{"title":"ChatGPT-4 Omni和Gemini 1.5 Pro在土耳其医学专业考试中眼科相关问题的表现","authors":"Mehmet Cem Sabaner, Zübeyir Yozgat","doi":"10.4274/tjo.galenos.2025.27895","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>To evaluate the response and interpretative capabilities of two pioneering artificial intelligence (AI)-based large language model (LLM) platforms in addressing ophthalmology-related multiple-choice questions (MCQs) from Turkish Medical Specialty Exams.</p><p><strong>Materials and methods: </strong>MCQs from a total of 37 exams held between 2006-2024 were reviewed. Ophthalmology-related questions were identified and categorized into sections. The selected questions were asked to the ChatGPT-4o and Gemini 1.5 Pro AI-based LLM chatbots in both Turkish and English with specific prompts, then re-asked without any interaction. In the final step, feedback for incorrect responses were generated and all questions were posed a third time.</p><p><strong>Results: </strong>A total of 220 ophthalmology-related questions out of 7312 MCQs were evaluated using both AI-based LLMs. A mean of 6.47±2.91 (range: 2-13) MCQs was taken from each of the 33 parts (32 full exams and the pooled 10% of exams shared between 2022 and 2024). After the final step, ChatGPT-4o achieved higher accuracy in both Turkish (97.3%) and English (97.7%) compared to Gemini 1.5 Pro (94.1% and 93.2%, respectively), with a statistically significant difference in English (p=0.039) but not in Turkish (p=0.159). There was no statistically significant difference in either the inter-AI comparison of sections or interlingual comparison.</p><p><strong>Conclusion: </strong>While both AI platforms demonstrated robust performance in addressing ophthalmology-related MCQs, ChatGPT-4o was slightly superior. These models have the potential to enhance ophthalmological medical education, not only by accurately selecting the answers to MCQs but also by providing detailed explanations.</p>","PeriodicalId":23373,"journal":{"name":"Turkish Journal of Ophthalmology","volume":"55 4","pages":"177-185"},"PeriodicalIF":0.0000,"publicationDate":"2025-08-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12372544/pdf/","citationCount":"0","resultStr":"{\"title\":\"Performance of ChatGPT-4 Omni and Gemini 1.5 Pro on Ophthalmology-Related Questions in the Turkish Medical Specialty Exam.\",\"authors\":\"Mehmet Cem Sabaner, Zübeyir Yozgat\",\"doi\":\"10.4274/tjo.galenos.2025.27895\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>To evaluate the response and interpretative capabilities of two pioneering artificial intelligence (AI)-based large language model (LLM) platforms in addressing ophthalmology-related multiple-choice questions (MCQs) from Turkish Medical Specialty Exams.</p><p><strong>Materials and methods: </strong>MCQs from a total of 37 exams held between 2006-2024 were reviewed. Ophthalmology-related questions were identified and categorized into sections. The selected questions were asked to the ChatGPT-4o and Gemini 1.5 Pro AI-based LLM chatbots in both Turkish and English with specific prompts, then re-asked without any interaction. In the final step, feedback for incorrect responses were generated and all questions were posed a third time.</p><p><strong>Results: </strong>A total of 220 ophthalmology-related questions out of 7312 MCQs were evaluated using both AI-based LLMs. A mean of 6.47±2.91 (range: 2-13) MCQs was taken from each of the 33 parts (32 full exams and the pooled 10% of exams shared between 2022 and 2024). After the final step, ChatGPT-4o achieved higher accuracy in both Turkish (97.3%) and English (97.7%) compared to Gemini 1.5 Pro (94.1% and 93.2%, respectively), with a statistically significant difference in English (p=0.039) but not in Turkish (p=0.159). There was no statistically significant difference in either the inter-AI comparison of sections or interlingual comparison.</p><p><strong>Conclusion: </strong>While both AI platforms demonstrated robust performance in addressing ophthalmology-related MCQs, ChatGPT-4o was slightly superior. These models have the potential to enhance ophthalmological medical education, not only by accurately selecting the answers to MCQs but also by providing detailed explanations.</p>\",\"PeriodicalId\":23373,\"journal\":{\"name\":\"Turkish Journal of Ophthalmology\",\"volume\":\"55 4\",\"pages\":\"177-185\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-08-21\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12372544/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Turkish Journal of Ophthalmology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.4274/tjo.galenos.2025.27895\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"Medicine\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Turkish Journal of Ophthalmology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4274/tjo.galenos.2025.27895","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"Medicine","Score":null,"Total":0}
Performance of ChatGPT-4 Omni and Gemini 1.5 Pro on Ophthalmology-Related Questions in the Turkish Medical Specialty Exam.
Objectives: To evaluate the response and interpretative capabilities of two pioneering artificial intelligence (AI)-based large language model (LLM) platforms in addressing ophthalmology-related multiple-choice questions (MCQs) from Turkish Medical Specialty Exams.
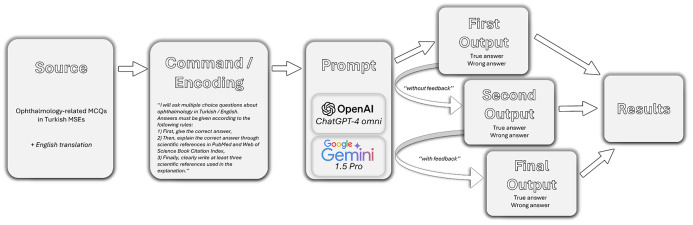
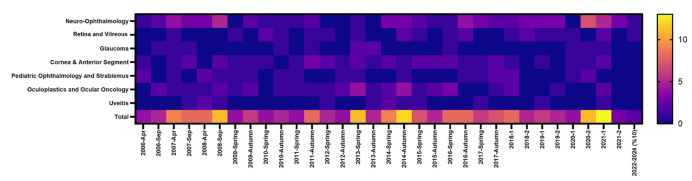
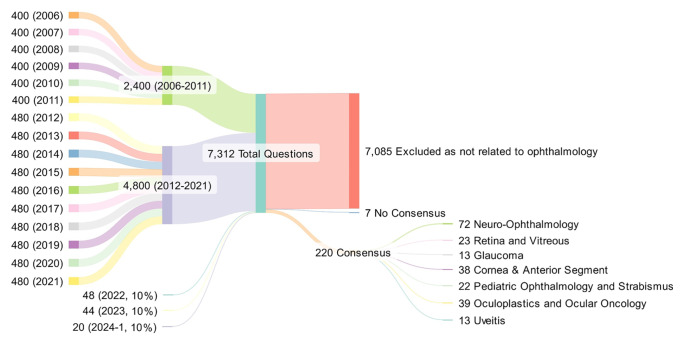
Materials and methods: MCQs from a total of 37 exams held between 2006-2024 were reviewed. Ophthalmology-related questions were identified and categorized into sections. The selected questions were asked to the ChatGPT-4o and Gemini 1.5 Pro AI-based LLM chatbots in both Turkish and English with specific prompts, then re-asked without any interaction. In the final step, feedback for incorrect responses were generated and all questions were posed a third time.
Results: A total of 220 ophthalmology-related questions out of 7312 MCQs were evaluated using both AI-based LLMs. A mean of 6.47±2.91 (range: 2-13) MCQs was taken from each of the 33 parts (32 full exams and the pooled 10% of exams shared between 2022 and 2024). After the final step, ChatGPT-4o achieved higher accuracy in both Turkish (97.3%) and English (97.7%) compared to Gemini 1.5 Pro (94.1% and 93.2%, respectively), with a statistically significant difference in English (p=0.039) but not in Turkish (p=0.159). There was no statistically significant difference in either the inter-AI comparison of sections or interlingual comparison.
Conclusion: While both AI platforms demonstrated robust performance in addressing ophthalmology-related MCQs, ChatGPT-4o was slightly superior. These models have the potential to enhance ophthalmological medical education, not only by accurately selecting the answers to MCQs but also by providing detailed explanations.
期刊介绍:
The Turkish Journal of Ophthalmology (TJO) is the only scientific periodical publication of the Turkish Ophthalmological Association and has been published since January 1929. In its early years, the journal was published in Turkish and French. Although there were temporary interruptions in the publication of the journal due to various challenges, the Turkish Journal of Ophthalmology has been published continually from 1971 to the present. The target audience includes specialists and physicians in training in ophthalmology in all relevant disciplines.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


