Zhixing Chang, Jiawen Shang, Yuhan Fan, Peng Huang, Zhihui Hu, Ke Zhang, Jianrong Dai, Hui Yan
{"title":"基于深度学习的放射治疗投影图像压缩超分辨率方法。","authors":"Zhixing Chang, Jiawen Shang, Yuhan Fan, Peng Huang, Zhihui Hu, Ke Zhang, Jianrong Dai, Hui Yan","doi":"10.21037/qims-2024-2962","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Cone-beam computed tomography (CBCT) is a three-dimensional (3D) imaging method designed for routine target verification of cancer patients during radiotherapy. The images are reconstructed from a sequence of projection images obtained by the on-board imager attached to a radiotherapy machine. CBCT images are usually stored in a health information system, but the projection images are mostly abandoned due to their massive volume. To store them economically, in this study, a deep learning (DL)-based super-resolution (SR) method for compressing the projection images was investigated.</p><p><strong>Methods: </strong>In image compression, low-resolution (LR) images were down-sampled by a factor from the high-resolution (HR) projection images and then encoded to the video file. In image restoration, LR images were decoded from the video file and then up-sampled to HR projection images via the DL network. Three SR DL networks, convolutional neural network (CNN), residual network (ResNet), and generative adversarial network (GAN), were tested along with three video coding-decoding (CODEC) algorithms: Advanced Video Coding (AVC), High Efficiency Video Coding (HEVC), and AOMedia Video 1 (AV1). Based on the two databases of the natural and projection images, the performance of the SR networks and video codecs was evaluated with the compression ratio (CR), peak signal-to-noise ratio (PSNR), video quality metric (VQM), and structural similarity index measure (SSIM).</p><p><strong>Results: </strong>The codec AV1 achieved the highest CR among the three codecs. The CRs of AV1 were 13.91, 42.08, 144.32, and 289.80 for the down-sampling factor (DSF) 0 (non-SR) 2, 4, and 6, respectively. The SR network, ResNet, achieved the best restoration accuracy among the three SR networks. Its PSNRs were 69.08, 41.60, 37.08, and 32.44 dB for the four DSFs, respectively; its VQMs were 0.06%, 3.65%, 6.95%, and 13.03% for the four DSFs, respectively; and its SSIMs were 0.9984, 0.9878, 0.9798, and 0.9518 for the four DSFs, respectively. As the DSF increased, the CR increased proportionally with the modest degradation of the restored images.</p><p><strong>Conclusions: </strong>The application of the SR model can further improve the CR based on the current result achieved by the video encoders. This compression method is not only effective for the two-dimensional (2D) projection images, but also applicable to the 3D images used in radiotherapy.</p>","PeriodicalId":54267,"journal":{"name":"Quantitative Imaging in Medicine and Surgery","volume":"15 9","pages":"8611-8626"},"PeriodicalIF":2.3000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12397698/pdf/","citationCount":"0","resultStr":"{\"title\":\"Deep learning-based super-resolution method for projection image compression in radiotherapy.\",\"authors\":\"Zhixing Chang, Jiawen Shang, Yuhan Fan, Peng Huang, Zhihui Hu, Ke Zhang, Jianrong Dai, Hui Yan\",\"doi\":\"10.21037/qims-2024-2962\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Cone-beam computed tomography (CBCT) is a three-dimensional (3D) imaging method designed for routine target verification of cancer patients during radiotherapy. The images are reconstructed from a sequence of projection images obtained by the on-board imager attached to a radiotherapy machine. CBCT images are usually stored in a health information system, but the projection images are mostly abandoned due to their massive volume. To store them economically, in this study, a deep learning (DL)-based super-resolution (SR) method for compressing the projection images was investigated.</p><p><strong>Methods: </strong>In image compression, low-resolution (LR) images were down-sampled by a factor from the high-resolution (HR) projection images and then encoded to the video file. In image restoration, LR images were decoded from the video file and then up-sampled to HR projection images via the DL network. Three SR DL networks, convolutional neural network (CNN), residual network (ResNet), and generative adversarial network (GAN), were tested along with three video coding-decoding (CODEC) algorithms: Advanced Video Coding (AVC), High Efficiency Video Coding (HEVC), and AOMedia Video 1 (AV1). Based on the two databases of the natural and projection images, the performance of the SR networks and video codecs was evaluated with the compression ratio (CR), peak signal-to-noise ratio (PSNR), video quality metric (VQM), and structural similarity index measure (SSIM).</p><p><strong>Results: </strong>The codec AV1 achieved the highest CR among the three codecs. The CRs of AV1 were 13.91, 42.08, 144.32, and 289.80 for the down-sampling factor (DSF) 0 (non-SR) 2, 4, and 6, respectively. The SR network, ResNet, achieved the best restoration accuracy among the three SR networks. Its PSNRs were 69.08, 41.60, 37.08, and 32.44 dB for the four DSFs, respectively; its VQMs were 0.06%, 3.65%, 6.95%, and 13.03% for the four DSFs, respectively; and its SSIMs were 0.9984, 0.9878, 0.9798, and 0.9518 for the four DSFs, respectively. As the DSF increased, the CR increased proportionally with the modest degradation of the restored images.</p><p><strong>Conclusions: </strong>The application of the SR model can further improve the CR based on the current result achieved by the video encoders. This compression method is not only effective for the two-dimensional (2D) projection images, but also applicable to the 3D images used in radiotherapy.</p>\",\"PeriodicalId\":54267,\"journal\":{\"name\":\"Quantitative Imaging in Medicine and Surgery\",\"volume\":\"15 9\",\"pages\":\"8611-8626\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2025-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12397698/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Quantitative Imaging in Medicine and Surgery\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.21037/qims-2024-2962\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/8/13 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Quantitative Imaging in Medicine and Surgery","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.21037/qims-2024-2962","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/8/13 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
引用次数: 0
摘要
背景:锥束计算机断层扫描(CBCT)是一种三维(3D)成像方法,用于癌症患者放疗期间的常规靶标验证。这些图像是由附着在放射治疗机上的机载成像仪获得的一系列投影图像重建而成的。CBCT图像通常存储在卫生信息系统中,但投影图像由于体积庞大而大多被放弃。为了经济地存储投影图像,本文研究了一种基于深度学习(DL)的超分辨率(SR)压缩投影图像的方法。方法:在图像压缩中,将低分辨率(LR)图像从高分辨率(HR)投影图像中降采样,然后编码到视频文件中。在图像恢复中,从视频文件中解码LR图像,然后通过DL网络上采样到HR投影图像。三种SR深度学习网络,卷积神经网络(CNN),残差网络(ResNet)和生成对抗网络(GAN),以及三种视频编解码(CODEC)算法:高级视频编码(AVC),高效视频编码(HEVC)和amedia video 1 (AV1)。基于自然图像和投影图像两个数据库,用压缩比(CR)、峰值信噪比(PSNR)、视频质量度量(VQM)和结构相似指数度量(SSIM)对SR网络和视频编解码器的性能进行了评价。结果:AV1编解码器在三种编解码器中CR最高。当降采样因子(DSF)为0(非sr) 2、4和6时,AV1的CRs分别为13.91、42.08、144.32和289.80。SR网络ResNet在3种SR网络中恢复精度最好。4个DSFs的psnr分别为69.08、41.60、37.08和32.44 dB;4种DSFs的VQMs分别为0.06%、3.65%、6.95%和13.03%;4种dsf的ssim分别为0.9984、0.9878、0.9798和0.9518。随着DSF的增加,CR随恢复图像的适度退化而成比例地增加。结论:应用SR模型可以在现有视频编码器的基础上进一步提高CR。这种压缩方法不仅对二维(2D)投影图像有效,也适用于放疗中使用的三维图像。
Deep learning-based super-resolution method for projection image compression in radiotherapy.
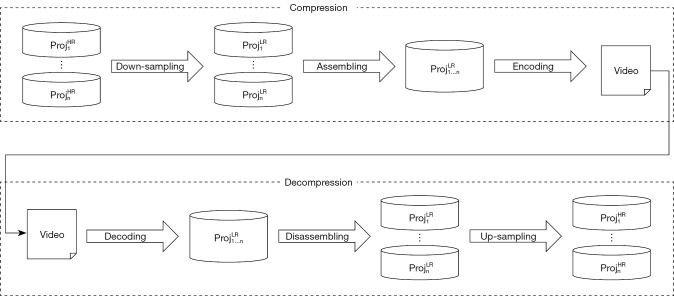
Background: Cone-beam computed tomography (CBCT) is a three-dimensional (3D) imaging method designed for routine target verification of cancer patients during radiotherapy. The images are reconstructed from a sequence of projection images obtained by the on-board imager attached to a radiotherapy machine. CBCT images are usually stored in a health information system, but the projection images are mostly abandoned due to their massive volume. To store them economically, in this study, a deep learning (DL)-based super-resolution (SR) method for compressing the projection images was investigated.
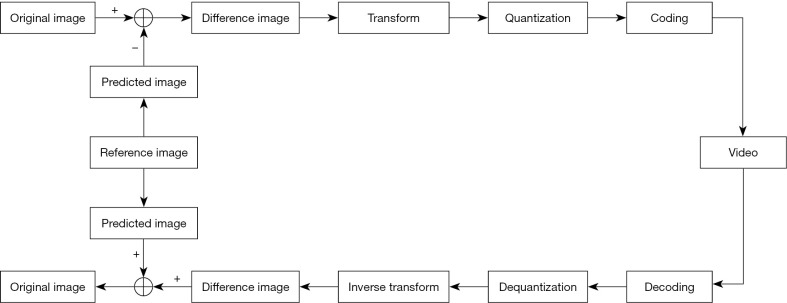
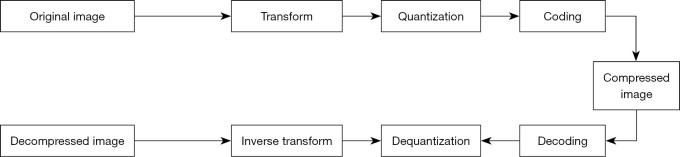
Methods: In image compression, low-resolution (LR) images were down-sampled by a factor from the high-resolution (HR) projection images and then encoded to the video file. In image restoration, LR images were decoded from the video file and then up-sampled to HR projection images via the DL network. Three SR DL networks, convolutional neural network (CNN), residual network (ResNet), and generative adversarial network (GAN), were tested along with three video coding-decoding (CODEC) algorithms: Advanced Video Coding (AVC), High Efficiency Video Coding (HEVC), and AOMedia Video 1 (AV1). Based on the two databases of the natural and projection images, the performance of the SR networks and video codecs was evaluated with the compression ratio (CR), peak signal-to-noise ratio (PSNR), video quality metric (VQM), and structural similarity index measure (SSIM).
Results: The codec AV1 achieved the highest CR among the three codecs. The CRs of AV1 were 13.91, 42.08, 144.32, and 289.80 for the down-sampling factor (DSF) 0 (non-SR) 2, 4, and 6, respectively. The SR network, ResNet, achieved the best restoration accuracy among the three SR networks. Its PSNRs were 69.08, 41.60, 37.08, and 32.44 dB for the four DSFs, respectively; its VQMs were 0.06%, 3.65%, 6.95%, and 13.03% for the four DSFs, respectively; and its SSIMs were 0.9984, 0.9878, 0.9798, and 0.9518 for the four DSFs, respectively. As the DSF increased, the CR increased proportionally with the modest degradation of the restored images.
Conclusions: The application of the SR model can further improve the CR based on the current result achieved by the video encoders. This compression method is not only effective for the two-dimensional (2D) projection images, but also applicable to the 3D images used in radiotherapy.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


