{"title":"日文胸部计算机断层扫描报告大型数据集的开发和高性能发现分类模型:数据集开发和验证研究。","authors":"Yosuke Yamagishi, Yuta Nakamura, Tomohiro Kikuchi, Yuki Sonoda, Hiroshi Hirakawa, Shintaro Kano, Satoshi Nakamura, Shouhei Hanaoka, Takeharu Yoshikawa, Osamu Abe","doi":"10.2196/71137","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Recent advances in large language models have highlighted the need for high-quality multilingual medical datasets. Although Japan is a global leader in computed tomography (CT) scanner deployment and use, the absence of large-scale Japanese radiology datasets has hindered the development of specialized language models for medical imaging analysis. Despite the emergence of multilingual models and language-specific adaptations, the development of Japanese-specific medical language models has been constrained by a lack of comprehensive datasets, particularly in radiology.</p><p><strong>Objective: </strong>This study aims to address this critical gap in Japanese medical natural language processing resources, for which a comprehensive Japanese CT report dataset was developed through machine translation, to establish a specialized language model for structured classification. In addition, a rigorously validated evaluation dataset was created through expert radiologist refinement to ensure a reliable assessment of model performance.</p><p><strong>Methods: </strong>We translated the CT-RATE dataset (24,283 CT reports from 21,304 patients) into Japanese using GPT-4o mini. The training dataset consisted of 22,778 machine-translated reports, and the validation dataset included 150 reports carefully revised by radiologists. We developed CT-BERT-JPN, a specialized Bidirectional Encoder Representations from Transformers (BERT) model for Japanese radiology text, based on the \"tohoku-nlp/bert-base-japanese-v3\" architecture, to extract 18 structured findings from reports. Translation quality was assessed with Bilingual Evaluation Understudy (BLEU) and Recall-Oriented Understudy for Gisting Evaluation (ROUGE) scores and further evaluated by radiologists in a dedicated human-in-the-loop experiment. In that experiment, each of a randomly selected subset of reports was independently reviewed by 2 radiologists-1 senior (postgraduate year [PGY] 6-11) and 1 junior (PGY 4-5)-using a 5-point Likert scale to rate: (1) grammatical correctness, (2) medical terminology accuracy, and (3) overall readability. Inter-rater reliability was measured via quadratic weighted kappa (QWK). Model performance was benchmarked against GPT-4o using accuracy, precision, recall, F1-score, ROC (receiver operating characteristic)-AUC (area under the curve), and average precision.</p><p><strong>Results: </strong>General text structure was preserved (BLEU: 0.731 findings, 0.690 impression; ROUGE: 0.770-0.876 findings, 0.748-0.857 impression), though expert review identified 3 categories of necessary refinements-contextual adjustment of technical terms, completion of incomplete translations, and localization of Japanese medical terminology. The radiologist-revised translations scored significantly higher than raw machine translations across all dimensions, and all improvements were statistically significant (P<.001). CT-BERT-JPN outperformed GPT-4o on 11 of 18 findings (61%), achieving perfect F1-scores for 4 conditions and F1-score >0.95 for 14 conditions, despite varied sample sizes (7-82 cases).</p><p><strong>Conclusions: </strong>Our study established a robust Japanese CT report dataset and demonstrated the effectiveness of a specialized language model in structured classification of findings. This hybrid approach of machine translation and expert validation enabled the creation of large-scale datasets while maintaining high-quality standards. This study provides essential resources for advancing medical artificial intelligence research in Japanese health care settings, using datasets and models publicly available for research to facilitate further advancement in the field.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e71137"},"PeriodicalIF":3.8000,"publicationDate":"2025-08-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12392688/pdf/","citationCount":"0","resultStr":"{\"title\":\"Development of a Large-Scale Dataset of Chest Computed Tomography Reports in Japanese and a High-Performance Finding Classification Model: Dataset Development and Validation Study.\",\"authors\":\"Yosuke Yamagishi, Yuta Nakamura, Tomohiro Kikuchi, Yuki Sonoda, Hiroshi Hirakawa, Shintaro Kano, Satoshi Nakamura, Shouhei Hanaoka, Takeharu Yoshikawa, Osamu Abe\",\"doi\":\"10.2196/71137\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Recent advances in large language models have highlighted the need for high-quality multilingual medical datasets. Although Japan is a global leader in computed tomography (CT) scanner deployment and use, the absence of large-scale Japanese radiology datasets has hindered the development of specialized language models for medical imaging analysis. Despite the emergence of multilingual models and language-specific adaptations, the development of Japanese-specific medical language models has been constrained by a lack of comprehensive datasets, particularly in radiology.</p><p><strong>Objective: </strong>This study aims to address this critical gap in Japanese medical natural language processing resources, for which a comprehensive Japanese CT report dataset was developed through machine translation, to establish a specialized language model for structured classification. In addition, a rigorously validated evaluation dataset was created through expert radiologist refinement to ensure a reliable assessment of model performance.</p><p><strong>Methods: </strong>We translated the CT-RATE dataset (24,283 CT reports from 21,304 patients) into Japanese using GPT-4o mini. The training dataset consisted of 22,778 machine-translated reports, and the validation dataset included 150 reports carefully revised by radiologists. We developed CT-BERT-JPN, a specialized Bidirectional Encoder Representations from Transformers (BERT) model for Japanese radiology text, based on the \\\"tohoku-nlp/bert-base-japanese-v3\\\" architecture, to extract 18 structured findings from reports. Translation quality was assessed with Bilingual Evaluation Understudy (BLEU) and Recall-Oriented Understudy for Gisting Evaluation (ROUGE) scores and further evaluated by radiologists in a dedicated human-in-the-loop experiment. In that experiment, each of a randomly selected subset of reports was independently reviewed by 2 radiologists-1 senior (postgraduate year [PGY] 6-11) and 1 junior (PGY 4-5)-using a 5-point Likert scale to rate: (1) grammatical correctness, (2) medical terminology accuracy, and (3) overall readability. Inter-rater reliability was measured via quadratic weighted kappa (QWK). Model performance was benchmarked against GPT-4o using accuracy, precision, recall, F1-score, ROC (receiver operating characteristic)-AUC (area under the curve), and average precision.</p><p><strong>Results: </strong>General text structure was preserved (BLEU: 0.731 findings, 0.690 impression; ROUGE: 0.770-0.876 findings, 0.748-0.857 impression), though expert review identified 3 categories of necessary refinements-contextual adjustment of technical terms, completion of incomplete translations, and localization of Japanese medical terminology. The radiologist-revised translations scored significantly higher than raw machine translations across all dimensions, and all improvements were statistically significant (P<.001). CT-BERT-JPN outperformed GPT-4o on 11 of 18 findings (61%), achieving perfect F1-scores for 4 conditions and F1-score >0.95 for 14 conditions, despite varied sample sizes (7-82 cases).</p><p><strong>Conclusions: </strong>Our study established a robust Japanese CT report dataset and demonstrated the effectiveness of a specialized language model in structured classification of findings. This hybrid approach of machine translation and expert validation enabled the creation of large-scale datasets while maintaining high-quality standards. This study provides essential resources for advancing medical artificial intelligence research in Japanese health care settings, using datasets and models publicly available for research to facilitate further advancement in the field.</p>\",\"PeriodicalId\":56334,\"journal\":{\"name\":\"JMIR Medical Informatics\",\"volume\":\"13 \",\"pages\":\"e71137\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2025-08-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12392688/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Medical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.2196/71137\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/71137","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
Development of a Large-Scale Dataset of Chest Computed Tomography Reports in Japanese and a High-Performance Finding Classification Model: Dataset Development and Validation Study.
Background: Recent advances in large language models have highlighted the need for high-quality multilingual medical datasets. Although Japan is a global leader in computed tomography (CT) scanner deployment and use, the absence of large-scale Japanese radiology datasets has hindered the development of specialized language models for medical imaging analysis. Despite the emergence of multilingual models and language-specific adaptations, the development of Japanese-specific medical language models has been constrained by a lack of comprehensive datasets, particularly in radiology.
Objective: This study aims to address this critical gap in Japanese medical natural language processing resources, for which a comprehensive Japanese CT report dataset was developed through machine translation, to establish a specialized language model for structured classification. In addition, a rigorously validated evaluation dataset was created through expert radiologist refinement to ensure a reliable assessment of model performance.
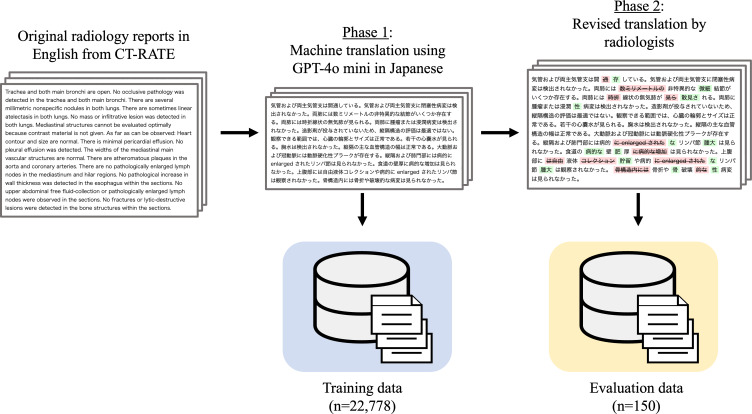
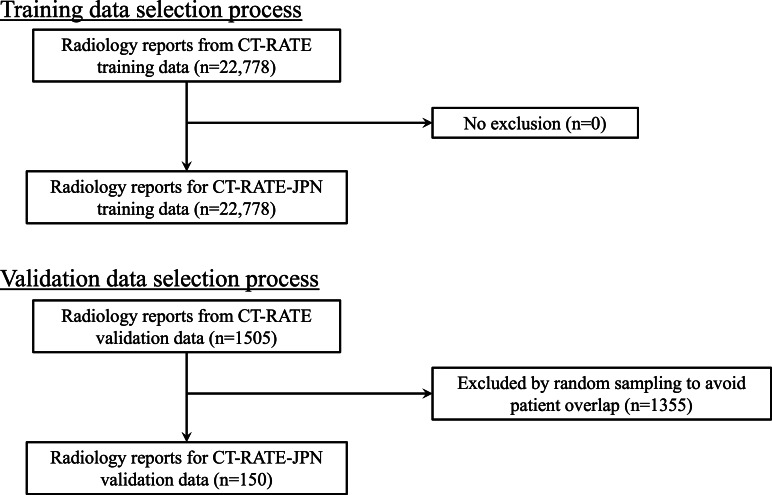
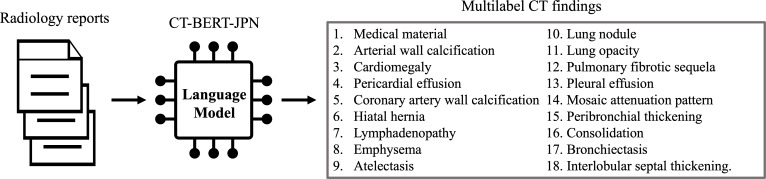
Methods: We translated the CT-RATE dataset (24,283 CT reports from 21,304 patients) into Japanese using GPT-4o mini. The training dataset consisted of 22,778 machine-translated reports, and the validation dataset included 150 reports carefully revised by radiologists. We developed CT-BERT-JPN, a specialized Bidirectional Encoder Representations from Transformers (BERT) model for Japanese radiology text, based on the "tohoku-nlp/bert-base-japanese-v3" architecture, to extract 18 structured findings from reports. Translation quality was assessed with Bilingual Evaluation Understudy (BLEU) and Recall-Oriented Understudy for Gisting Evaluation (ROUGE) scores and further evaluated by radiologists in a dedicated human-in-the-loop experiment. In that experiment, each of a randomly selected subset of reports was independently reviewed by 2 radiologists-1 senior (postgraduate year [PGY] 6-11) and 1 junior (PGY 4-5)-using a 5-point Likert scale to rate: (1) grammatical correctness, (2) medical terminology accuracy, and (3) overall readability. Inter-rater reliability was measured via quadratic weighted kappa (QWK). Model performance was benchmarked against GPT-4o using accuracy, precision, recall, F1-score, ROC (receiver operating characteristic)-AUC (area under the curve), and average precision.
Results: General text structure was preserved (BLEU: 0.731 findings, 0.690 impression; ROUGE: 0.770-0.876 findings, 0.748-0.857 impression), though expert review identified 3 categories of necessary refinements-contextual adjustment of technical terms, completion of incomplete translations, and localization of Japanese medical terminology. The radiologist-revised translations scored significantly higher than raw machine translations across all dimensions, and all improvements were statistically significant (P<.001). CT-BERT-JPN outperformed GPT-4o on 11 of 18 findings (61%), achieving perfect F1-scores for 4 conditions and F1-score >0.95 for 14 conditions, despite varied sample sizes (7-82 cases).
Conclusions: Our study established a robust Japanese CT report dataset and demonstrated the effectiveness of a specialized language model in structured classification of findings. This hybrid approach of machine translation and expert validation enabled the creation of large-scale datasets while maintaining high-quality standards. This study provides essential resources for advancing medical artificial intelligence research in Japanese health care settings, using datasets and models publicly available for research to facilitate further advancement in the field.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


