MLSPred-bench:将脑电图(EEG)数据集转换为机器学习就绪的癫痫发作预测基准
IF 1.9
Q2 MULTIDISCIPLINARY SCIENCES
引用次数: 0
摘要
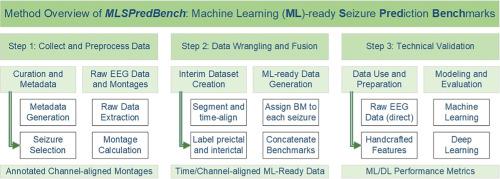
与癫痫发作检测相比,预测癫痫发作是一项更具挑战性的任务。然而,大多数公开可用的脑电图(EEG)数据集都是面向检测的,因为初始阶段(主要症状期)是有注释的。相反,预测需要有注释的预测阶段和间隔阶段。为此,我们设计并开发了一种名为MLSPred-Bench的方法,可以将任何标注用于检测的脑电大数据转换为适合预测的ML-ready数据。我们将我们的方法应用于现有的EEG数据语料库,以生成12个ml就绪的基准,包括用于训练、验证和测试癫痫发作预测模型的数据。我们的策略使用不同的癫痫发作预测范围(SPH)和癫痫发作发生周期(SOP)来生成150GB的ml就绪数据。为了说明生成数据的有用性,我们使用多个机器学习(ML)和深度学习(DL)模型在技术上验证了所有基准。我们希望生成的基准数据将被各种计算组用于他们的癫痫预测模型开发。工作总结如下:1。从长时间的标注脑电图蒙太奇中提取短的前间隔段和间隔段。生成具有不同SPH和sop的ml就绪基准的全面列表。从技术上用多个ML和DL模型验证生成的数据,验证准确率高达88.73% 4。开源代码和相关资料可在https://github.com/pcdslab/MLSPred-Bench上获得。本文章由计算机程序翻译,如有差异,请以英文原文为准。
MLSPred-bench: Transforming electroencephalography (EEG) datasets into machine learning-ready epileptic seizure prediction benchmarks
Predicting epileptic seizures is a significantly more challenging task compared to seizure detection. However, most publicly available electroencephalography (EEG) datasets are geared towards detection because the ictal phase (main symptomatic period) is annotated. In contrast, prediction requires the availability of annotated preictal and interictal phases. To this end, we designed and developed a method called MLSPred-Bench that can be used for converting any EEG big data annotated for detection into ML-ready data suitable for prediction. We apply our methods to the existing EEG data corpus to generate 12 ML-ready benchmarks comprising data for training, validating, and testing seizure prediction models. Our strategy uses different variations of seizure prediction horizon (SPH) and the seizure occurrence period (SOP) to produce >150GB of ML-ready data. To illustrate the usefulness of the generated data, we technically validate all the benchmarks using multiple machine learning (ML) and deep learning (DL) models. We hope that the generated benchmarking data will be utilized by various computational groups for their seizure prediction model development.
The work can be summarized as follows:
- 1.Extract short preictal and interictal segments from long-duration annotated EEG montages.
- 2.Generate a comprehensive list of ML-ready benchmarks with varying SPH and SOP.
- 3.Technically validate the generated data with multiple ML and DL models with up-to 88.73 % validation accuracy
- 4.Opensource code and related materials are available at https://github.com/pcdslab/MLSPred-Bench.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

MethodsX
Health Professions-Medical Laboratory Technology
CiteScore
3.60
自引率
5.30%
发文量
314
审稿时长
7 weeks
期刊介绍:
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


