{"title":"DeepSeek和GPT模型在儿科委员会准备问题中的表现:比较评价。","authors":"Masab Mansoor, Andrew Ibrahim, Ali Hamide","doi":"10.2196/76056","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Limited research exists evaluating artificial intelligence (AI) performance on standardized pediatric assessments. This study evaluated 3 leading AI models on pediatric board preparation questions.</p><p><strong>Objective: </strong>The aim of this study is to evaluate and compare the performance of 3 leading large language models (LLMs) on pediatric board examination preparation questions and contextualize their performance against human physician benchmarks.</p><p><strong>Methods: </strong>We analyzed DeepSeek-R1, ChatGPT-4, and ChatGPT-4.5 using 266 multiple-choice questions from the 2023 PREP Self-Assessment. Performance was compared to published American Board of Pediatrics first-time pass rates.</p><p><strong>Results: </strong>DeepSeek-R1 exhibited the highest accuracy at 98.1% (261/266 correct responses). ChatGPT-4.5 achieved 96.6% accuracy (257/266), performing at the upper threshold of human performance. ChatGPT-4 demonstrated 82.7% accuracy (220/266), comparable to the lower range of human pass rates. Error pattern analysis revealed that AI models most commonly struggled with questions requiring integration of complex clinical presentations with rare disease knowledge.</p><p><strong>Conclusions: </strong>DeepSeek-R1 demonstrated exceptional performance exceeding typical American Board of Pediatrics pass rates, suggesting potential applications in medical education and clinical support, though further research on complex clinical reasoning is needed.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e76056"},"PeriodicalIF":2.0000,"publicationDate":"2025-08-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12384676/pdf/","citationCount":"0","resultStr":"{\"title\":\"Performance of DeepSeek and GPT Models on Pediatric Board Preparation Questions: Comparative Evaluation.\",\"authors\":\"Masab Mansoor, Andrew Ibrahim, Ali Hamide\",\"doi\":\"10.2196/76056\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Limited research exists evaluating artificial intelligence (AI) performance on standardized pediatric assessments. This study evaluated 3 leading AI models on pediatric board preparation questions.</p><p><strong>Objective: </strong>The aim of this study is to evaluate and compare the performance of 3 leading large language models (LLMs) on pediatric board examination preparation questions and contextualize their performance against human physician benchmarks.</p><p><strong>Methods: </strong>We analyzed DeepSeek-R1, ChatGPT-4, and ChatGPT-4.5 using 266 multiple-choice questions from the 2023 PREP Self-Assessment. Performance was compared to published American Board of Pediatrics first-time pass rates.</p><p><strong>Results: </strong>DeepSeek-R1 exhibited the highest accuracy at 98.1% (261/266 correct responses). ChatGPT-4.5 achieved 96.6% accuracy (257/266), performing at the upper threshold of human performance. ChatGPT-4 demonstrated 82.7% accuracy (220/266), comparable to the lower range of human pass rates. Error pattern analysis revealed that AI models most commonly struggled with questions requiring integration of complex clinical presentations with rare disease knowledge.</p><p><strong>Conclusions: </strong>DeepSeek-R1 demonstrated exceptional performance exceeding typical American Board of Pediatrics pass rates, suggesting potential applications in medical education and clinical support, though further research on complex clinical reasoning is needed.</p>\",\"PeriodicalId\":73551,\"journal\":{\"name\":\"JMIR AI\",\"volume\":\"4 \",\"pages\":\"e76056\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-08-27\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12384676/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/76056\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/76056","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Performance of DeepSeek and GPT Models on Pediatric Board Preparation Questions: Comparative Evaluation.
Background: Limited research exists evaluating artificial intelligence (AI) performance on standardized pediatric assessments. This study evaluated 3 leading AI models on pediatric board preparation questions.
Objective: The aim of this study is to evaluate and compare the performance of 3 leading large language models (LLMs) on pediatric board examination preparation questions and contextualize their performance against human physician benchmarks.
Methods: We analyzed DeepSeek-R1, ChatGPT-4, and ChatGPT-4.5 using 266 multiple-choice questions from the 2023 PREP Self-Assessment. Performance was compared to published American Board of Pediatrics first-time pass rates.
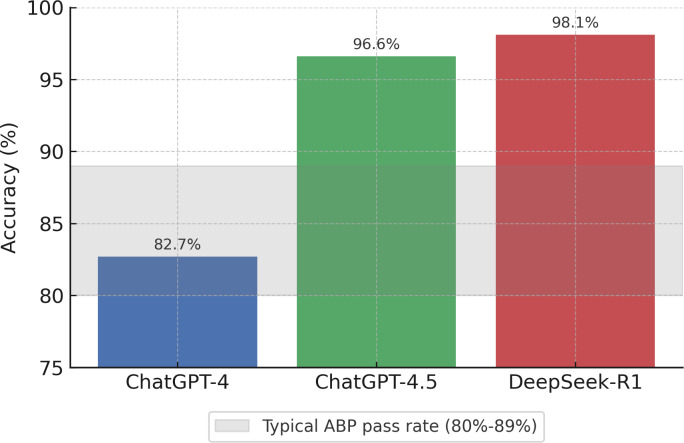
Results: DeepSeek-R1 exhibited the highest accuracy at 98.1% (261/266 correct responses). ChatGPT-4.5 achieved 96.6% accuracy (257/266), performing at the upper threshold of human performance. ChatGPT-4 demonstrated 82.7% accuracy (220/266), comparable to the lower range of human pass rates. Error pattern analysis revealed that AI models most commonly struggled with questions requiring integration of complex clinical presentations with rare disease knowledge.
Conclusions: DeepSeek-R1 demonstrated exceptional performance exceeding typical American Board of Pediatrics pass rates, suggesting potential applications in medical education and clinical support, though further research on complex clinical reasoning is needed.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


