Omer Kaspi, Yaniv Y Avissar, Arnon Grafit, Ron Chibel, Olga Girshevitz, Hanoch Senderowitz
{"title":"基于机器学习的石油馏分和汽油痕迹的识别,使用从收集的样品中测量和合成GC光谱。","authors":"Omer Kaspi, Yaniv Y Avissar, Arnon Grafit, Ron Chibel, Olga Girshevitz, Hanoch Senderowitz","doi":"10.1002/minf.70008","DOIUrl":null,"url":null,"abstract":"<p><p>Ignition cases involving arsons are typically handled by forensic experts who examine spectra of samples collected from scenes of fire to test for the existence or absence of ignitable liquids. This is tedious work, since many cases do not involve such liquids. To facilitate this process, we have developed in this work a Machine Learning (ML)-based workflow for samples' classification based on their gas chromatography (GC) chromatograms (i.e., spectra). To this end, annotated spectra of 181 samples containing three groups of liquids (petroleum distillates, gasoline, and an assortment of other substances) collected from fire scenes as well as two reference databases were obtained from the Israeli Department of Identification and Forensic Sciences (DIFS). These spectra were used for the derivation of ML-based classification models using three algorithms, namely, kNN, representative spectrum, and random forest (RF) giving rise to reliable predictions. To increase the size of the dataset to a level that would enable the usage of more advanced ML algorithms, we have used the experimental spectra to develop a new spectra synthesis algorithm and utilized it to generate a large dataset of synthetic spectra. This dataset was used for the derivation of new kNN, RF, and representative spectrum models as well as deep learning (DL) models producing F1-scores over an independent test set composed entirely of \"real\" spectra ranging from 0.74-0.95, 0.86-0.95, 0.30-0.75, and 0.85-0.96 for kNN, RF, representative spectrum, and DL, respectively. Following the completion of the work, a second set of real spectra was provided to us by DIFS, and modeling it with the second set of models yielded F1-scores ranging from 0.92-0.96, 0.96-1.00, 0.71-0.82, and 0.95-0.98 for kNN, RF, representative spectrum, and DL, respectively. These results therefore suggest that for this dataset, performances depend more on the size of the dataset used for model training than on the ML algorithm. We propose that the workflow and spectra synthesis algorithm developed in this work could be readily applied to other forensic domains where samples are characterized by spectra, either solely or in combination with other parameters.</p>","PeriodicalId":18853,"journal":{"name":"Molecular Informatics","volume":"44 8","pages":"e202400371"},"PeriodicalIF":3.1000,"publicationDate":"2025-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12371388/pdf/","citationCount":"0","resultStr":"{\"title\":\"Machine Learning-Based Identification of Petroleum Distillates and Gasoline Traces Using Measured and Synthetic GC Spectra from Collected Samples.\",\"authors\":\"Omer Kaspi, Yaniv Y Avissar, Arnon Grafit, Ron Chibel, Olga Girshevitz, Hanoch Senderowitz\",\"doi\":\"10.1002/minf.70008\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Ignition cases involving arsons are typically handled by forensic experts who examine spectra of samples collected from scenes of fire to test for the existence or absence of ignitable liquids. This is tedious work, since many cases do not involve such liquids. To facilitate this process, we have developed in this work a Machine Learning (ML)-based workflow for samples' classification based on their gas chromatography (GC) chromatograms (i.e., spectra). To this end, annotated spectra of 181 samples containing three groups of liquids (petroleum distillates, gasoline, and an assortment of other substances) collected from fire scenes as well as two reference databases were obtained from the Israeli Department of Identification and Forensic Sciences (DIFS). These spectra were used for the derivation of ML-based classification models using three algorithms, namely, kNN, representative spectrum, and random forest (RF) giving rise to reliable predictions. To increase the size of the dataset to a level that would enable the usage of more advanced ML algorithms, we have used the experimental spectra to develop a new spectra synthesis algorithm and utilized it to generate a large dataset of synthetic spectra. This dataset was used for the derivation of new kNN, RF, and representative spectrum models as well as deep learning (DL) models producing F1-scores over an independent test set composed entirely of \\\"real\\\" spectra ranging from 0.74-0.95, 0.86-0.95, 0.30-0.75, and 0.85-0.96 for kNN, RF, representative spectrum, and DL, respectively. Following the completion of the work, a second set of real spectra was provided to us by DIFS, and modeling it with the second set of models yielded F1-scores ranging from 0.92-0.96, 0.96-1.00, 0.71-0.82, and 0.95-0.98 for kNN, RF, representative spectrum, and DL, respectively. These results therefore suggest that for this dataset, performances depend more on the size of the dataset used for model training than on the ML algorithm. We propose that the workflow and spectra synthesis algorithm developed in this work could be readily applied to other forensic domains where samples are characterized by spectra, either solely or in combination with other parameters.</p>\",\"PeriodicalId\":18853,\"journal\":{\"name\":\"Molecular Informatics\",\"volume\":\"44 8\",\"pages\":\"e202400371\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2025-08-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12371388/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Molecular Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1002/minf.70008\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"CHEMISTRY, MEDICINAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Molecular Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1002/minf.70008","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"CHEMISTRY, MEDICINAL","Score":null,"Total":0}
Machine Learning-Based Identification of Petroleum Distillates and Gasoline Traces Using Measured and Synthetic GC Spectra from Collected Samples.
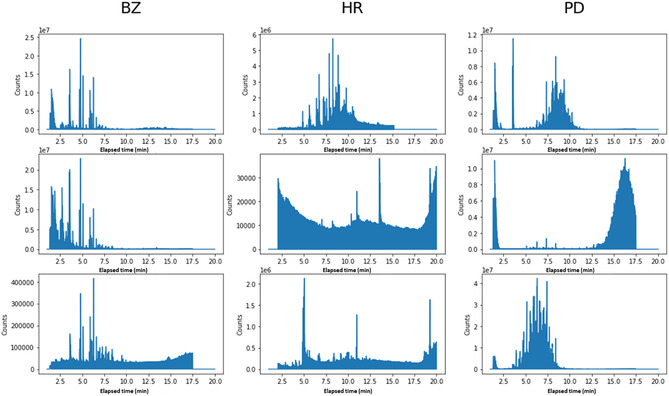
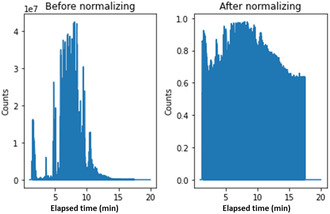
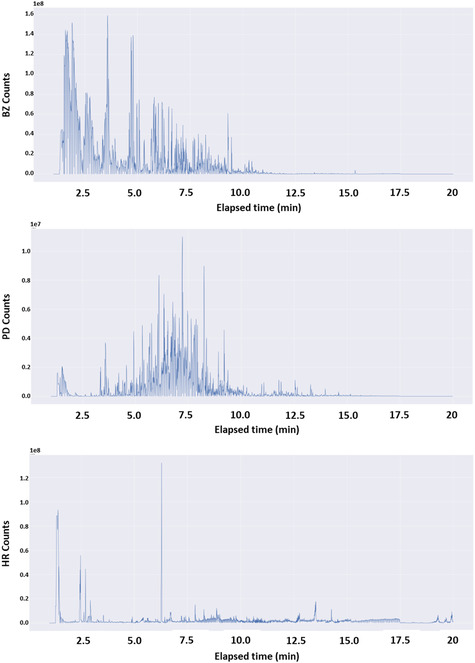
Ignition cases involving arsons are typically handled by forensic experts who examine spectra of samples collected from scenes of fire to test for the existence or absence of ignitable liquids. This is tedious work, since many cases do not involve such liquids. To facilitate this process, we have developed in this work a Machine Learning (ML)-based workflow for samples' classification based on their gas chromatography (GC) chromatograms (i.e., spectra). To this end, annotated spectra of 181 samples containing three groups of liquids (petroleum distillates, gasoline, and an assortment of other substances) collected from fire scenes as well as two reference databases were obtained from the Israeli Department of Identification and Forensic Sciences (DIFS). These spectra were used for the derivation of ML-based classification models using three algorithms, namely, kNN, representative spectrum, and random forest (RF) giving rise to reliable predictions. To increase the size of the dataset to a level that would enable the usage of more advanced ML algorithms, we have used the experimental spectra to develop a new spectra synthesis algorithm and utilized it to generate a large dataset of synthetic spectra. This dataset was used for the derivation of new kNN, RF, and representative spectrum models as well as deep learning (DL) models producing F1-scores over an independent test set composed entirely of "real" spectra ranging from 0.74-0.95, 0.86-0.95, 0.30-0.75, and 0.85-0.96 for kNN, RF, representative spectrum, and DL, respectively. Following the completion of the work, a second set of real spectra was provided to us by DIFS, and modeling it with the second set of models yielded F1-scores ranging from 0.92-0.96, 0.96-1.00, 0.71-0.82, and 0.95-0.98 for kNN, RF, representative spectrum, and DL, respectively. These results therefore suggest that for this dataset, performances depend more on the size of the dataset used for model training than on the ML algorithm. We propose that the workflow and spectra synthesis algorithm developed in this work could be readily applied to other forensic domains where samples are characterized by spectra, either solely or in combination with other parameters.
期刊介绍:
Molecular Informatics is a peer-reviewed, international forum for publication of high-quality, interdisciplinary research on all molecular aspects of bio/cheminformatics and computer-assisted molecular design. Molecular Informatics succeeded QSAR & Combinatorial Science in 2010.
Molecular Informatics presents methodological innovations that will lead to a deeper understanding of ligand-receptor interactions, macromolecular complexes, molecular networks, design concepts and processes that demonstrate how ideas and design concepts lead to molecules with a desired structure or function, preferably including experimental validation.
The journal''s scope includes but is not limited to the fields of drug discovery and chemical biology, protein and nucleic acid engineering and design, the design of nanomolecular structures, strategies for modeling of macromolecular assemblies, molecular networks and systems, pharmaco- and chemogenomics, computer-assisted screening strategies, as well as novel technologies for the de novo design of biologically active molecules. As a unique feature Molecular Informatics publishes so-called "Methods Corner" review-type articles which feature important technological concepts and advances within the scope of the journal.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


