最后,RAG显著提高了gpt - 4005 -13的准确率,平均提高了0.8% (p结论:虽然结果很有希望,但需要更多样化的数据集和医院试点,以及与医生的密切合作,以更好地了解这些模型的诊断能力。
Rapidly Benchmarking Large Language Models for Diagnosing Comorbid Patients: Comparative Study Leveraging the LLM-as-a-Judge Method.
Background: On average, 1 in 10 patients die because of a diagnostic error, and medical errors represent the third largest cause of death in the United States. While large language models (LLMs) have been proposed to aid doctors in diagnoses, no research results have been published comparing the diagnostic abilities of many popular LLMs on a large, openly accessible real-patient cohort.
Objective: In this study, we set out to compare the diagnostic ability of 18 LLMs from Google, OpenAI, Meta, Mistral, Cohere, and Anthropic, using 3 prompts, 2 temperature settings, and 1000 randomly selected Medical Information Mart for Intensive Care-IV (MIMIC-IV) hospital admissions. We also explore improving the diagnostic hit rate of GPT-4o 05-13 with retrieval-augmented generation (RAG) by utilizing reference ranges provided by the American Board of Internal Medicine.
Methods: We evaluated the diagnostic ability of 21 LLMs, using an LLM-as-a-judge approach (an automated, LLM-based evaluation) on MIMIC-IV patient records, which contain final diagnostic codes. For each case, a separate assessor LLM ("judge") compared the predictor LLM's diagnostic output to the true diagnoses from the patient record. The assessor determined whether each true diagnosis was inferable from the available data and, if so, whether it was correctly predicted ("hit") or not ("miss"). Diagnoses not inferable from the patient record were excluded from the hit rate analysis. The reported hit rate was defined as the number of hits divided by the total number of hits and misses. The statistical significance of the differences in model performance was assessed using a pooled z-test for proportions.
Results: Gemini 2.5 was the top performer with a hit rate of 97.4% (95% CI 97.0%-97.8%) as assessed by GPT-4.1, significantly outperforming GPT-4.1, Claude-4 Opus, and Claude Sonnet. However, GPT-4.1 ranked the highest in a separate set of experiments evaluated by GPT-4 Turbo, which tended to be less conservative than GPT-4.1 in its assessments. Significant variation in diagnostic hit rates was observed across different prompts, while changes in temperature generally had little effect. Finally, RAG significantly improved the hit rate of GPT-4o 05-13 by an average of 0.8% (P<.006).
Conclusions: While the results are promising, more diverse datasets and hospital pilots, as well as close collaborations with physicians, are needed to obtain a better understanding of the diagnostic abilities of these models.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


