{"title":"ChatGPT、Gemini和DeepSeek在急诊科使用真实对话进行非关键分诊支持的性能。","authors":"Sukyo Lee, Sumin Jung, Jong-Hak Park, Hanjin Cho, Sungwoo Moon, Sejoong Ahn","doi":"10.1186/s12873-025-01337-2","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Timely and accurate triage is crucial for the emergency department (ED) care. Recently, there has been growing interest in applying large language models (LLMs) to support triage decision-making. However, most existing studies have evaluated these models using simulated scenarios rather than real-world clinical cases. Therefore, we evaluated the performance of multiple commercial LLMs for non-critical triage support in ED using real-world clinical conversations.</p><p><strong>Methods: </strong>We retrospectively analyzed real-world triage conversations prospectively collected from three tertiary hospitals in South Korea. Multiple commercial LLMs-including OpenAI GPT-4o, GPT-4.1, O3, Google Gemini 2.0 flash, Gemini 2.5 flash, Gemini 2.5 pro, DeepSeek V3, and DeepSeek R1-were evaluated for the accuracy in triaging patient urgency based solely on unsummarized dialogue. The Korean Triage and Acuity Scale (KTAS) assigned by triage nurses was used as the gold standard for evaluating the LLM classifications. Model performance was assessed under both a zero-shot prompting condition and a few-shot prompting condition that included representative examples.</p><p><strong>Results: </strong>A total of 1,057 triage cases were included in the analysis. Among the models, Gemini 2.5 flash achieved the highest accuracy (73.8%), specificity (88.9%), and PPV (94.0%). Gemini 2.5 pro demonstrated the highest sensitivity (90.9%) and F1-score (82.4%), though with lower specificity (23.3%). GPT-4.1 also showed balanced high accuracy (70.6%) and sensitivity (81.3%) with practical response times (1.79s). Performance varied widely between models and even between different versions from the same vendor. With few-shot prompting, most models showed further improvements in accuracy and F1-score.</p><p><strong>Conclusions: </strong>LLMs can accurately triage ED patient urgency using real-world clinical conversations. Several models demonstrated both high sensitivity and acceptable response times, supporting the feasibility of LLM in non-critical triage support tools in diverse clinical environments. These findings apply to non-critical patients (KTAS 3-5), and further research should address integration with objective clinical data and real-time workflow.</p>","PeriodicalId":9002,"journal":{"name":"BMC Emergency Medicine","volume":"25 1","pages":"176"},"PeriodicalIF":2.3000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12403343/pdf/","citationCount":"0","resultStr":"{\"title\":\"Performance of ChatGPT, Gemini and DeepSeek for non-critical triage support using real-world conversations in emergency department.\",\"authors\":\"Sukyo Lee, Sumin Jung, Jong-Hak Park, Hanjin Cho, Sungwoo Moon, Sejoong Ahn\",\"doi\":\"10.1186/s12873-025-01337-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Timely and accurate triage is crucial for the emergency department (ED) care. Recently, there has been growing interest in applying large language models (LLMs) to support triage decision-making. However, most existing studies have evaluated these models using simulated scenarios rather than real-world clinical cases. Therefore, we evaluated the performance of multiple commercial LLMs for non-critical triage support in ED using real-world clinical conversations.</p><p><strong>Methods: </strong>We retrospectively analyzed real-world triage conversations prospectively collected from three tertiary hospitals in South Korea. Multiple commercial LLMs-including OpenAI GPT-4o, GPT-4.1, O3, Google Gemini 2.0 flash, Gemini 2.5 flash, Gemini 2.5 pro, DeepSeek V3, and DeepSeek R1-were evaluated for the accuracy in triaging patient urgency based solely on unsummarized dialogue. The Korean Triage and Acuity Scale (KTAS) assigned by triage nurses was used as the gold standard for evaluating the LLM classifications. Model performance was assessed under both a zero-shot prompting condition and a few-shot prompting condition that included representative examples.</p><p><strong>Results: </strong>A total of 1,057 triage cases were included in the analysis. Among the models, Gemini 2.5 flash achieved the highest accuracy (73.8%), specificity (88.9%), and PPV (94.0%). Gemini 2.5 pro demonstrated the highest sensitivity (90.9%) and F1-score (82.4%), though with lower specificity (23.3%). GPT-4.1 also showed balanced high accuracy (70.6%) and sensitivity (81.3%) with practical response times (1.79s). Performance varied widely between models and even between different versions from the same vendor. With few-shot prompting, most models showed further improvements in accuracy and F1-score.</p><p><strong>Conclusions: </strong>LLMs can accurately triage ED patient urgency using real-world clinical conversations. Several models demonstrated both high sensitivity and acceptable response times, supporting the feasibility of LLM in non-critical triage support tools in diverse clinical environments. These findings apply to non-critical patients (KTAS 3-5), and further research should address integration with objective clinical data and real-time workflow.</p>\",\"PeriodicalId\":9002,\"journal\":{\"name\":\"BMC Emergency Medicine\",\"volume\":\"25 1\",\"pages\":\"176\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2025-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12403343/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMC Emergency Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1186/s12873-025-01337-2\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"EMERGENCY MEDICINE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Emergency Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s12873-025-01337-2","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"EMERGENCY MEDICINE","Score":null,"Total":0}
Performance of ChatGPT, Gemini and DeepSeek for non-critical triage support using real-world conversations in emergency department.
Background: Timely and accurate triage is crucial for the emergency department (ED) care. Recently, there has been growing interest in applying large language models (LLMs) to support triage decision-making. However, most existing studies have evaluated these models using simulated scenarios rather than real-world clinical cases. Therefore, we evaluated the performance of multiple commercial LLMs for non-critical triage support in ED using real-world clinical conversations.
Methods: We retrospectively analyzed real-world triage conversations prospectively collected from three tertiary hospitals in South Korea. Multiple commercial LLMs-including OpenAI GPT-4o, GPT-4.1, O3, Google Gemini 2.0 flash, Gemini 2.5 flash, Gemini 2.5 pro, DeepSeek V3, and DeepSeek R1-were evaluated for the accuracy in triaging patient urgency based solely on unsummarized dialogue. The Korean Triage and Acuity Scale (KTAS) assigned by triage nurses was used as the gold standard for evaluating the LLM classifications. Model performance was assessed under both a zero-shot prompting condition and a few-shot prompting condition that included representative examples.
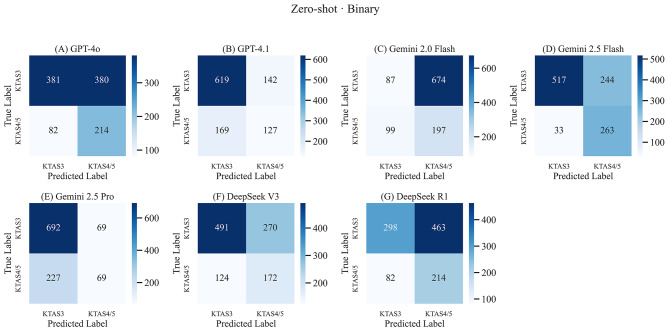
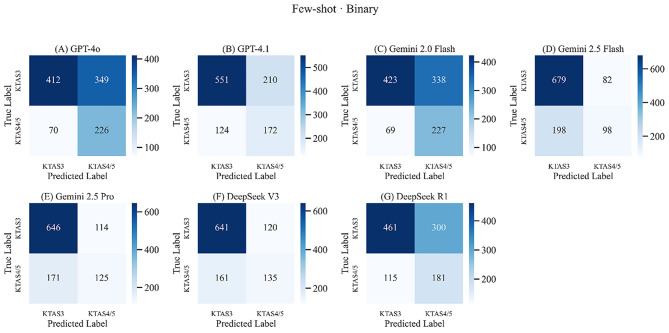
Results: A total of 1,057 triage cases were included in the analysis. Among the models, Gemini 2.5 flash achieved the highest accuracy (73.8%), specificity (88.9%), and PPV (94.0%). Gemini 2.5 pro demonstrated the highest sensitivity (90.9%) and F1-score (82.4%), though with lower specificity (23.3%). GPT-4.1 also showed balanced high accuracy (70.6%) and sensitivity (81.3%) with practical response times (1.79s). Performance varied widely between models and even between different versions from the same vendor. With few-shot prompting, most models showed further improvements in accuracy and F1-score.
Conclusions: LLMs can accurately triage ED patient urgency using real-world clinical conversations. Several models demonstrated both high sensitivity and acceptable response times, supporting the feasibility of LLM in non-critical triage support tools in diverse clinical environments. These findings apply to non-critical patients (KTAS 3-5), and further research should address integration with objective clinical data and real-time workflow.
期刊介绍:
BMC Emergency Medicine is an open access, peer-reviewed journal that considers articles on all urgent and emergency aspects of medicine, in both practice and basic research. In addition, the journal covers aspects of disaster medicine and medicine in special locations, such as conflict areas and military medicine, together with articles concerning healthcare services in the emergency departments.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


