Phuong Dinh Ngo, Miguel Ángel Tejedor Hernández, Taridzo Chomutare, Andrius Budrionis, Therese Olsen Svenning, Torbjørn Torsvik, Anastasios Lamproudis, Hercules Dalianis
{"title":"来自国际疾病统计分类转换器的nordecline双向编码器表示的领域特定预训练,第十版,挪威临床文本中的代码预测:模型开发和评估研究。","authors":"Phuong Dinh Ngo, Miguel Ángel Tejedor Hernández, Taridzo Chomutare, Andrius Budrionis, Therese Olsen Svenning, Torbjørn Torsvik, Anastasios Lamproudis, Hercules Dalianis","doi":"10.2196/66153","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Accurately assigning ICD-10 (International Statistical Classification of Diseases, Tenth Revision) codes is critical for clinical documentation, reimbursement processes, epidemiological studies, and health care planning. Manual coding is time-consuming, labor-intensive, and prone to errors, underscoring the need for automated solutions within the Norwegian health care system. Recent advances in natural language processing (NLP) and transformer-based language models have shown promising results in automating ICD (International Classification of Diseases) coding in several languages. However, prior work has focused primarily on English and other high-resource languages, leaving a gap in Norwegian-specific clinical NLP research.</p><p><strong>Objective: </strong>This study introduces 2 versions of NorDeClin-BERT (NorDeClin Bidirectional Encoder Representations from Transformers), domain-specific Norwegian BERT-based models pretrained on a large corpus of Norwegian clinical text to enhance their understanding of medical language. Both models were subsequently fine-tuned to predict ICD-10 diagnosis codes. We aimed to evaluate the impact of domain-specific pretraining and model size on classification performance and to compare NorDeClin-BERT with general-purpose and cross-lingual BERT models in the context of Norwegian ICD-10 coding.</p><p><strong>Methods: </strong>Two versions of NorDeClin-BERT were pretrained on the ClinCode Gastro Corpus, a large-scale dataset comprising 8.8 million deidentified Norwegian clinical notes, to enhance domain-specific language modeling. The base model builds upon NorBERT3-base and was pretrained on a large, relevant subset of the corpus, while the large model builds upon NorBERT3-large and was trained on the full dataset. Both models were benchmarked against SweDeClin-BERT, ScandiBERT, NorBERT3-base, and NorBERT3-large, using standard evaluation metrics: accuracy, precision, recall, and F1-score.</p><p><strong>Results: </strong>The results show that both versions of NorDeClin-BERT outperformed general-purpose Norwegian BERT models and Swedish clinical BERT models in classifying both prevalent and less common ICD-10 codes. Notably, NorDeClin-BERT-large achieved the highest overall performance across evaluation metrics, demonstrating the impact of domain-specific clinical pretraining in Norwegian. These results highlight that domain-specific pretraining on Norwegian clinical text, combined with model capacity, improves ICD-10 classification accuracy compared with general-domain Norwegian models and Swedish models pretrained on clinical text. Furthermore, while Swedish clinical models demonstrated some transferability to Norwegian, their performance remained suboptimal, emphasizing the necessity of Norwegian-specific clinical pretraining.</p><p><strong>Conclusions: </strong>This study highlights the potential of NorDeClin-BERT to improve ICD-10 code classification for the gastroenterology domain in Norway, ultimately streamlining clinical documentation, reporting processes, reducing administrative burden, and enhancing coding accuracy in Norwegian health care institutions. The benchmarking evaluation establishes NorDeClin-BERT as a state-of-the-art model for processing Norwegian clinical text and predicting ICD-10 coding, establishing a new baseline for future research in Norwegian medical NLP. Future work may explore further domain adaptation techniques, external knowledge integration, and cross-hospital generalizability to enhance ICD coding performance across broader clinical settings.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e66153"},"PeriodicalIF":2.0000,"publicationDate":"2025-08-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12377785/pdf/","citationCount":"0","resultStr":"{\"title\":\"Domain-Specific Pretraining of NorDeClin-Bidirectional Encoder Representations From Transformers for <i>International Statistical Classification of Diseases, Tenth Revision,</i> Code Prediction in Norwegian Clinical Texts: Model Development and Evaluation Study.\",\"authors\":\"Phuong Dinh Ngo, Miguel Ángel Tejedor Hernández, Taridzo Chomutare, Andrius Budrionis, Therese Olsen Svenning, Torbjørn Torsvik, Anastasios Lamproudis, Hercules Dalianis\",\"doi\":\"10.2196/66153\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Accurately assigning ICD-10 (International Statistical Classification of Diseases, Tenth Revision) codes is critical for clinical documentation, reimbursement processes, epidemiological studies, and health care planning. Manual coding is time-consuming, labor-intensive, and prone to errors, underscoring the need for automated solutions within the Norwegian health care system. Recent advances in natural language processing (NLP) and transformer-based language models have shown promising results in automating ICD (International Classification of Diseases) coding in several languages. However, prior work has focused primarily on English and other high-resource languages, leaving a gap in Norwegian-specific clinical NLP research.</p><p><strong>Objective: </strong>This study introduces 2 versions of NorDeClin-BERT (NorDeClin Bidirectional Encoder Representations from Transformers), domain-specific Norwegian BERT-based models pretrained on a large corpus of Norwegian clinical text to enhance their understanding of medical language. Both models were subsequently fine-tuned to predict ICD-10 diagnosis codes. We aimed to evaluate the impact of domain-specific pretraining and model size on classification performance and to compare NorDeClin-BERT with general-purpose and cross-lingual BERT models in the context of Norwegian ICD-10 coding.</p><p><strong>Methods: </strong>Two versions of NorDeClin-BERT were pretrained on the ClinCode Gastro Corpus, a large-scale dataset comprising 8.8 million deidentified Norwegian clinical notes, to enhance domain-specific language modeling. The base model builds upon NorBERT3-base and was pretrained on a large, relevant subset of the corpus, while the large model builds upon NorBERT3-large and was trained on the full dataset. Both models were benchmarked against SweDeClin-BERT, ScandiBERT, NorBERT3-base, and NorBERT3-large, using standard evaluation metrics: accuracy, precision, recall, and F1-score.</p><p><strong>Results: </strong>The results show that both versions of NorDeClin-BERT outperformed general-purpose Norwegian BERT models and Swedish clinical BERT models in classifying both prevalent and less common ICD-10 codes. Notably, NorDeClin-BERT-large achieved the highest overall performance across evaluation metrics, demonstrating the impact of domain-specific clinical pretraining in Norwegian. These results highlight that domain-specific pretraining on Norwegian clinical text, combined with model capacity, improves ICD-10 classification accuracy compared with general-domain Norwegian models and Swedish models pretrained on clinical text. Furthermore, while Swedish clinical models demonstrated some transferability to Norwegian, their performance remained suboptimal, emphasizing the necessity of Norwegian-specific clinical pretraining.</p><p><strong>Conclusions: </strong>This study highlights the potential of NorDeClin-BERT to improve ICD-10 code classification for the gastroenterology domain in Norway, ultimately streamlining clinical documentation, reporting processes, reducing administrative burden, and enhancing coding accuracy in Norwegian health care institutions. The benchmarking evaluation establishes NorDeClin-BERT as a state-of-the-art model for processing Norwegian clinical text and predicting ICD-10 coding, establishing a new baseline for future research in Norwegian medical NLP. Future work may explore further domain adaptation techniques, external knowledge integration, and cross-hospital generalizability to enhance ICD coding performance across broader clinical settings.</p>\",\"PeriodicalId\":73551,\"journal\":{\"name\":\"JMIR AI\",\"volume\":\"4 \",\"pages\":\"e66153\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-08-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12377785/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/66153\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/66153","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Domain-Specific Pretraining of NorDeClin-Bidirectional Encoder Representations From Transformers for International Statistical Classification of Diseases, Tenth Revision, Code Prediction in Norwegian Clinical Texts: Model Development and Evaluation Study.
Background: Accurately assigning ICD-10 (International Statistical Classification of Diseases, Tenth Revision) codes is critical for clinical documentation, reimbursement processes, epidemiological studies, and health care planning. Manual coding is time-consuming, labor-intensive, and prone to errors, underscoring the need for automated solutions within the Norwegian health care system. Recent advances in natural language processing (NLP) and transformer-based language models have shown promising results in automating ICD (International Classification of Diseases) coding in several languages. However, prior work has focused primarily on English and other high-resource languages, leaving a gap in Norwegian-specific clinical NLP research.
Objective: This study introduces 2 versions of NorDeClin-BERT (NorDeClin Bidirectional Encoder Representations from Transformers), domain-specific Norwegian BERT-based models pretrained on a large corpus of Norwegian clinical text to enhance their understanding of medical language. Both models were subsequently fine-tuned to predict ICD-10 diagnosis codes. We aimed to evaluate the impact of domain-specific pretraining and model size on classification performance and to compare NorDeClin-BERT with general-purpose and cross-lingual BERT models in the context of Norwegian ICD-10 coding.
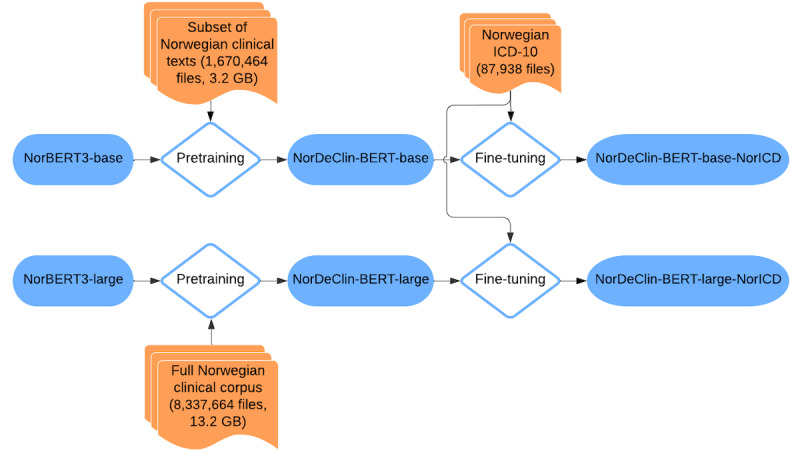
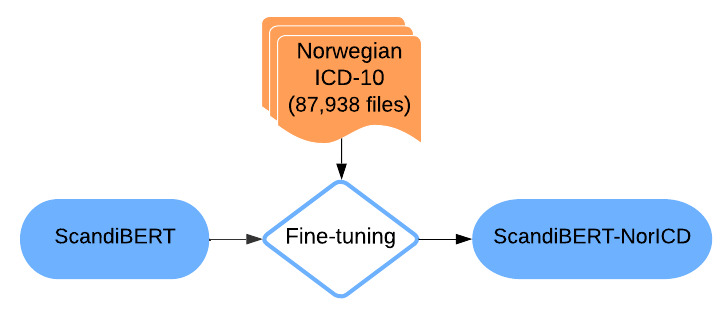
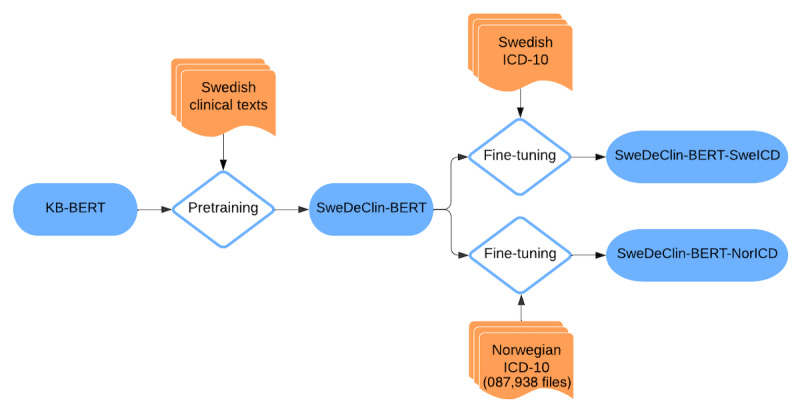
Methods: Two versions of NorDeClin-BERT were pretrained on the ClinCode Gastro Corpus, a large-scale dataset comprising 8.8 million deidentified Norwegian clinical notes, to enhance domain-specific language modeling. The base model builds upon NorBERT3-base and was pretrained on a large, relevant subset of the corpus, while the large model builds upon NorBERT3-large and was trained on the full dataset. Both models were benchmarked against SweDeClin-BERT, ScandiBERT, NorBERT3-base, and NorBERT3-large, using standard evaluation metrics: accuracy, precision, recall, and F1-score.
Results: The results show that both versions of NorDeClin-BERT outperformed general-purpose Norwegian BERT models and Swedish clinical BERT models in classifying both prevalent and less common ICD-10 codes. Notably, NorDeClin-BERT-large achieved the highest overall performance across evaluation metrics, demonstrating the impact of domain-specific clinical pretraining in Norwegian. These results highlight that domain-specific pretraining on Norwegian clinical text, combined with model capacity, improves ICD-10 classification accuracy compared with general-domain Norwegian models and Swedish models pretrained on clinical text. Furthermore, while Swedish clinical models demonstrated some transferability to Norwegian, their performance remained suboptimal, emphasizing the necessity of Norwegian-specific clinical pretraining.
Conclusions: This study highlights the potential of NorDeClin-BERT to improve ICD-10 code classification for the gastroenterology domain in Norway, ultimately streamlining clinical documentation, reporting processes, reducing administrative burden, and enhancing coding accuracy in Norwegian health care institutions. The benchmarking evaluation establishes NorDeClin-BERT as a state-of-the-art model for processing Norwegian clinical text and predicting ICD-10 coding, establishing a new baseline for future research in Norwegian medical NLP. Future work may explore further domain adaptation techniques, external knowledge integration, and cross-hospital generalizability to enhance ICD coding performance across broader clinical settings.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


