WoundcareVQA:伤口护理的多语言视觉问答基准数据集。
IF 4.5
2区 医学
Q2 COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS
引用次数: 0
摘要
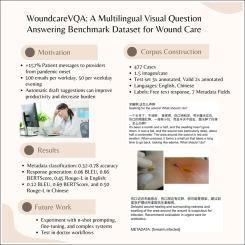
目的:介绍创伤护理多模态多语言视觉问答的任务,提供基线表现,并确定未来的研究领域。方法:利用消费者在线健康问题,建立伤口护理多模式多语言视觉问答(VQA)数据集。美国执业医生的任务是提供元数据和专家回答标签。测试了几种支持指令的多语言视觉问答模型(gpt - 40、Gemini-1.5-Pro和Qwen-VL)的基准性能。最后,根据领域专家的反应等级对自动评估进行了测试。结果:构建了一个包含477个伤口护理案例、768个回复、748张图像、3k个结构化数据标签、1362个翻译实例和10k个判断的多语言数据集(https://osf.io/xsj5u/)。根据分类类型,元数据得分的准确率范围为0.32-0.78;反应生成性能:英语为0.06 BLEU, 0.66 BERTScore, 0.45 ROUGE-L;汉语为0.12 BLEU, 0.69 BERTScore, 0.50 ROUGE-L。结论:我们构建并探索了多模态、多语言的VQA任务。我们希望本文的工作能够对伤口护理元数据分类、VQA反应生成和开放反应自动评估等方面的进一步研究提供启发。本文章由计算机程序翻译,如有差异,请以英文原文为准。
WoundcareVQA: A multilingual visual question answering benchmark dataset for wound care
Objective:
Introduce the task of wound care multimodal multilingual visual question answering, provide baseline performances, and identify areas of future study.
Methods:
A dataset of wound care multimodal multilingual visual question answering (VQA) was created using consumer health questions asked online. Practicing US medical doctors were tasked with providing metadata and expert responses labels. Several instruct-enabled, multilingual visual question answering models (GPT-4o, Gemini-1.5-Pro, and Qwen-VL) were tested to benchmark performances. Finally, automatic evaluations were tested against domain expert response ratings.
Results:
A multilingual dataset of 477 wound care cases, 768 responses, 748 images, 3k structured data labels, 1362 translation instances, and 10k judgments was constructed (https://osf.io/xsj5u/). Metadata scores ranged from 0.32–0.78 accuracy depending on classification type; response generation performances 0.06 BLEU, 0.66 BERTScore, 0.45 ROUGE-L in English and 0.12 BLEU, 0.69 BERTScore, and 0.50 ROUGE-L in Chinese.
Conclusion:
We construct and explore the tasks of multimodal, multilingual VQA. We hope the work here can inspire further research in wound care metadata classification, VQA response generation, and open response automatic evaluation.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Journal of Biomedical Informatics
医学-计算机:跨学科应用
CiteScore
8.90
自引率
6.70%
发文量
243
审稿时长
32 days
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


