基于clip的图像-文本匹配知识投影仪
IF 6.9
1区 管理学
Q1 COMPUTER SCIENCE, INFORMATION SYSTEMS
引用次数: 0
摘要
图像-文本匹配是多媒体研究中的一个重要研究领域。然而,图像通常包含比文本更丰富的信息,并且仅用一个向量表示图像可能会受到限制,无法完全捕获其语义,从而导致跨模态匹配任务中的次优性能。为了解决这一限制,我们提出了一个基于clip的知识投影网络,该网络将图像编码为一组嵌入。这些嵌入捕获图像的不同语义,由来自大型视觉语言预训练模型CLIP(对比语言-图像预训练)的先验知识指导。为了确保生成的槽位特征与全局语义保持一致,我们设计了一个自适应加权融合模块,将全局特征融合到槽位表示中。在测试阶段,与现有的细粒度图像-文本匹配方法相比,我们提出了一种有效且可解释的相似度计算方法。实验结果证明了该框架的有效性,与MSCOCO和Flickr30K数据集上的CLIP相比,R@1在图像检索任务上的性能提高了至少7%。本文章由计算机程序翻译,如有差异,请以英文原文为准。
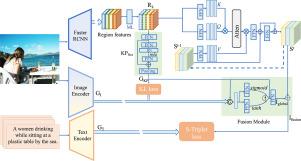
CLIP-based knowledge projector for image–text matching
Image–text matching is an essential research area within multimedia research. However, images often contain richer information than text, and representing an image with only one vector can be limited to fully capture its semantics, leading to suboptimal performance in cross-modal matching tasks. To address this limitation, we propose a CLIP-based knowledge projector network that encodes an image into a set of embeddings. These embeddings capture different semantics of an image, guided by prior knowledge from the large vision-language pretrained model CLIP(Contrastive Language-Image Pre-Training). To ensure that the generated slot features stay aligned with global semantics, we design an adaptive weighted fusion module that incorporates global features into slot representations. During the test phase, we present an effective and explainable similarity calculation method compared with existing fine-grained image–text matching methods. The proposed framework’s effectiveness is evidenced by the experimental results, with performance improvements of at least 7% in R@1 on image retrieval tasks compared to CLIP on the MSCOCO and Flickr30K datasets.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Information Processing & Management
工程技术-计算机:信息系统
CiteScore
17.00
自引率
11.60%
发文量
276
审稿时长
39 days
期刊介绍:
Information Processing and Management is dedicated to publishing cutting-edge original research at the convergence of computing and information science. Our scope encompasses theory, methods, and applications across various domains, including advertising, business, health, information science, information technology marketing, and social computing.
We aim to cater to the interests of both primary researchers and practitioners by offering an effective platform for the timely dissemination of advanced and topical issues in this interdisciplinary field. The journal places particular emphasis on original research articles, research survey articles, research method articles, and articles addressing critical applications of research. Join us in advancing knowledge and innovation at the intersection of computing and information science.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


