Frederic Gaspar, Mehdi Zayene, Claire Coumau, Elliott Bertrand, Marie Bettex, Marie Annick Le Pogam, Chantal Csajka
{"title":"自然语言处理和ICD-10编码在出院总结中检测出血事件:比较横断面研究。","authors":"Frederic Gaspar, Mehdi Zayene, Claire Coumau, Elliott Bertrand, Marie Bettex, Marie Annick Le Pogam, Chantal Csajka","doi":"10.2196/67837","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Bleeding adverse drug events (ADEs), particularly among older inpatients receiving antithrombotic therapy, represent a major safety concern in hospitals. These events are often underdetected by conventional rule-based systems relying on structured electronic medical record data, such as the ICD-10 (International Statistical Classification of Diseases and Related Health Problems 10th Revision) codes, which lack the granularity to capture nuanced clinical narratives.</p><p><strong>Objective: </strong>This study aimed to develop and evaluate a natural language processing (NLP) model to detect and categorize bleeding ADEs in discharge summaries of older adults. Specifically, the model was designed to distinguish between \"clinically significant bleeding,\" \"severe bleeding,\" \"history of bleeding,\" and \"no bleeding,\" and was compared with a rule-based algorithm using ICD-10 codes.</p><p><strong>Methods: </strong>Clinicians manually annotated 400 discharge summaries, comprising 65,706 sentences, into four categories: \"no bleeding,\" \"clinically significant bleeding,\" \"severe bleeding,\" and \"history of bleeding.\" The dataset was divided into a training set (70%, 47,100 sentences) and a test set (30%, 18,606 sentences). Two detection approaches were developed and evaluated: (1) an NLP model using binary logistic regression and support vector machine classifiers, and (2) a traditional rule-based algorithm relying exclusively on predefined ICD-10 codes. To address class imbalance, with most sentences categorized as irrelevant (\"no bleeding\"), a class-weighting strategy was applied in the NLP model. Model performance was assessed using accuracy, precision, recall, F1-score, and receiver operating characteristic (ROC) curve analyses, with manual annotations as the gold standard.</p><p><strong>Results: </strong>The NLP model significantly outperformed the rule-based approach across all evaluation metrics. At the document level, the NLP model achieved macro-average scores of 0.81 for accuracy and 0.80 for F1-score. Precision was particularly high for detecting severe (0.92) and clinically significant bleeding events (0.87), demonstrating strong classification capability despite class imbalance. ROC analyses confirmed the model's robust diagnostic performance, yielding an area under the curve (AUC) of 0.91 when distinguishing irrelevant sentences from potential bleeding events, 0.88 for identifying historical mentions of bleeding, and notably, 0.94 for differentiating clinically significant from severe bleeding. In contrast, the rule-based ICD-10 model demonstrated high precision (0.94) for clinically significant bleeding but poor recall (0.03) for severe bleeding events, reflecting frequent missed detections. This limitation arose due to its reliance on commonly used ICD-10 codes (eg, gastrointestinal hemorrhage) and inadequate capture of rare severe bleeding conditions such as shock due to hemorrhage.</p><p><strong>Conclusions: </strong>This study highlights the considerable advantage of NLP over traditional ICD-10-based methods for detecting bleeding ADEs within electronic medical records. The NLP model effectively captured nuanced clinical narratives, including severity, negations, and historical bleeding events, demonstrating substantial promise for improving patient safety surveillance and clinical decision-making. Future research should extend validation across multiple institutions, diversify annotated datasets, and further refine temporal reasoning capabilities within NLP algorithms.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e67837"},"PeriodicalIF":3.8000,"publicationDate":"2025-08-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12396801/pdf/","citationCount":"0","resultStr":"{\"title\":\"Natural Language Processing and <i>ICD-10</i> Coding for Detecting Bleeding Events in Discharge Summaries: Comparative Cross-Sectional Study.\",\"authors\":\"Frederic Gaspar, Mehdi Zayene, Claire Coumau, Elliott Bertrand, Marie Bettex, Marie Annick Le Pogam, Chantal Csajka\",\"doi\":\"10.2196/67837\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Bleeding adverse drug events (ADEs), particularly among older inpatients receiving antithrombotic therapy, represent a major safety concern in hospitals. These events are often underdetected by conventional rule-based systems relying on structured electronic medical record data, such as the ICD-10 (International Statistical Classification of Diseases and Related Health Problems 10th Revision) codes, which lack the granularity to capture nuanced clinical narratives.</p><p><strong>Objective: </strong>This study aimed to develop and evaluate a natural language processing (NLP) model to detect and categorize bleeding ADEs in discharge summaries of older adults. Specifically, the model was designed to distinguish between \\\"clinically significant bleeding,\\\" \\\"severe bleeding,\\\" \\\"history of bleeding,\\\" and \\\"no bleeding,\\\" and was compared with a rule-based algorithm using ICD-10 codes.</p><p><strong>Methods: </strong>Clinicians manually annotated 400 discharge summaries, comprising 65,706 sentences, into four categories: \\\"no bleeding,\\\" \\\"clinically significant bleeding,\\\" \\\"severe bleeding,\\\" and \\\"history of bleeding.\\\" The dataset was divided into a training set (70%, 47,100 sentences) and a test set (30%, 18,606 sentences). Two detection approaches were developed and evaluated: (1) an NLP model using binary logistic regression and support vector machine classifiers, and (2) a traditional rule-based algorithm relying exclusively on predefined ICD-10 codes. To address class imbalance, with most sentences categorized as irrelevant (\\\"no bleeding\\\"), a class-weighting strategy was applied in the NLP model. Model performance was assessed using accuracy, precision, recall, F1-score, and receiver operating characteristic (ROC) curve analyses, with manual annotations as the gold standard.</p><p><strong>Results: </strong>The NLP model significantly outperformed the rule-based approach across all evaluation metrics. At the document level, the NLP model achieved macro-average scores of 0.81 for accuracy and 0.80 for F1-score. Precision was particularly high for detecting severe (0.92) and clinically significant bleeding events (0.87), demonstrating strong classification capability despite class imbalance. ROC analyses confirmed the model's robust diagnostic performance, yielding an area under the curve (AUC) of 0.91 when distinguishing irrelevant sentences from potential bleeding events, 0.88 for identifying historical mentions of bleeding, and notably, 0.94 for differentiating clinically significant from severe bleeding. In contrast, the rule-based ICD-10 model demonstrated high precision (0.94) for clinically significant bleeding but poor recall (0.03) for severe bleeding events, reflecting frequent missed detections. This limitation arose due to its reliance on commonly used ICD-10 codes (eg, gastrointestinal hemorrhage) and inadequate capture of rare severe bleeding conditions such as shock due to hemorrhage.</p><p><strong>Conclusions: </strong>This study highlights the considerable advantage of NLP over traditional ICD-10-based methods for detecting bleeding ADEs within electronic medical records. The NLP model effectively captured nuanced clinical narratives, including severity, negations, and historical bleeding events, demonstrating substantial promise for improving patient safety surveillance and clinical decision-making. Future research should extend validation across multiple institutions, diversify annotated datasets, and further refine temporal reasoning capabilities within NLP algorithms.</p>\",\"PeriodicalId\":56334,\"journal\":{\"name\":\"JMIR Medical Informatics\",\"volume\":\"13 \",\"pages\":\"e67837\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2025-08-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12396801/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Medical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.2196/67837\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/67837","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
Natural Language Processing and ICD-10 Coding for Detecting Bleeding Events in Discharge Summaries: Comparative Cross-Sectional Study.
Background: Bleeding adverse drug events (ADEs), particularly among older inpatients receiving antithrombotic therapy, represent a major safety concern in hospitals. These events are often underdetected by conventional rule-based systems relying on structured electronic medical record data, such as the ICD-10 (International Statistical Classification of Diseases and Related Health Problems 10th Revision) codes, which lack the granularity to capture nuanced clinical narratives.
Objective: This study aimed to develop and evaluate a natural language processing (NLP) model to detect and categorize bleeding ADEs in discharge summaries of older adults. Specifically, the model was designed to distinguish between "clinically significant bleeding," "severe bleeding," "history of bleeding," and "no bleeding," and was compared with a rule-based algorithm using ICD-10 codes.
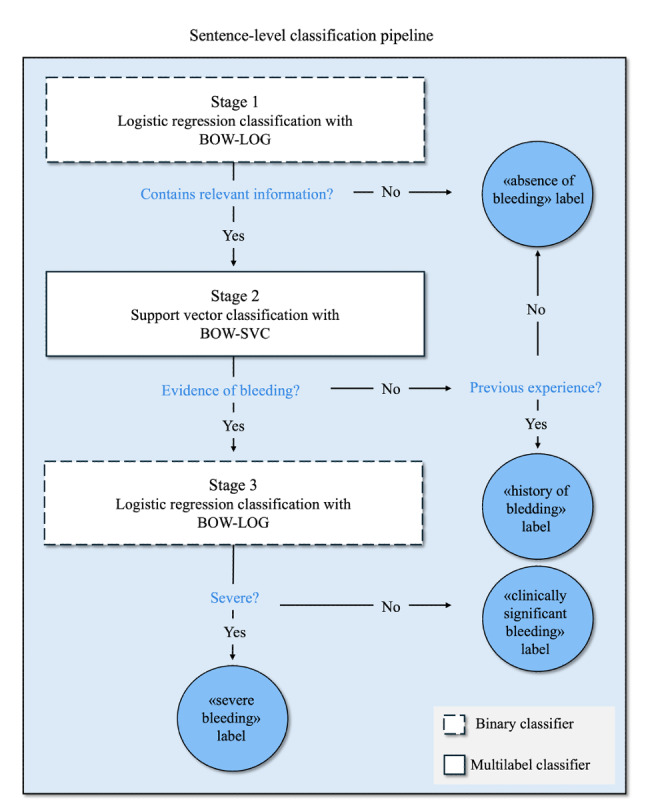
Methods: Clinicians manually annotated 400 discharge summaries, comprising 65,706 sentences, into four categories: "no bleeding," "clinically significant bleeding," "severe bleeding," and "history of bleeding." The dataset was divided into a training set (70%, 47,100 sentences) and a test set (30%, 18,606 sentences). Two detection approaches were developed and evaluated: (1) an NLP model using binary logistic regression and support vector machine classifiers, and (2) a traditional rule-based algorithm relying exclusively on predefined ICD-10 codes. To address class imbalance, with most sentences categorized as irrelevant ("no bleeding"), a class-weighting strategy was applied in the NLP model. Model performance was assessed using accuracy, precision, recall, F1-score, and receiver operating characteristic (ROC) curve analyses, with manual annotations as the gold standard.
Results: The NLP model significantly outperformed the rule-based approach across all evaluation metrics. At the document level, the NLP model achieved macro-average scores of 0.81 for accuracy and 0.80 for F1-score. Precision was particularly high for detecting severe (0.92) and clinically significant bleeding events (0.87), demonstrating strong classification capability despite class imbalance. ROC analyses confirmed the model's robust diagnostic performance, yielding an area under the curve (AUC) of 0.91 when distinguishing irrelevant sentences from potential bleeding events, 0.88 for identifying historical mentions of bleeding, and notably, 0.94 for differentiating clinically significant from severe bleeding. In contrast, the rule-based ICD-10 model demonstrated high precision (0.94) for clinically significant bleeding but poor recall (0.03) for severe bleeding events, reflecting frequent missed detections. This limitation arose due to its reliance on commonly used ICD-10 codes (eg, gastrointestinal hemorrhage) and inadequate capture of rare severe bleeding conditions such as shock due to hemorrhage.
Conclusions: This study highlights the considerable advantage of NLP over traditional ICD-10-based methods for detecting bleeding ADEs within electronic medical records. The NLP model effectively captured nuanced clinical narratives, including severity, negations, and historical bleeding events, demonstrating substantial promise for improving patient safety surveillance and clinical decision-making. Future research should extend validation across multiple institutions, diversify annotated datasets, and further refine temporal reasoning capabilities within NLP algorithms.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


