{"title":"基于情境学习的电子病历污名化语言有效检测:比较分析与验证研究。","authors":"Hongbo Chen, Myrtede Alfred, Eldan Cohen","doi":"10.2196/68955","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The presence of stigmatizing language within electronic health records (EHRs) poses significant risks to patient care by perpetuating biases. While numerous studies have explored the use of supervised machine learning models to detect stigmatizing language automatically, these models require large, annotated datasets, which may not always be readily available. In-context learning (ICL) has emerged as a data-efficient alternative, allowing large language models to adapt to tasks using only instructions and examples.</p><p><strong>Objective: </strong>We aimed to investigate the efficacy of ICL in detecting stigmatizing language within EHRs under data-scarce conditions.</p><p><strong>Methods: </strong>We analyzed 5043 sentences from the Medical Information Mart for Intensive Care-IV dataset, which contains EHRs from patients admitted to the emergency department at the Beth Israel Deaconess Medical Center. We compared ICL with zero-shot (textual entailment), few-shot (SetFit), and supervised fine-tuning approaches. The ICL approach used 4 prompting strategies: generic, chain of thought, clue and reasoning prompting, and a newly introduced stigma detection guided prompt. Model fairness was evaluated using the equal performance criterion, measuring true positive rate, false positive rate, and F<sub>1</sub>-score disparities across protected attributes, including sex, age, and race.</p><p><strong>Results: </strong>In the zero-shot setting, the best-performing ICL model, GEMMA-2, achieved a mean F<sub>1</sub>-score of 0.858 (95% CI 0.854-0.862), showing an 18.7% improvement over the best textual entailment model, DEBERTA-M (mean F<sub>1</sub>-score 0.723, 95% CI 0.718-0.728; P<.001). In the few-shot setting, the top ICL model, LLAMA-3, outperformed the leading SetFit models by 21.2%, 21.4%, and 12.3% with 4, 8, and 16 annotations per class, respectively (P<.001). Using 32 labeled instances, the best ICL model achieved a mean F<sub>1</sub>-score of 0.901 (95% CI 0.895-0.907), only 3.2% lower than the best supervised fine-tuning model, ROBERTA (mean F<sub>1</sub>-score 0.931, 95% CI 0.924-0.938), which was trained on 3543 labeled instances. Under the conditions tested, fairness evaluation revealed that supervised fine-tuning models exhibited greater bias compared with ICL models in the zero-shot, 4-shot, 8-shot, and 16-shot settings, as measured by true positive rate, false positive rate, and F<sub>1</sub>-score disparities.</p><p><strong>Conclusions: </strong>ICL offers a robust and flexible solution for detecting stigmatizing language in EHRs, offering a more data-efficient and equitable alternative to conventional machine learning methods. These findings suggest that ICL could enhance bias detection in clinical documentation while reducing the reliance on extensive labeled datasets.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e68955"},"PeriodicalIF":3.8000,"publicationDate":"2025-08-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12402740/pdf/","citationCount":"0","resultStr":"{\"title\":\"Efficient Detection of Stigmatizing Language in Electronic Health Records via In-Context Learning: Comparative Analysis and Validation Study.\",\"authors\":\"Hongbo Chen, Myrtede Alfred, Eldan Cohen\",\"doi\":\"10.2196/68955\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The presence of stigmatizing language within electronic health records (EHRs) poses significant risks to patient care by perpetuating biases. While numerous studies have explored the use of supervised machine learning models to detect stigmatizing language automatically, these models require large, annotated datasets, which may not always be readily available. In-context learning (ICL) has emerged as a data-efficient alternative, allowing large language models to adapt to tasks using only instructions and examples.</p><p><strong>Objective: </strong>We aimed to investigate the efficacy of ICL in detecting stigmatizing language within EHRs under data-scarce conditions.</p><p><strong>Methods: </strong>We analyzed 5043 sentences from the Medical Information Mart for Intensive Care-IV dataset, which contains EHRs from patients admitted to the emergency department at the Beth Israel Deaconess Medical Center. We compared ICL with zero-shot (textual entailment), few-shot (SetFit), and supervised fine-tuning approaches. The ICL approach used 4 prompting strategies: generic, chain of thought, clue and reasoning prompting, and a newly introduced stigma detection guided prompt. Model fairness was evaluated using the equal performance criterion, measuring true positive rate, false positive rate, and F<sub>1</sub>-score disparities across protected attributes, including sex, age, and race.</p><p><strong>Results: </strong>In the zero-shot setting, the best-performing ICL model, GEMMA-2, achieved a mean F<sub>1</sub>-score of 0.858 (95% CI 0.854-0.862), showing an 18.7% improvement over the best textual entailment model, DEBERTA-M (mean F<sub>1</sub>-score 0.723, 95% CI 0.718-0.728; P<.001). In the few-shot setting, the top ICL model, LLAMA-3, outperformed the leading SetFit models by 21.2%, 21.4%, and 12.3% with 4, 8, and 16 annotations per class, respectively (P<.001). Using 32 labeled instances, the best ICL model achieved a mean F<sub>1</sub>-score of 0.901 (95% CI 0.895-0.907), only 3.2% lower than the best supervised fine-tuning model, ROBERTA (mean F<sub>1</sub>-score 0.931, 95% CI 0.924-0.938), which was trained on 3543 labeled instances. Under the conditions tested, fairness evaluation revealed that supervised fine-tuning models exhibited greater bias compared with ICL models in the zero-shot, 4-shot, 8-shot, and 16-shot settings, as measured by true positive rate, false positive rate, and F<sub>1</sub>-score disparities.</p><p><strong>Conclusions: </strong>ICL offers a robust and flexible solution for detecting stigmatizing language in EHRs, offering a more data-efficient and equitable alternative to conventional machine learning methods. These findings suggest that ICL could enhance bias detection in clinical documentation while reducing the reliance on extensive labeled datasets.</p>\",\"PeriodicalId\":56334,\"journal\":{\"name\":\"JMIR Medical Informatics\",\"volume\":\"13 \",\"pages\":\"e68955\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2025-08-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12402740/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Medical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.2196/68955\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/68955","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
摘要
背景:电子健康记录(EHRs)中存在的污名化语言通过延续偏见对患者护理构成重大风险。虽然许多研究已经探索了使用监督机器学习模型来自动检测污名化语言,但这些模型需要大型的、带注释的数据集,而这些数据集可能并不总是现成的。上下文学习(ICL)已经成为一种数据高效的替代方法,允许大型语言模型仅使用指令和示例来适应任务。目的:探讨ICL在数据匮乏条件下对电子病历中污名化语言的检测效果。方法:我们分析了重症监护医疗信息市场- iv数据集中的5043个句子,该数据集包含贝斯以色列女执事医疗中心急诊科收治的患者的电子病历。我们将ICL与零镜头(文本蕴涵)、少镜头(SetFit)和监督微调方法进行了比较。ICL方法使用了4种提示策略:通用提示、思维链提示、线索和推理提示以及新引入的耻辱检测引导提示。模型公平性采用平等绩效标准进行评估,测量真阳性率、假阳性率和f1分数在受保护属性(包括性别、年龄和种族)之间的差异。结果:在零采样设置中,表现最好的ICL模型GEMMA-2的平均f1得分为0.858 (95% CI 0.854-0.862),比最佳文本蕴意模型DEBERTA-M(平均f1得分0.723,95% CI 0.718-0.728; p1得分0.901 (95% CI 0.895-0.907)提高了18.7%,仅比最佳监督精细调节模型ROBERTA(平均f1得分0.931,95% CI 0.924-0.938)低3.2%,后者在3543个标记实例上进行了训练。在测试条件下,公平评估显示,在真阳性率、假阳性率和f1得分差异方面,监督微调模型在0次、4次、8次和16次设置下比ICL模型表现出更大的偏差。结论:ICL为检测电子病历中的污名化语言提供了一种强大而灵活的解决方案,为传统的机器学习方法提供了一种数据效率更高、更公平的替代方案。这些发现表明,ICL可以增强临床文献中的偏倚检测,同时减少对大量标记数据集的依赖。
Efficient Detection of Stigmatizing Language in Electronic Health Records via In-Context Learning: Comparative Analysis and Validation Study.
Background: The presence of stigmatizing language within electronic health records (EHRs) poses significant risks to patient care by perpetuating biases. While numerous studies have explored the use of supervised machine learning models to detect stigmatizing language automatically, these models require large, annotated datasets, which may not always be readily available. In-context learning (ICL) has emerged as a data-efficient alternative, allowing large language models to adapt to tasks using only instructions and examples.
Objective: We aimed to investigate the efficacy of ICL in detecting stigmatizing language within EHRs under data-scarce conditions.
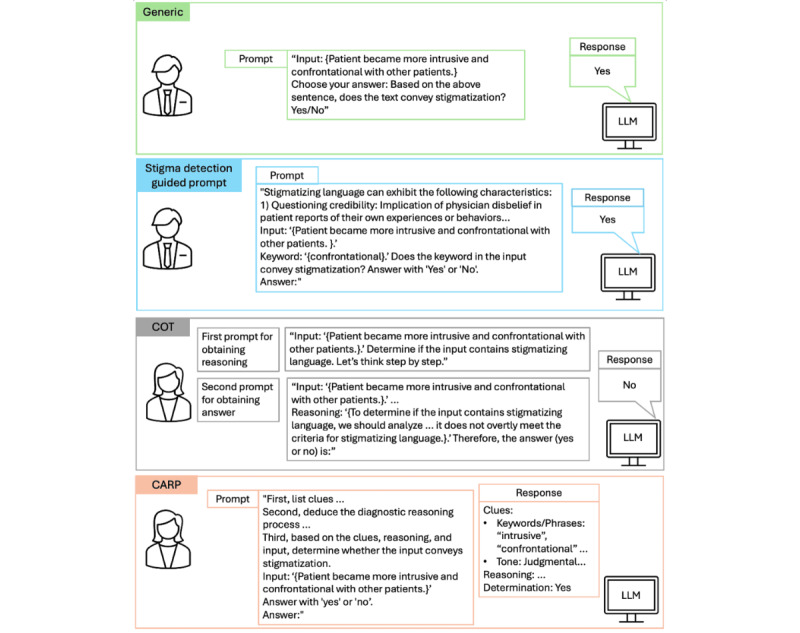
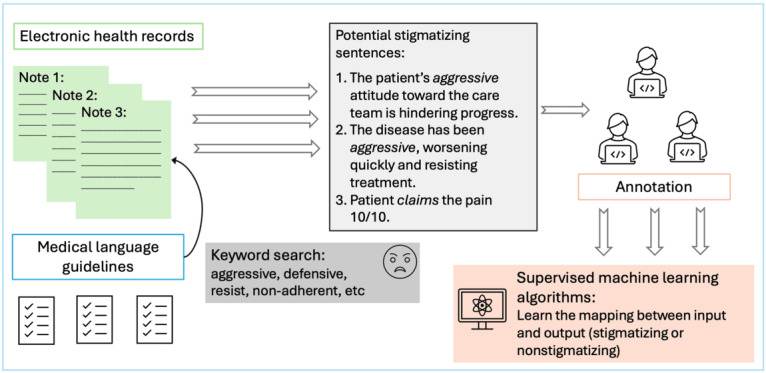
Methods: We analyzed 5043 sentences from the Medical Information Mart for Intensive Care-IV dataset, which contains EHRs from patients admitted to the emergency department at the Beth Israel Deaconess Medical Center. We compared ICL with zero-shot (textual entailment), few-shot (SetFit), and supervised fine-tuning approaches. The ICL approach used 4 prompting strategies: generic, chain of thought, clue and reasoning prompting, and a newly introduced stigma detection guided prompt. Model fairness was evaluated using the equal performance criterion, measuring true positive rate, false positive rate, and F1-score disparities across protected attributes, including sex, age, and race.
Results: In the zero-shot setting, the best-performing ICL model, GEMMA-2, achieved a mean F1-score of 0.858 (95% CI 0.854-0.862), showing an 18.7% improvement over the best textual entailment model, DEBERTA-M (mean F1-score 0.723, 95% CI 0.718-0.728; P<.001). In the few-shot setting, the top ICL model, LLAMA-3, outperformed the leading SetFit models by 21.2%, 21.4%, and 12.3% with 4, 8, and 16 annotations per class, respectively (P<.001). Using 32 labeled instances, the best ICL model achieved a mean F1-score of 0.901 (95% CI 0.895-0.907), only 3.2% lower than the best supervised fine-tuning model, ROBERTA (mean F1-score 0.931, 95% CI 0.924-0.938), which was trained on 3543 labeled instances. Under the conditions tested, fairness evaluation revealed that supervised fine-tuning models exhibited greater bias compared with ICL models in the zero-shot, 4-shot, 8-shot, and 16-shot settings, as measured by true positive rate, false positive rate, and F1-score disparities.
Conclusions: ICL offers a robust and flexible solution for detecting stigmatizing language in EHRs, offering a more data-efficient and equitable alternative to conventional machine learning methods. These findings suggest that ICL could enhance bias detection in clinical documentation while reducing the reliance on extensive labeled datasets.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


