Fatmah Y Assiri, Mohammad D Alahmadi, Mohammed A Almuashi, Ayidh M Almansour
{"title":"使用大型语言模型从双语食品标签中提取营养信息。","authors":"Fatmah Y Assiri, Mohammad D Alahmadi, Mohammed A Almuashi, Ayidh M Almansour","doi":"10.3390/jimaging11080271","DOIUrl":null,"url":null,"abstract":"<p><p>Food product labels serve as a critical source of information, providing details about nutritional content, ingredients, and health implications. These labels enable Food and Drug Authorities (FDA) to ensure compliance and take necessary health-related and logistics actions. Additionally, product labels are essential for online grocery stores to offer reliable nutrition facts and empower customers to make informed dietary decisions. Unfortunately, product labels are typically available in image formats, requiring organizations and online stores to manually transcribe them-a process that is not only time-consuming but also highly prone to human error, especially with multilingual labels that add complexity to the task. Our study investigates the challenges and effectiveness of leveraging large language models (LLMs) to extract nutritional elements and values from multilingual food product labels, with a specific focus on Arabic and English. A comprehensive empirical analysis was conducted using a manually curated dataset of 294 food product labels, comprising 588 transcribed nutritional elements and values in both languages, which served as the ground truth for evaluation. The findings reveal that while LLMs performed better in extracting English elements and values compared to Arabic, our post-processing techniques significantly enhanced their accuracy, with GPT-4o outperforming GPT-4V and Gemini.</p>","PeriodicalId":37035,"journal":{"name":"Journal of Imaging","volume":"11 8","pages":""},"PeriodicalIF":2.7000,"publicationDate":"2025-08-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12387780/pdf/","citationCount":"0","resultStr":"{\"title\":\"Extract Nutritional Information from Bilingual Food Labels Using Large Language Models.\",\"authors\":\"Fatmah Y Assiri, Mohammad D Alahmadi, Mohammed A Almuashi, Ayidh M Almansour\",\"doi\":\"10.3390/jimaging11080271\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Food product labels serve as a critical source of information, providing details about nutritional content, ingredients, and health implications. These labels enable Food and Drug Authorities (FDA) to ensure compliance and take necessary health-related and logistics actions. Additionally, product labels are essential for online grocery stores to offer reliable nutrition facts and empower customers to make informed dietary decisions. Unfortunately, product labels are typically available in image formats, requiring organizations and online stores to manually transcribe them-a process that is not only time-consuming but also highly prone to human error, especially with multilingual labels that add complexity to the task. Our study investigates the challenges and effectiveness of leveraging large language models (LLMs) to extract nutritional elements and values from multilingual food product labels, with a specific focus on Arabic and English. A comprehensive empirical analysis was conducted using a manually curated dataset of 294 food product labels, comprising 588 transcribed nutritional elements and values in both languages, which served as the ground truth for evaluation. The findings reveal that while LLMs performed better in extracting English elements and values compared to Arabic, our post-processing techniques significantly enhanced their accuracy, with GPT-4o outperforming GPT-4V and Gemini.</p>\",\"PeriodicalId\":37035,\"journal\":{\"name\":\"Journal of Imaging\",\"volume\":\"11 8\",\"pages\":\"\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2025-08-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12387780/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Imaging\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3390/jimaging11080271\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"IMAGING SCIENCE & PHOTOGRAPHIC TECHNOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Imaging","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/jimaging11080271","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"IMAGING SCIENCE & PHOTOGRAPHIC TECHNOLOGY","Score":null,"Total":0}
Extract Nutritional Information from Bilingual Food Labels Using Large Language Models.
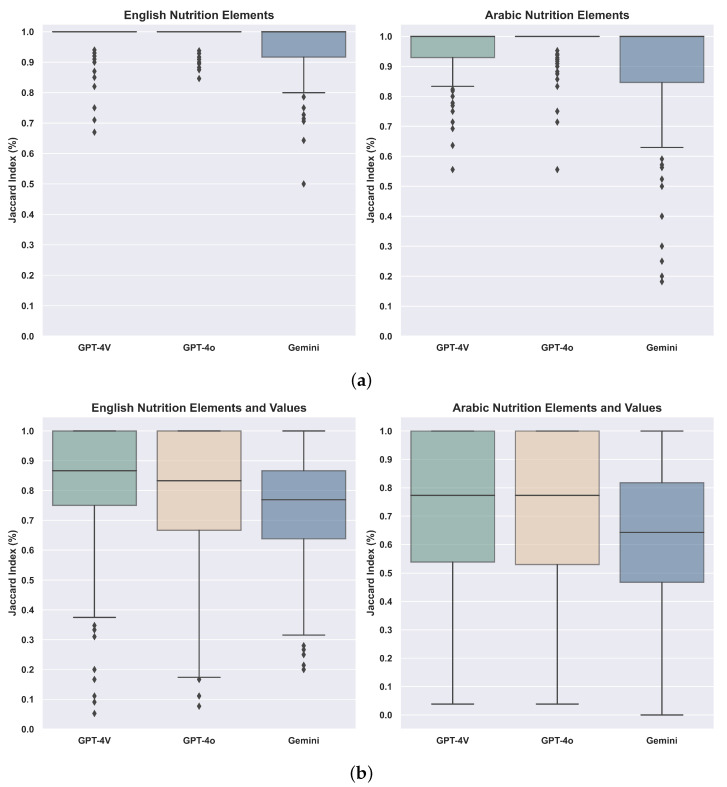
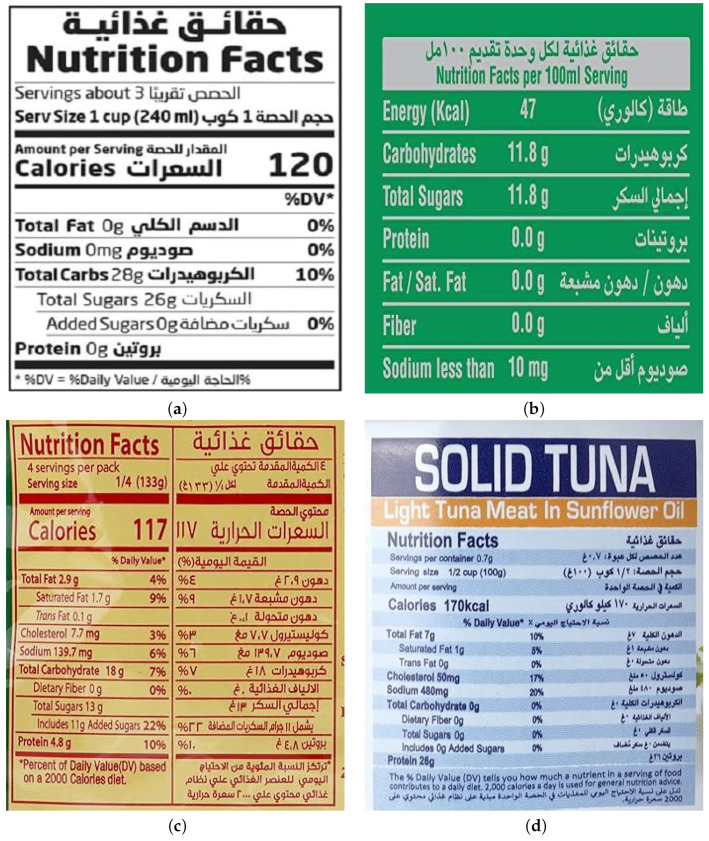
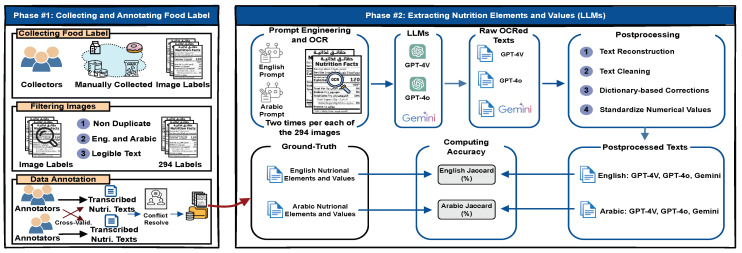
Food product labels serve as a critical source of information, providing details about nutritional content, ingredients, and health implications. These labels enable Food and Drug Authorities (FDA) to ensure compliance and take necessary health-related and logistics actions. Additionally, product labels are essential for online grocery stores to offer reliable nutrition facts and empower customers to make informed dietary decisions. Unfortunately, product labels are typically available in image formats, requiring organizations and online stores to manually transcribe them-a process that is not only time-consuming but also highly prone to human error, especially with multilingual labels that add complexity to the task. Our study investigates the challenges and effectiveness of leveraging large language models (LLMs) to extract nutritional elements and values from multilingual food product labels, with a specific focus on Arabic and English. A comprehensive empirical analysis was conducted using a manually curated dataset of 294 food product labels, comprising 588 transcribed nutritional elements and values in both languages, which served as the ground truth for evaluation. The findings reveal that while LLMs performed better in extracting English elements and values compared to Arabic, our post-processing techniques significantly enhanced their accuracy, with GPT-4o outperforming GPT-4V and Gemini.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


