非结构地形下两足轮式机器人多运动技能的模仿约束进化学习
IF 8
2区 计算机科学
Q1 AUTOMATION & CONTROL SYSTEMS
Engineering Applications of Artificial Intelligence
Pub Date : 2025-08-25
DOI:10.1016/j.engappai.2025.112079
引用次数: 0
摘要
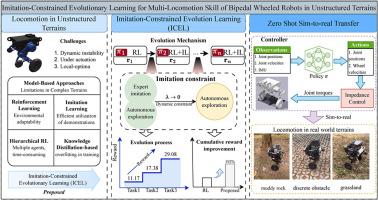
两足轮式机器人由于其固有的动力不稳定性和欠驱动特性,在非结构化地形中提出了重大的运动挑战。虽然强化学习为移动性增强提供了有希望的解决方案,但在策略优化中实现多技能泛化和避免局部最优仍然是一个问题。本文提出了一个模仿约束的进化强化学习框架,将多动作技能习得作为一个进化过程重新表述。该方法的特点是:(1)具有简化奖励函数的任务特定子策略,以确保局部最优性;(2)优化的子策略作为专家模型的专家-学生架构;(3)动态模仿约束强化学习策略,在新任务学习过程中实现渐进式技能继承。该进化机制保证了单个智能体学习多运动技能的全局最优性。实验验证表明,与端到端学习范式相比,累积奖励提高了192%。通过动态参数随机化,将控制策略成功地应用于物理原型上,实现了在泥泞岩石、草地和离散障碍地形上的多模式自适应零射击模拟到真实的转移。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Imitation-constrained evolutionary learning for multi-locomotion skill of bipedal wheeled robots in unstructured terrains
Bipedal wheeled robots present significant locomotion challenges in unstructured terrains due to inherent dynamic instability and under-actuation characteristics. While reinforcement learning offers promising solutions for mobility enhancement, achieving multi-skill generalization and avoiding local optima in policy optimization remains problematic. This paper proposes an imitation-constrained evolutionary reinforcement learning framework that reformulates multi-locomotion skill acquisition as an evolutionary process. The methodology is characterized by: (1) Task-specific sub-policies with simplified reward functions ensuring local optimality, (2) Expert-student architecture where optimized sub-policies serve as expert models, and (3) Dynamic imitation-constrained Reinforcement Learning strategy enabling progressive skill inheritance during new task learning. The evolutionary mechanism guarantees global optimality of multi-locomotion skill learning through a single agent. Experimental validation demonstrates 192 % cumulative reward improvement compared to end-to-end learning paradigms. Through dynamic parameter randomization, the control strategy was successfully implemented on physical prototypes, achieving zero-shot sim-to-real transfer with multimodal adaptation across muddy rock, grassland, and discrete obstacle terrains.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Engineering Applications of Artificial Intelligence
工程技术-工程:电子与电气
CiteScore
9.60
自引率
10.00%
发文量
505
审稿时长
68 days
期刊介绍:
Artificial Intelligence (AI) is pivotal in driving the fourth industrial revolution, witnessing remarkable advancements across various machine learning methodologies. AI techniques have become indispensable tools for practicing engineers, enabling them to tackle previously insurmountable challenges. Engineering Applications of Artificial Intelligence serves as a global platform for the swift dissemination of research elucidating the practical application of AI methods across all engineering disciplines. Submitted papers are expected to present novel aspects of AI utilized in real-world engineering applications, validated using publicly available datasets to ensure the replicability of research outcomes. Join us in exploring the transformative potential of AI in engineering.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


