Julien Gobeill, Déborah Caucheteur, Alexandre Flament, Pierre-André Michel, Anaïs Mottaz, Emilie Pasche, Patrick Ruch
{"title":"释放PubMed Central补充数据文件的潜力。","authors":"Julien Gobeill, Déborah Caucheteur, Alexandre Flament, Pierre-André Michel, Anaïs Mottaz, Emilie Pasche, Patrick Ruch","doi":"10.1093/bioadv/vbaf155","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Biocuration workflows often rely on comprehensive literature searches for specific biological entities. However, standard search engines such as MEDLINE and PubMed Central provide an incomplete picture of the scientific literature because they do not index the increasing amount of valuable information published in supplementary data files. Over two years, we addressed this gap by systematically extracting text from a large proportion (85%) of these files, resulting in 35 million searchable documents. To assess the information gain provided by supplementary data files beyond the manuscripts, we searched both for mentions of dozens of Global Core Biodata Resources (GCBRs), which are fundamental biological databases essential for the life sciences. We searched for mentions of GCBR names and accession numbers, which uniquely identify biological entities within these resources.</p><p><strong>Results: </strong>The recall gain from using the supplementary data files to search for articles mentioning resource names is 6%. In addition, 97% of all accession numbers identified were published in the supplementary data files, highlighting their increasing importance for highly specific topics or curation pipelines. We show that the number of accession numbers published in the supplementary data files is increasing year on year, but that 87% of these are published in Excel files. This format facilitates human readability and accessibility, but severely limits machine reusability and interoperability. We therefore discuss alternative and complementary approaches to the publication of research data.</p><p><strong>Availability and implementation: </strong>All extracted data are accessible and searchable as a collection on the BiodiversityPMC platform (https://biodiversitypmc.sibils.org/).</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"5 1","pages":"vbaf155"},"PeriodicalIF":2.8000,"publicationDate":"2025-06-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12371329/pdf/","citationCount":"0","resultStr":"{\"title\":\"Unlocking the potential of PubMed Central supplementary data files.\",\"authors\":\"Julien Gobeill, Déborah Caucheteur, Alexandre Flament, Pierre-André Michel, Anaïs Mottaz, Emilie Pasche, Patrick Ruch\",\"doi\":\"10.1093/bioadv/vbaf155\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Motivation: </strong>Biocuration workflows often rely on comprehensive literature searches for specific biological entities. However, standard search engines such as MEDLINE and PubMed Central provide an incomplete picture of the scientific literature because they do not index the increasing amount of valuable information published in supplementary data files. Over two years, we addressed this gap by systematically extracting text from a large proportion (85%) of these files, resulting in 35 million searchable documents. To assess the information gain provided by supplementary data files beyond the manuscripts, we searched both for mentions of dozens of Global Core Biodata Resources (GCBRs), which are fundamental biological databases essential for the life sciences. We searched for mentions of GCBR names and accession numbers, which uniquely identify biological entities within these resources.</p><p><strong>Results: </strong>The recall gain from using the supplementary data files to search for articles mentioning resource names is 6%. In addition, 97% of all accession numbers identified were published in the supplementary data files, highlighting their increasing importance for highly specific topics or curation pipelines. We show that the number of accession numbers published in the supplementary data files is increasing year on year, but that 87% of these are published in Excel files. This format facilitates human readability and accessibility, but severely limits machine reusability and interoperability. We therefore discuss alternative and complementary approaches to the publication of research data.</p><p><strong>Availability and implementation: </strong>All extracted data are accessible and searchable as a collection on the BiodiversityPMC platform (https://biodiversitypmc.sibils.org/).</p>\",\"PeriodicalId\":72368,\"journal\":{\"name\":\"Bioinformatics advances\",\"volume\":\"5 1\",\"pages\":\"vbaf155\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2025-06-27\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12371329/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics advances\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/bioadv/vbaf155\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbaf155","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Unlocking the potential of PubMed Central supplementary data files.
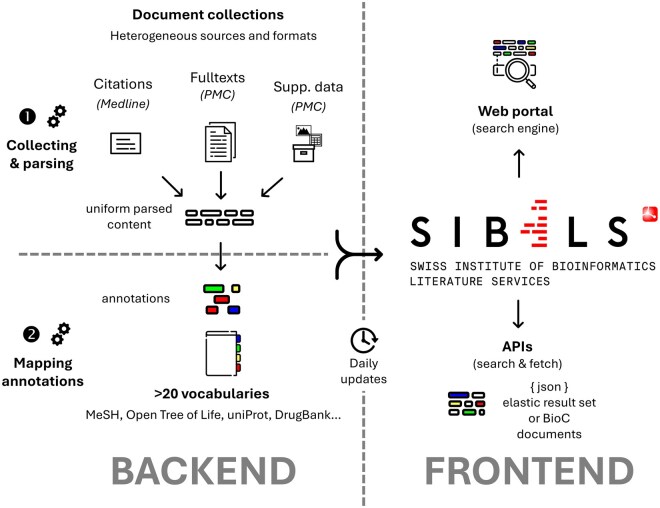
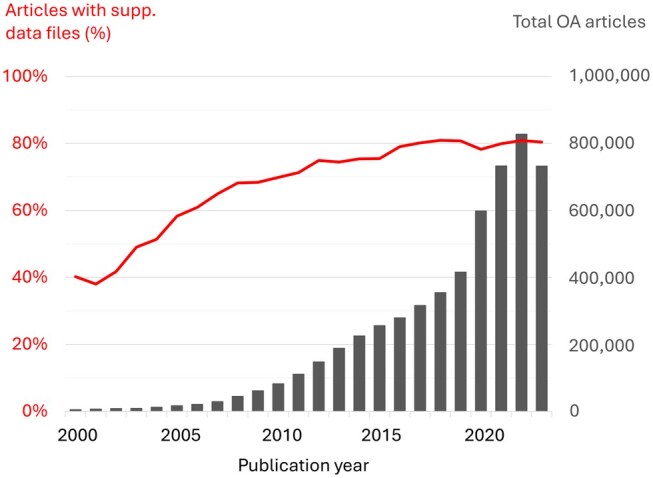
Motivation: Biocuration workflows often rely on comprehensive literature searches for specific biological entities. However, standard search engines such as MEDLINE and PubMed Central provide an incomplete picture of the scientific literature because they do not index the increasing amount of valuable information published in supplementary data files. Over two years, we addressed this gap by systematically extracting text from a large proportion (85%) of these files, resulting in 35 million searchable documents. To assess the information gain provided by supplementary data files beyond the manuscripts, we searched both for mentions of dozens of Global Core Biodata Resources (GCBRs), which are fundamental biological databases essential for the life sciences. We searched for mentions of GCBR names and accession numbers, which uniquely identify biological entities within these resources.
Results: The recall gain from using the supplementary data files to search for articles mentioning resource names is 6%. In addition, 97% of all accession numbers identified were published in the supplementary data files, highlighting their increasing importance for highly specific topics or curation pipelines. We show that the number of accession numbers published in the supplementary data files is increasing year on year, but that 87% of these are published in Excel files. This format facilitates human readability and accessibility, but severely limits machine reusability and interoperability. We therefore discuss alternative and complementary approaches to the publication of research data.
Availability and implementation: All extracted data are accessible and searchable as a collection on the BiodiversityPMC platform (https://biodiversitypmc.sibils.org/).

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


