{"title":"基于kde的合成采样改进不平衡基因组数据分类。","authors":"Edoardo Taccaliti, Jesus S Aguilar-Ruiz","doi":"10.1186/s13040-025-00474-5","DOIUrl":null,"url":null,"abstract":"<p><p>Class imbalance poses a serious challenge in biomedical machine learning, particularly in genomics, where datasets are characterized by extremely high dimensionality and very limited sample sizes. In such settings, standard classifiers tend to favor the majority class, leading to biased predictions - an especially problematic issue in clinical diagnostics where rare conditions must not be overlooked. In this study, we introduce a Kernel Density Estimation (KDE)-based oversampling approach to rebalance imbalanced genomic datasets by generating synthetic minority class samples. Unlike conventional methods such as SMOTE, KDE estimates the global probability distribution of the minority class and resamples accordingly, avoiding local interpolation pitfalls. We evaluate our method on 15 real-world genomic datasets using three classifiers -Naïve Bayes, Decision Trees, and Random Forests- and compare it to SMOTE and baseline training. Experimental results demonstrate that KDE oversampling consistently improves classification performance, especially in metrics robust to imbalance, such as AUC of the IMCP curve. Notably, KDE achieves superior results in tree-based models while dramatically simplifying the sampling process. This approach offers a statistically grounded and effective solution for balancing genomic datasets, with strong potential for improving fairness and accuracy in high-stakes medical decision-making.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"18 1","pages":"60"},"PeriodicalIF":6.1000,"publicationDate":"2025-08-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12395650/pdf/","citationCount":"0","resultStr":"{\"title\":\"Improving classification on imbalanced genomic data via KDE-based synthetic sampling.\",\"authors\":\"Edoardo Taccaliti, Jesus S Aguilar-Ruiz\",\"doi\":\"10.1186/s13040-025-00474-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Class imbalance poses a serious challenge in biomedical machine learning, particularly in genomics, where datasets are characterized by extremely high dimensionality and very limited sample sizes. In such settings, standard classifiers tend to favor the majority class, leading to biased predictions - an especially problematic issue in clinical diagnostics where rare conditions must not be overlooked. In this study, we introduce a Kernel Density Estimation (KDE)-based oversampling approach to rebalance imbalanced genomic datasets by generating synthetic minority class samples. Unlike conventional methods such as SMOTE, KDE estimates the global probability distribution of the minority class and resamples accordingly, avoiding local interpolation pitfalls. We evaluate our method on 15 real-world genomic datasets using three classifiers -Naïve Bayes, Decision Trees, and Random Forests- and compare it to SMOTE and baseline training. Experimental results demonstrate that KDE oversampling consistently improves classification performance, especially in metrics robust to imbalance, such as AUC of the IMCP curve. Notably, KDE achieves superior results in tree-based models while dramatically simplifying the sampling process. This approach offers a statistically grounded and effective solution for balancing genomic datasets, with strong potential for improving fairness and accuracy in high-stakes medical decision-making.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"18 1\",\"pages\":\"60\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2025-08-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12395650/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-025-00474-5\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-025-00474-5","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Improving classification on imbalanced genomic data via KDE-based synthetic sampling.
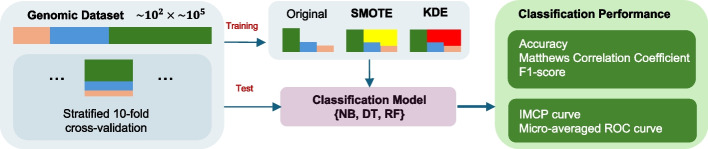
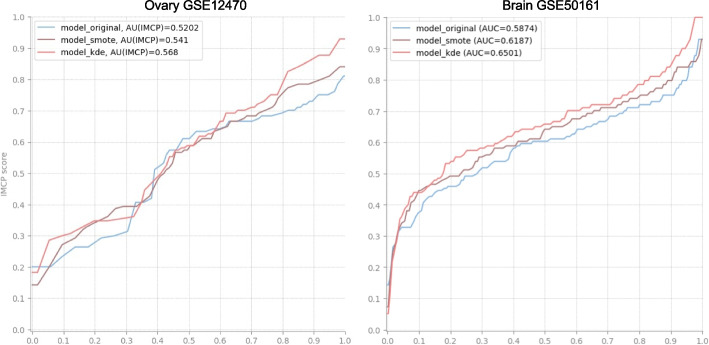
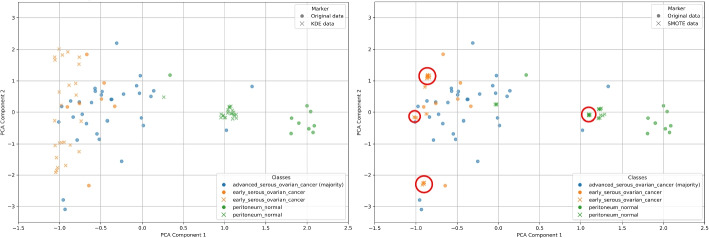
Class imbalance poses a serious challenge in biomedical machine learning, particularly in genomics, where datasets are characterized by extremely high dimensionality and very limited sample sizes. In such settings, standard classifiers tend to favor the majority class, leading to biased predictions - an especially problematic issue in clinical diagnostics where rare conditions must not be overlooked. In this study, we introduce a Kernel Density Estimation (KDE)-based oversampling approach to rebalance imbalanced genomic datasets by generating synthetic minority class samples. Unlike conventional methods such as SMOTE, KDE estimates the global probability distribution of the minority class and resamples accordingly, avoiding local interpolation pitfalls. We evaluate our method on 15 real-world genomic datasets using three classifiers -Naïve Bayes, Decision Trees, and Random Forests- and compare it to SMOTE and baseline training. Experimental results demonstrate that KDE oversampling consistently improves classification performance, especially in metrics robust to imbalance, such as AUC of the IMCP curve. Notably, KDE achieves superior results in tree-based models while dramatically simplifying the sampling process. This approach offers a statistically grounded and effective solution for balancing genomic datasets, with strong potential for improving fairness and accuracy in high-stakes medical decision-making.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


