{"title":"使用个人基础模型的人工智能个性化可以带来更精确的数字治疗。","authors":"Peter Washington","doi":"10.2196/55530","DOIUrl":null,"url":null,"abstract":"<p><p>Digital health interventions often use machine learning (ML) models to make predictions of repeated adverse health events. For example, models may be used to analyze patient data to identify patterns that can anticipate the likelihood of disease exacerbations, enabling timely interventions and personalized treatment plans. However, many digital health applications require the prediction of highly heterogeneous and nuanced health events. The cross-subject variability of these events makes traditional ML approaches, where a single generalized model is trained to classify a particular condition, unlikely to generalize to patients outside of the training set. A natural solution is to train a separate model for each individual or subgroup, essentially overfitting the model to the unique characteristics of the individual without negatively overfitting in terms of the desired prediction task. Such an approach has traditionally required extensive data labels from each individual, a reality that has rendered personalized ML infeasible for precision health care. The recent popularization of self-supervised learning, however, provides a solution to this issue: by pretraining deep learning models on the vast array of unlabeled data streams arising from patient-generated health data, personalized models can be fine-tuned to predict the health outcome of interest with fewer labels than purely supervised approaches, making personalization of deep learning models much more achievable from a practical perspective. This perspective describes the current state-of-the-art in both self-supervised learning and ML personalization for health care as well as growing efforts to combine these two ideas by conducting self-supervised pretraining on an individual's data. However, there are practical challenges that must be addressed in order to fully realize this potential, such as human-computer interaction innovations to ensure consistent labeling practices within a single participant.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e55530"},"PeriodicalIF":2.0000,"publicationDate":"2025-08-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12411786/pdf/","citationCount":"0","resultStr":"{\"title\":\"Personalization of AI Using Personal Foundation Models Can Lead to More Precise Digital Therapeutics.\",\"authors\":\"Peter Washington\",\"doi\":\"10.2196/55530\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Digital health interventions often use machine learning (ML) models to make predictions of repeated adverse health events. For example, models may be used to analyze patient data to identify patterns that can anticipate the likelihood of disease exacerbations, enabling timely interventions and personalized treatment plans. However, many digital health applications require the prediction of highly heterogeneous and nuanced health events. The cross-subject variability of these events makes traditional ML approaches, where a single generalized model is trained to classify a particular condition, unlikely to generalize to patients outside of the training set. A natural solution is to train a separate model for each individual or subgroup, essentially overfitting the model to the unique characteristics of the individual without negatively overfitting in terms of the desired prediction task. Such an approach has traditionally required extensive data labels from each individual, a reality that has rendered personalized ML infeasible for precision health care. The recent popularization of self-supervised learning, however, provides a solution to this issue: by pretraining deep learning models on the vast array of unlabeled data streams arising from patient-generated health data, personalized models can be fine-tuned to predict the health outcome of interest with fewer labels than purely supervised approaches, making personalization of deep learning models much more achievable from a practical perspective. This perspective describes the current state-of-the-art in both self-supervised learning and ML personalization for health care as well as growing efforts to combine these two ideas by conducting self-supervised pretraining on an individual's data. However, there are practical challenges that must be addressed in order to fully realize this potential, such as human-computer interaction innovations to ensure consistent labeling practices within a single participant.</p>\",\"PeriodicalId\":73551,\"journal\":{\"name\":\"JMIR AI\",\"volume\":\"4 \",\"pages\":\"e55530\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-08-21\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12411786/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/55530\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/55530","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Personalization of AI Using Personal Foundation Models Can Lead to More Precise Digital Therapeutics.
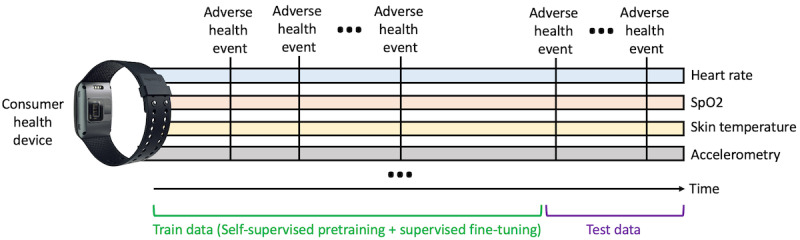
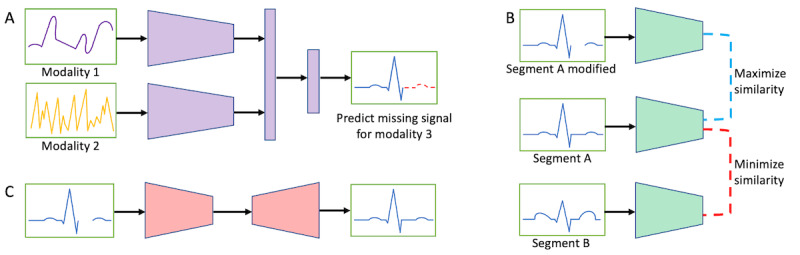
Digital health interventions often use machine learning (ML) models to make predictions of repeated adverse health events. For example, models may be used to analyze patient data to identify patterns that can anticipate the likelihood of disease exacerbations, enabling timely interventions and personalized treatment plans. However, many digital health applications require the prediction of highly heterogeneous and nuanced health events. The cross-subject variability of these events makes traditional ML approaches, where a single generalized model is trained to classify a particular condition, unlikely to generalize to patients outside of the training set. A natural solution is to train a separate model for each individual or subgroup, essentially overfitting the model to the unique characteristics of the individual without negatively overfitting in terms of the desired prediction task. Such an approach has traditionally required extensive data labels from each individual, a reality that has rendered personalized ML infeasible for precision health care. The recent popularization of self-supervised learning, however, provides a solution to this issue: by pretraining deep learning models on the vast array of unlabeled data streams arising from patient-generated health data, personalized models can be fine-tuned to predict the health outcome of interest with fewer labels than purely supervised approaches, making personalization of deep learning models much more achievable from a practical perspective. This perspective describes the current state-of-the-art in both self-supervised learning and ML personalization for health care as well as growing efforts to combine these two ideas by conducting self-supervised pretraining on an individual's data. However, there are practical challenges that must be addressed in order to fully realize this potential, such as human-computer interaction innovations to ensure consistent labeling practices within a single participant.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


